
第二部分 Kubernetes快速入门
kubernetes是实现云原生的重要基础设施,在本章节我们将快速学习Kubernetes常用的概念与命令.通过此章节,我们可以了解Kubernetes的核心概念,并且能熟练部署Pod,在Kubernetes中部署自己的pod
第一章 Kubernetes介绍
1. 什么是Kubernetes

自容器诞生以后,随之而来的就是容器自动化与无人化,我们简单介绍一下比较有名的编排工具
Docker Swarm
Docker Swarm是Docker的原生编排工具,用于跨多个主机进行容器编排.项目核心设计是将几台安装Docker的服务器组合成一个大的集群.在Docker1.12.0版本以前 Docker Swarm是独立的产品,在Docker1.12.0以后的版本,已经集成在Docker引擎汇总,Docker Swarm与Kubernetes一样都是使用YAML配置文件,Docker Swarm是Docker Datacenter这个更大产品中的一部分.
Kubernetes
Kubernetes,又称k8s,因为有是一个编排容器的工具,其实也是管理应用的全生命周期的一个工具,从创建应用,应用的部署,应用提供服务,扩容缩容应用,应用更新,都非常的方便,而且可以做到故障自愈,例如一个服务器挂了,可以自动将这个服务重新启动将该服务调度到另外一个主机上进行运行,无需进行人工干涉。Kubernetes屏蔽了硬件层的资源,对资源进行了更高级的抽象.
2. 为什么要使用Kubernetes
主要有以下有基点:
- 自动化容器的部署和复制
- 随时扩展或收缩容器规模
- 将容器组织成组,并且提供容器间的负载均衡
- 很容易地升级应用程序容器的新版本,并且也易于版本回退
- 提供容器弹性,如果容器失效就替换它
- 简化运维操作,屏蔽底层的复杂操作
3. 整体架构
首先我们看一下Kubernetes的整体架构图
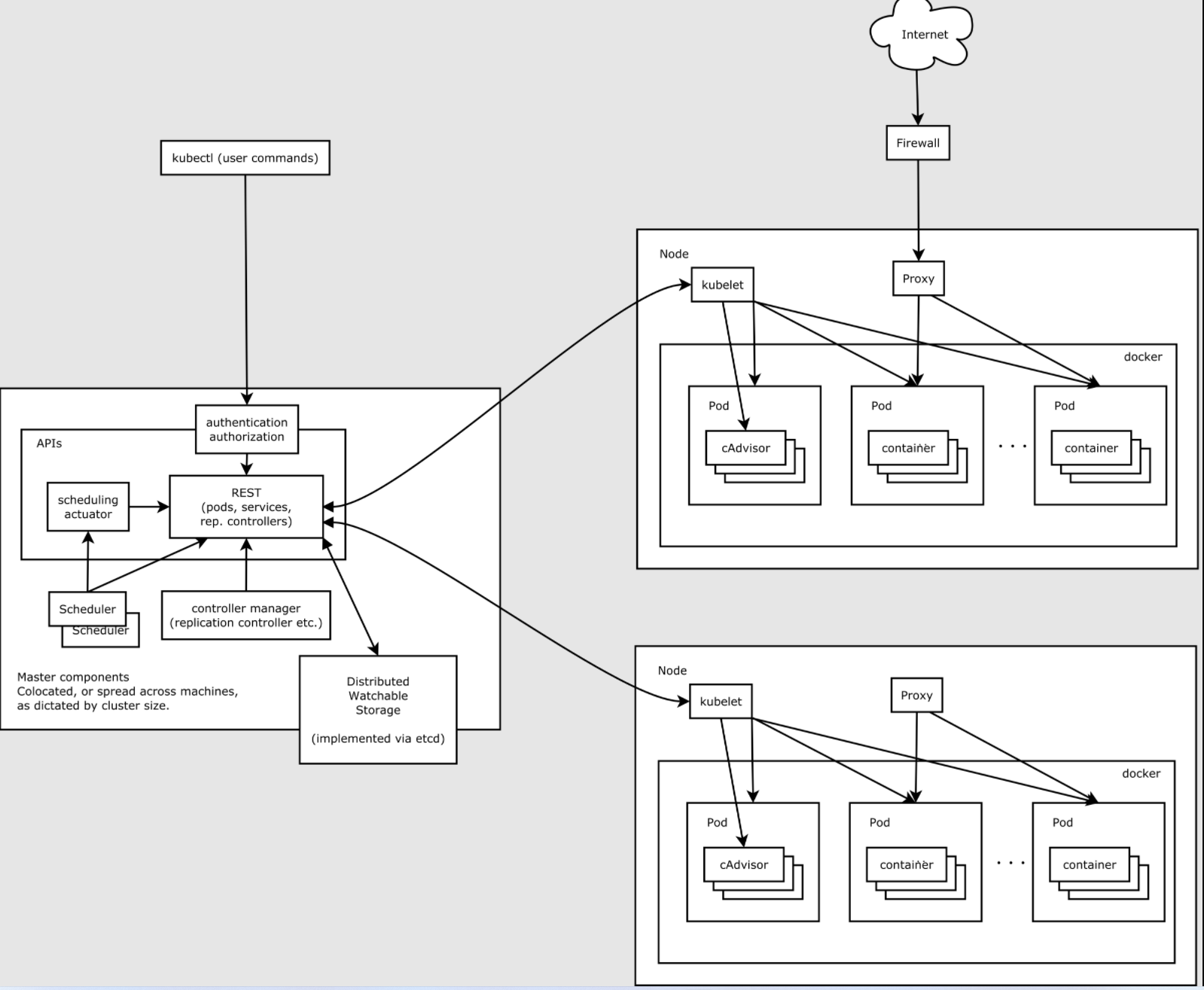
从上可以看到Kubernetes的构成主要是Master节点与Node节点.然后和一些组件,下面我们将一一介绍
kubectl
kubectl是用户使用的指令工具,用来管理Kubernetes集群的,kubectl将用户的指令发送到Master节点上的API Server
Master节点
Master是Kubernetes集群的主节点,是核心服务所在的机器.Master节点收到用户使用kubectl发送的指令后, 将命令发送到Node节点的kubelet服务,kubelet服务负责执行相应的指令,一般Master节点是不参与到集群工作中的,当然也可以通过一些手段才让Master节点参与到工作中.
Node节点
Node是Kubernetes的工作节点,您可以理解为是一台宿主机
API Server
该组件位于Master节点上主节点上负责提供 Kubernetes API 服务的组件;它是 Kubernetes 控制面的前端。kube-apiserver 在设计上考虑了水平扩缩的需要。 我们通过部署多个实例可以实现集群的高可用
Scheduler
Scheduler是集群的默认调度器,Scheduler通过kubernetes的监测机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。 Scheduler会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。 Scheduler会依据下文的调度原则来做出调度选择。如果没有合适的节点,则将Pod置于挂起状态,直到出现合适的节点
Controller-Manager
Controller-Manager作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller-Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
ETCD
是Kubernetes提供默认的存储系统,保存所有集群数据.当然该组件可以部署到另外的机器上.我们经常所说的Kubernetes的高可用,本质就是ETCD的高可用
Node节点
Node是Pod真正运行的主机,可以物理机,也可以是虚拟机。为了管理Pod,每个Node节点上至少要运行Container Runtime(比如docker)、kubelet和kube-proxy服务。业务容器都会部署到该节点上.在此节点上,我们可以依然使用Docker的相关命令来查看,已经存在的镜像与容器.
1) kubelet
每个Node节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 Master 发来的指令,管理 Pod 及 Pod 中的容器。每个Kubelet进程会向 API Server 注册所在Node节点的信息,定期向 **Master **节点汇报该节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源。kubelet需要随机启动.
2) kube-proxy
kube-proxy确保每个节点都获得其IP地址,实现本地iptables和规则以处理路由和流量负载均衡。
第二章 部署Kubernetes集群
1. 服务器规划
在本章节,我将使用虚拟机部署一套Kubernetes集群,服务器规划如下,服务器IP根据实际情况进行配置
| 系统 | 节点 | 用途 | IP | 规格 |
|---|---|---|---|---|
| centos8 | master | 主节点 | 192.168.137.46 | 2核,2G |
| centos8 | node1 | 工作节点 | 192.168.137.147 | 2核,2G |
| centos8 | node2 | 工作节点 | 192.168.137.18 | 2核,2G |
2. 安装虚拟机与Docker
可以参考第一部分 Docker快速入门
3. 系统设置
虚拟机与Docker安装完毕后,需要一定的系统设置
- 将所有虚拟机设置静态IP,使用以下命令进行设置
#1 编辑以下路径文件 vi /etc/sysconfig/network-scripts/ifcfg-eth0 #2 改为以下内容 如果不存在则添加 BOOTPROTO="static" ONBOOT="yes" IPADDR="192.168.137.46" GATEWAY="192.168.137.1" DNS1="192.168.137.1" NETMASK="255.255.255.0"1
2
3
4
5
6
7
8
9
10
- 所有虚拟机需要设置hosts
#编辑以下路径文件 vi /etc/hosts #填写以下内容 192.168.137.147 node1 192.168.137.18 node2 192.168.137.46 master1
2
3
4
5
6
- 所有虚拟机关闭防火墙
#使用以下命令 systemctl stop firewalld && systemctl disable firewalld1
2
- 所有虚拟机关闭swap与SELinux
#分别使用以下命令进行关闭 sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab swapoff -a setenforce 01
2
3
4
5
- 所有虚拟机配置Docker
#编辑以下文件 vi /etc/docker/daemon.json #填写以下内容 { "registry-mirrors": ["这里填写加速源地址"], "exec-opts": ["native.cgroupdriver=systemd"] } #保存文件后,需要重启docker systemctl restart docker1
2
3
4
5
6
7
8
9
10
4. 安装
- 所有虚拟机创建安装源
#由于Kubernetes官方安装源在Google服务器,所以我们使用阿里云的安装源 #编辑以下文件 vi /etc/yum.repos.d/kubernetes.repo #填写以下内容 [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg1
2
3
4
5
6
7
8
9
10
11
- 安装
#在master节点执行以下命令 yum install -y kubectl kubelet kubeadm #在node节点执行以下命令 yum install -y kubelet kubeadm #在所有节点设置kubelet随机启动并随机启动 systemctl enable kubelet --now1
2
3
4
5
6
7
8
- 初始化master节点
#首先在master节点确认kubectl的版本 kubectl version [root@master ~]# kubectl version Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:41:01Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}1
2
3
4
5#在master节点上执行以下命令,该命令的意思是使用阿里云的镜像初始化最新版本的kubernetes,指定版本与kubectl的版本一致,所有的设置指令使用默认,将安装日志写到当前目录的init.log中 #kubeadm为集群的初始化命令, kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.23.1 | tee init.log1
2
3
4提示安装成功
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.137.46:6443 --token ut40xz.kghms83ni0ubarbt \ --discovery-token-ca-cert-hash sha256:743b7018266c00ac095426a67fba9b090bf5ec080758538992ecfa485d724f041
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20其中有2个注意的地方
#1. 在master节点需要执行以下这个命令,这是kubctl与api server通讯的认证,如果忘记了,可以在刚刚保存在的init.log中查看,如果您在别的机器上(比如A)安装了kubectl组件的话,可以在该机器(A)上执行以下命令,这样这台机器(A)就具有访问了api server的能力,当然前台是网络是能通的 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config #2. 当执行完以上命令的时候,可以看到客户端与服务端的版本 [root@master ~]# kubectl version Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:41:01Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:34:54Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"} #3. node节点加入集群使用以下命令,但是此时node节点不要加入集群 kubeadm join 192.168.137.46:6443 --token ut40xz.kghms83ni0ubarbt \ --discovery-token-ca-cert-hash sha256:743b7018266c00ac095426a67fba9b090bf5ec080758538992ecfa485d724f041
2
3
4
5
6
7
8
9
10
11
12
13
14安装集群网络插件
# 安装 Calico kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml1
2Kubernetes支持多种的网络插件,比如Wave,Flannel等,大家可以选择任意一个网络插件安装使用.本课程主要面相的是研发人员,所以不对Kubernetes的网络做深入介绍.
至此,我的Master节点就是安装成功了.接下来让我们加入Node节点
- node节点加入集群
#在node节点使用指令加入加群
kubeadm join 192.168.137.46:6443 --token ut40xz.kghms83ni0ubarbt \
--discovery-token-ca-cert-hash sha256:743b7018266c00ac095426a67fba9b090bf5ec080758538992ecfa485d724f04
#这个时候在master节点查看,node节点的status目前处于NotReady状态,是因为节点正在下载所需要的镜像
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 133m v1.23.1
node1 NotReady <none> 23s v1.23.1
node2 NotReady <none> 16s v1.23.1
#过一段时间在看node节点状态,已经处于ready状态了
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 138m v1.23.1
node1 Ready <none> 4m53s v1.23.1
node2 Ready <none> 4m46s v1.23.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
到此为止,目前集群已经安装完毕,处于可用状态.
第三章 Pod
1. 什么是Pod
在Kubernetes集群中,Kubernetes不会直接管理容器,而是通过各种控制器来管理和规定Pod,.Pod是所有业务类型的基础,也是Kubernetes管理的最小单位级与调度单元,它是一个或多个容器的组合。pod内的容器会自动被安排到同一node节点上, 这组容器共享存储、网络和命名空间,以及如何运行的规范。在Pod中,所有容器都被同一安排和调度,并运行在共享的上下文中。通俗的来说,就是我们部署的一个应用服务就是一个或多个pod.
Pod有两个特点:
网络:每一个Pod都会被指派一个唯一的IP地址,在Pod中的每一个容器共享网络命名空间,包括IP地址和网络端口。在同一个Pod中的容器可以同locahost进行互相通信。当Pod中的容器需要与Pod外的实体进行通信时,则需要通过端口等共享的网络资源。
**存储:**Pod能够被指定共享存储卷的集合,在Pod中所有的容器能够访问共享存储卷,允许这些容器共享数据。存储卷也允许在一个Pod持久化数据,以防止其中的容器需要被重启。
Kubernetes不会直接管理容器,而是管理pod.在实际应用中通常我们不会直接创建Pod,而是通过控制器来管理和调度Pod.控制器的概念我们稍后再讲.
2. 了解kubectl
kubectl是Kubernetes自带的客户端,是管理Kubernetes集群的工具,只要在机器上安装kuebctl以后,然后复制好认证token以后,就可以远程对集群进行控制.
kubectl的常用命令如下
[root@master ~]# kubectl
kubectl controls the Kubernetes cluster manager.
Find more information at: https://kubernetes.io/docs/reference/kubectl/overview/
Basic Commands (Beginner):
create Create a resource from a file or from stdin
expose Take a replication controller, service, deployment or pod and expose it as a new Kubernetes service
run 在集群中运行一个指定的镜像
set 为 objects 设置一个指定的特征
Basic Commands (Intermediate):
explain Get documentation for a resource
get 显示一个或更多 resources
edit 在服务器上编辑一个资源
delete Delete resources by file names, stdin, resources and names, or by resources and label selector
Deploy Commands:
rollout Manage the rollout of a resource
scale Set a new size for a deployment, replica set, or replication controller
autoscale Auto-scale a deployment, replica set, stateful set, or replication controller
Cluster Management Commands:
certificate 修改 certificate 资源.
cluster-info Display cluster information
top Display resource (CPU/memory) usage
cordon 标记 node 为 unschedulable
uncordon 标记 node 为 schedulable
drain Drain node in preparation for maintenance
taint 更新一个或者多个 node 上的 taints
Troubleshooting and Debugging Commands:
describe 显示一个指定 resource 或者 group 的 resources 详情
logs 输出容器在 pod 中的日志
attach Attach 到一个运行中的 container
exec 在一个 container 中执行一个命令
port-forward Forward one or more local ports to a pod
proxy 运行一个 proxy 到 Kubernetes API server
cp Copy files and directories to and from containers
auth Inspect authorization
debug Create debugging sessions for troubleshooting workloads and nodes
Advanced Commands:
diff Diff the live version against a would-be applied version
apply Apply a configuration to a resource by file name or stdin
patch Update fields of a resource
replace Replace a resource by file name or stdin
wait Experimental: Wait for a specific condition on one or many resources
kustomize Build a kustomization target from a directory or URL.
Settings Commands:
label 更新在这个资源上的 labels
annotate 更新一个资源的注解
completion Output shell completion code for the specified shell (bash, zsh or fish)
Other Commands:
alpha Commands for features in alpha
api-resources Print the supported API resources on the server
api-versions Print the supported API versions on the server, in the form of "group/version"
config 修改 kubeconfig 文件
plugin Provides utilities for interacting with plugins
version 输出 client 和 server 的版本信息
Usage:
kubectl [flags] [options]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
3. pod基本操作
3.1 创建pod
接下来我们使用nginx镜像创建一个pod
#使用以下命令创建一个名为:nginx-pod的pod,暴漏端口为80
[root@master ~]# kubectl run nginx-pod --image=nginx --port=80
pod/nginx-pod created
#可以看见创建成功,然后在查看pod列表,-owide为可选参数,意味列出pod的详细信息
[root@master ~]# kubectl get pod -owide
2
3
4
5
6

一个简单的nginx pod就已经被创建.可以看到nginx-pod状态为ready,并且已经部署到了node1节点上,一般情况下我们部署的pod只会部署到node节点上,不会部署到master节点上,内部IP地址为172.16.166.148
创建Pod有两种方式
第一种 如上述所使用kubectl run pod名称 --image=镜像地址
我们使用kubectl run --help来查看其他选项
[root@master ~]# kubectl run --help Create and run a particular image in a pod. Examples: # Start a nginx pod kubectl run nginx --image=nginx # Start a hazelcast pod and let the container expose port 5701 kubectl run hazelcast --image=hazelcast/hazelcast --port=5701 # Start a hazelcast pod and set environment variables "DNS_DOMAIN=cluster" and "POD_NAMESPACE=default" in the container kubectl run hazelcast --image=hazelcast/hazelcast --env="DNS_DOMAIN=cluster" --env="POD_NAMESPACE=default" # Start a hazelcast pod and set labels "app=hazelcast" and "env=prod" in the container kubectl run hazelcast --image=hazelcast/hazelcast --labels="app=hazelcast,env=prod" # Dry run; print the corresponding API objects without creating them kubectl run nginx --image=nginx --dry-run=client # Start a nginx pod, but overload the spec with a partial set of values parsed from JSON kubectl run nginx --image=nginx --overrides='{ "apiVersion": "v1", "spec": { ... } }' # Start a busybox pod and keep it in the foreground, don't restart it if it exits kubectl run -i -t busybox --image=busybox --restart=Never # Start the nginx pod using the default command, but use custom arguments (arg1 .. argN) for that command kubectl run nginx --image=nginx -- <arg1> <arg2> ... <argN> # Start the nginx pod using a different command and custom arguments kubectl run nginx --image=nginx --command -- <cmd> <arg1> ... <argN>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31第二种声明式创建,就是使用yaml文件,
#1. 我们可以使命创建pod的命令导出yaml,进行修改,推荐使用该方式 #2. 也可以自己书写yaml, #我们使用第一种方式,来创建yaml [root@master ~]# kubectl run nginx --image=nginx --dry-run=client -o yaml > nginx_pod.yaml W0121 15:21:48.224142 3517232 helpers.go:555] --dry-run is deprecated and can be replaced with --dry-run=client. #增加 --dry-run=client选项参数,输出pod的yaml模板 #可以看到在当前目录中生成了名为nginx_pod.yaml文件,我来查看一下该文件内容 [root@master ~]# vi nginx_pod.yaml1
2
3
4
5
6
7
8
9
10
11#指定api版本,该选项为固定 apiVersion: v1 #指定类型为pod, kind: Pod metadata: labels: run: nginx #pod的名称 name: nginx spec: #pod中的容器的定义 containers: #容器使用的镜像,这里可以指定多个镜像,来运行多个容器 - image: nginx name: nginx resources: {} dnsPolicy: ClusterFirst #重启策略 restartPolicy: Always1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 使用 kubectl apply -f nginx_pod.yaml [root@master ~]# kubectl apply -f nginx_pod.yaml pod/nginx created [root@master ~]# kubectl get pod NAME READY STATUS RESTARTS AGE nginx 0/1 ContainerCreating 0 4s #可以看到nginx_pod被创建,状态为ContainerCreating1
2
3
4
5
6
7
3.2 查看pod
#查看pod列表
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 0/1 ContainerCreating 0 12s <none> node2 <none> <none>
[root@master ~]#
#查看指定pod的信息,可以使用'kubectl get pod pod名称'来查看
[root@master ~]# kubectl get pod nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 4m37s 172.16.104.4 node2 <none> <none>
#如果想要单个Pod的更多信息,可以使用'kubectl describe pod pod名称'该命令查看
[root@master ~]# kubectl describe pod nginx
Name: nginx
Namespace: default
Priority: 0
Node: node2/192.168.137.18
Start Time: Fri, 21 Jan 2022 10:53:27 -0500
Labels: run=nginx
Annotations: cni.projectcalico.org/containerID: e92841643ed06a3247e1413770d5747760e15da42deb78247c4f30b298a0ef92
cni.projectcalico.org/podIP: 172.16.104.3/32
cni.projectcalico.org/podIPs: 172.16.104.3/32
Status: Running
IP: 172.16.104.3
IPs:
IP: 172.16.104.3
Containers:
nginx:
Container ID: docker://cb8b6ecda69e2c854d9a723826b6c7e49bb3e831f589430e5e04237c8b21354f
Image: nginx
Image ID: docker-pullable://nginx@sha256:0d17b565c37bcbd895e9d92315a05c1c3c9a29f762b011a10c54a66cd53c9b31
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 21 Jan 2022 10:53:44 -0500
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wv8bb (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-wv8bb:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 60s default-scheduler Successfully assigned default/nginx to node2
Normal Pulling 58s kubelet Pulling image "nginx"
Normal Pulled 42s kubelet Successfully pulled image "nginx" in 15.3975152s
Normal Created 42s kubelet Created container nginx
Normal Started 42s kubelet Started container nginx
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
3.3 编辑pod
#使用 kubectl edit pod pod名称,来对正在运行的pod进行编辑
[root@master ~]# kubectl edit pod nginx
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Pod
metadata:
annotations:
cni.projectcalico.org/containerID: e92841643ed06a3247e1413770d5747760e15da42deb78247c4f30b298a0ef92
cni.projectcalico.org/podIP: 172.16.104.3/32
cni.projectcalico.org/podIPs: 172.16.104.3/32
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"creationTimestamp":null,"labels":{"run":"nginx"},"name":"nginx","namespace":"default"},"spec":{"containers":[{"image":"nginx","name":"nginx","resources":{}}],"dnsPolicy":"ClusterFirst","restartPolicy":"Always"},"status":{}}
creationTimestamp: "2022-01-21T15:53:26Z"
labels:
run: nginx
name: nginx
namespace: default
resourceVersion: "35881"
uid: 49225fbf-0adf-404b-af78-96e84cb1fcba
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-wv8bb
readOnly: true
dnsPolicy: ClusterFirst
.........
#这个时候出现了该pod的一个详细的信息,并以yaml格式进行输出,我可以直接更改其中的一些选项,然后保存即可
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
3.4 删除pod
删除pod有两种方案
- 第一种使用利用创建的yaml文件进行删除,使用命令kubectl delete -f yaml文件名称
#执行kubectl delete -f nginx_pod.yaml
[root@master ~]# kubectl delete -f nginx_pod.yaml
pod "nginx" deleted
[root@master ~]#
#可以看到Pod被删除
2
3
4
5
- 直接使用命令kubectl delete pod pod名称
#执行以下命令,pod名称
[root@master ~]# kubectl delete pod nginx
pod "nginx" deleted
[root@master ~]#
2
3
4
3.5 进入pod
在Kubernetes中,我们同样可以进入容器内部,使用方式与Docker进入容器几乎一样,kubectl exec -it pod名称进入容器内部,该命令在当前版本是可用的,不过提示在未来版本可能会被更换.
进入容器内部,我们就可以执行我们需要的命令,当前前提是该镜像在构建时,已经打包进去了.
[root@master ~]# kubectl exec -it nginx bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx:/# ls
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@nginx:/#
2
3
4
5
3.6 pod日志
我们可以使用命令kubect logs pod名称来查看内部容器日志
[root@master ~]# kubectl logs nginx
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
2022/01/21 16:26:57 [notice] 1#1: using the "epoll" event method
2022/01/21 16:26:57 [notice] 1#1: nginx/1.21.5
2022/01/21 16:26:57 [notice] 1#1: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2022/01/21 16:26:57 [notice] 1#1: OS: Linux 4.18.0-147.el8.x86_64
2022/01/21 16:26:57 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2022/01/21 16:26:57 [notice] 1#1: start worker processes
2022/01/21 16:26:57 [notice] 1#1: start worker process 31
2022/01/21 16:26:57 [notice] 1#1: start worker process 32
2022/01/21 16:26:57 [notice] 1#1: start worker process 33
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
4. pod高级特性
前几章我们学习了pod的一些基本操作,接下来我们来看一下pod的一些高级特性,这些高级特性都是日常工作中经常用到的.
首先我们来查看一下讲解一下相对比较完整的的pod的yaml文件
apiVersion: v1
kind: Pod
#4.1 元数据
metadata:
namespace: default
labels:
run: nginx
app: nginxtest
#pod的名称
name: nginx-pod-name
spec:
#4.2 节点调度
nodeSelector:
app: app
containers:
#镜像地址
- image: nginx
#4.3 镜像拉取策略
imagePullPolicy: IfNotPresent
#这是容器的名称
name: nginx-container-name
#4.4 环境变量
env:
- name: ASPNETCORE_ENVIRONMENT
value: Production
- name: TZ
value: Asia/Shanghai
ports:
- containerPort: 80
#4.5 健康检查
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
#4.6 资源限制
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 256Mi
#4.7 重启策略
restartPolicy: Always
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
4.1 元数据
1. namespace
namespace简称ns命名空间,属于一种顶级的逻辑隔离,不同namespace中的资源是属于逻辑隔离状态,无法直接进行通讯,当然借助于后续第五章 Service的能力来实现跨命名空间调用,我们依然是可以通讯的.Kubernetes集群默认有三个namespace
default
如果我们在创建资源时,没有指定任何命名空间的话,Kubernetes会将资源创建到该命名空间下
kube-system
属于集群的命名空间,通常我们不会对该命名空间做任何的资源操作.
kube-public
该命名空间也是Kubernetes自动创建,但是一般我们不会使用该命名空间.
查看namspace
我们可以使用kubectl get namespaces来查看,集群上的已经存在的命名空间.
[root@master ~]# kubectl get namespaces
NAME STATUS AGE
default Active 9d
kube-public Active 9d
kube-system Active 9d
[root@master ~]#
2
3
4
5
6
7
也可以查看某个命名空间下的指定资源kubectl get pod -n kube-system
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-75f8f6cc59-9gjg6 1/1 Running 0 9d
calico-node-csf8l 0/1 Running 0 9d
calico-node-h2qz9 0/1 Running 0 9d
coredns-7f6cbbb7b8-d4bz7 1/1 Running 0 9d
coredns-7f6cbbb7b8-kpklt 1/1 Running 0 9d
etcd-master 1/1 Running 0 9d
kube-apiserver-master 1/1 Running 0 9d
kube-controller-manager-master 1/1 Running 0 9d
kube-proxy-8rpnm 1/1 Running 0 9d
kube-proxy-pvpv9 1/1 Running 0 9d
kube-scheduler-master 1/1 Running 0 9d
2
3
4
5
6
7
8
9
10
11
12
13
创建namspace
创建namespace也非常容易,既可以通过kubect create namespace 命名空间名称来创建,也可以通过声明式的yaml文件来创建
#通过kubectl create namespace 创建命名空间
[root@master ~]# kubectl create namespace dotnet
namespace/dotnet created
2
3
4
5
#通过yaml文件创建命名空间
#创建以下内容并保存为dotnet.yaml
apiVersion: v1
kind: Namespace
metadata:
name: dotnet
[root@master ~]# kubectl apply -f dotnet.yaml
namespace/dotnet created
2
3
4
5
6
7
8
9
10
删除namspace
同样的删除namspace依然可以用两种方式,通过命令kubectl delete namspace 命名空间名称,也可以通过yaml文件来删除
#通过kubectl delete namespace来删除命名空间
[root@master ~]# kubectl delete namespace dotnet
namespace "dotnet" deleted
2
3
4
5
#通过yaml文件来删除namespace
[root@master ~]# kubectl delete -f dotnet.yaml
namespace "dotnet" deleted
2
3
4
5
删除namesapce会删除该命名空间以下所有的资源.
2. labels
labels意为标签,我们可以给pod打上多种多样的标签,通过标签我们可以对pod进行分组,还可以实现对pod的更高级的应用,比如应用控制器.
labels的表现形式key=value的形式
增加标签
除了在yaml文件里定义label,我们还可以对已经运行中的pod进行打标签
#通过kubectl label 命令对pod打上标签
[root@master ~]# kubectl label pod nginx unhealthy=true
pod/nginx labeled
2
3
4
查看标签
#增加 --show-labels 选项来输出pod的标签
[root@master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 4m40s run=nginx,unhealthy=true
nginx-pod 1/1 Running 0 4d1h run=nginx-pod
2
3
4
5
6
7
删除标签
#通过kubectl label pod nginx 标签名称- 来移除指定标签
[root@master ~]# kubectl label pod nginx unhealthy-
pod/nginx labeled
[root@master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx 1/1 Running 0 6m1s run=nginx
nginx-pod 1/1 Running 0 4d1h run=nginx-pod
2
3
4
5
6
7
8
9
10
4.2 节点调度
nodeSelector选项指定该pod将会被部署到带有指定标签的node节点.
部署以上的yaml文件,pod并不会被创建,因为nodeSelector指定了pod需要调度到带有标签app=app的node节点上.所以当前我们的集群中的两个节点没有该标签,所以pod的状态会处于Pending状态
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod-name 0/1 Pending 0 59s
[root@master ~]# kubectl get node --show-labels=true
NAME STATUS ROLES AGE VERSION LABELS
master Ready control-plane,master 4d21h v1.23.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
node1 Ready <none> 4d19h v1.23.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux
node2 Ready <none> 4d19h v1.23.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux
2
3
4
5
6
7
8
9
接下来,我在node1节点上打上这个标签
[root@master ~]# kubectl label node node1 app=app
node/node1 labeled
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-pod-name 1/1 Running 0 8m29s
2
3
4
5
6
可以看到处于Pending状态的pod,已经Running了.这就是我们通过label实现pod的调度
1. 污点
污点 Taints
在前面的章节,我们了解到pod可以通过nodeSelector选项,将pod调度到指定的node节点上.接下来,我们实验室一个效果.在集群中直接创建10个nginx pod
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 3m3s 172.16.104.9 node2 <none> <none>
nginx-pod-name 1/1 Running 0 115m 172.16.166.130 node1 <none> <none>
nginx1 1/1 Running 0 2m57s 172.16.104.10 node2 <none> <none>
nginx2 1/1 Running 0 2m53s 172.16.104.11 node2 <none> <none>
nginx3 1/1 Running 0 2m50s 172.16.104.12 node2 <none> <none>
nginx4 1/1 Running 0 2m47s 172.16.104.13 node2 <none> <none>
nginx5 1/1 Running 0 2m44s 172.16.166.131 node1 <none> <none>
nginx6 1/1 Running 0 2m40s 172.16.104.14 node2 <none> <none>
nginx7 1/1 Running 0 2m36s 172.16.104.15 node2 <none> <none>
nginx8 1/1 Running 0 2m33s 172.16.104.16 node2 <none> <none>
nginx9 1/1 Running 0 2m30s 172.16.166.132 node1 <none> <none>
2
3
4
5
6
7
8
9
10
11
12
13
我们发现,所有的pod都被调度到了node1节点与node2节点上了,那么为什么master节点没有被调度到呢?这就是接下来我们要聊到的节点的污点机制
通俗的来说就是设置了污点的node节点,将不会被调度pod.除非pod有被设置容忍 Tolerations,
我们先查看node1与node2污点设置,看到是none
[root@master ~]# kubectl describe node node1 | grep Taints
Taints: <none>
[root@master ~]# kubectl describe node node2 | grep Taints
Taints: <none>
2
3
4
两个node节点都没有任何污点,在看一下master节点
[root@master ~]# kubectl describe node master | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
2
看到master节点上Taints被设置了为NoSchedule.接下来我们做一个实验.
首先删除这10个nginx的pod,
[root@master ~]# kubectl get pod -n default | grep nginx | awk '{print $1}' | xargs kubectl delete pod -n default
pod "nginx" deleted
pod "nginx-pod-name" deleted
pod "nginx1" deleted
pod "nginx2" deleted
pod "nginx3" deleted
pod "nginx4" deleted
pod "nginx5" deleted
pod "nginx6" deleted
pod "nginx7" deleted
pod "nginx8" deleted
pod "nginx9" deleted
[root@master ~]# kubectl get pod
No resources found in default namespace.
2
3
4
5
6
7
8
9
10
11
12
13
14
然后将master节点上的污点移除.然后将node1与node2节点都标记污点
#移除master的污点
[root@master ~]# kubectl taint node master node-role.kubernetes.io/master:NoSchedule-
node/master untainted
[root@master ~]# kubectl describe node master | grep Taints
Taints: <none>
#对node1节点进行标记污点
[root@master ~]# kubectl taint node node1 key1=value1:NoSchedule
node/node1 tainted
#对node2节点进行标记污点
[root@master ~]# kubectl taint node node2 key1=value1:NoSchedule
node/node2 tainted
2
3
4
5
6
7
8
9
10
11
12
13
接下来我们在连续创建10个pod
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx10 1/1 Running 0 6s 172.16.219.85 master <none> <none>
nginx2 1/1 Running 0 49s 172.16.219.77 master <none> <none>
nginx3 1/1 Running 0 46s 172.16.219.78 master <none> <none>
nginx4 1/1 Running 0 41s 172.16.219.79 master <none> <none>
nginx5 1/1 Running 0 36s 172.16.219.80 master <none> <none>
nginx6 1/1 Running 0 33s 172.16.219.81 master <none> <none>
nginx7 1/1 Running 0 16s 172.16.219.82 master <none> <none>
nginx8 1/1 Running 0 13s 172.16.219.83 master <none> <none>
nginx9 1/1 Running 0 10s 172.16.219.84 master <none> <none>
2
3
4
5
6
7
8
9
10
11
可以看到所有的pod都已经在master节点上创建了
污点的语法构成
key=value:effect
effect一共有以下三个值
#NoSchedule意为不能被调度
kubectl taint node node1 key1=value1:NoSchedule
#NoExecute意为不能被调度,且会驱逐节点上已有的pod
kubectl taint node node1 key1=value1:NoExecute
#PreferNoSchedule意为尽量不被调度
kubectl taint node node1 key1=value1:PreferNoSchedule
2
3
4
5
6
7
2. 容忍
容忍 Tolerations
污点是标记的node节点,那么容忍就是对pod的标记.简单的来说就是pod如果标记了容忍那么即使node节点被标记了污点,pod依然会被调度到该节点上
我们来做一个示例,示例的目的是将node2节点设置为污点,然后我们将pod通过nodeSelector调度到node2节点上.看一下是否会成功.
首先我们将master节点恢复污点,node1与node2节点移除污点
[root@master ~]# kubectl describe node master | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
[root@master ~]# kubectl describe node node1 | grep Taints
Taints: key1=value1:NoSchedule
[root@master ~]# kubectl describe node node2 | grep Taints
Taints: key1=value1:NoSchedule
[root@master ~]#
2
3
4
5
6
7
可以看到三个节点都已经有了污点,然后部署以下的yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
labels:
run: nginx
app: nginxtest
name: nginx-tolerations
spec:
nodeSelector:
app: app
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx-tolerations
#此处为容忍设置,意为容忍key1中存在NoSchedule
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
#可以看到依然被部署到了node1节点上
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-tolerations 1/1 Running 0 6s 172.16.166.139 node1 <none> <none>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
这就是pod的容忍的能力.operator有二个值
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
2
3
4
- Equal,意如其名就是effect值应该相等
- Exists,就是存在,effect值存在即可
多个污点的匹配原则
可以给一个节点添加多个污点,也可以给一个 Pod 添加多个容忍度设置。
Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。余下未被过滤的污点的 effect 值决定了 Pod 是否会被分配到该节点,特别是以下情况:
- 如果未被过滤的污点中存在至少一个 effect 值为
NoSchedule的污点, 则 Kubernetes 不会将 Pod 分配到该节点。 - 如果未被过滤的污点中不存在 effect 值为
NoSchedule的污点, 但是存在 effect 值为PreferNoSchedule的污点, 则 Kubernetes 会 尝试 不将 Pod 分配到该节点。 - 如果未被过滤的污点中存在至少一个 effect 值为
NoExecute的污点, 则 Kubernetes 不会将 Pod 分配到该节点(如果 Pod 还未在节点上运行), 或者将 Pod 从该节点驱逐(如果 Pod 已经在节点上运行)。
例如,假设您给一个节点添加了如下污点
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
2
3
假定有一个 Pod,它有两个容忍度:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
2
3
4
5
6
7
8
9
上述 Pod 不会被分配到 node1 节点,因为其没有容忍度和第三个污点相匹配。
但是如果在给节点添加上述污点之前,该 Pod 已经在上述节点运行, 那么它还可以继续运行在该节点上,因为第三个污点是三个污点中唯一不能被这个 Pod 容忍的。
4.3 镜像拉取
imagePullPolicy定义了镜像的拉取策略,该选项有以下3个值
Always
每次都拉取镜像,该参数为默认参数
Never
从不拉取镜像,只使用本地镜像
IfNotPresent
如果本地不存在该镜像,就从网络拉取镜像,我们实战中经常用到该选项
4.4 环境变量
通过env选项,我们可以注入环境变量,我们可以通过环境变量来区分是测试环境还是生产环境.在此示例中,我们注入了ASPNetCore使用的ASPNETCORE_ENVIRONMENT环境变量值为Production,还设置了时区为亚洲/上海
env:
- name: ASPNETCORE_ENVIRONMENT
value: Production
- name: TZ
value: Asia/Shanghai
2
3
4
5
4.5 健康检查
...
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
健康检查用于检测我们的应用是否在正常工作,是保障业务可用性的一种机制.如果检测的状态不符合预期,则将应用实例排除,不在正在业务流量.
Kubernetes中的健康检查使用存活探测(liveness probes)和就绪探测(readiness probes)来实现,这两种机制是Kubernetes中实现自愈能力的重要手段.基于这两种探测机制,可以实现以下需求:
- 异常实例自动剔除,并重启新实例
- 多种类型探针检测,保证异常pod不接入流量
- 不停机部署,更安全的滚动升级
1. 存活探测
liveness probe,存活探测.用来判断一个 Pod 是否处于存活状态,如果一个 Pod 被探测到不处于存活状态,则由上层判断机制来处理,如果上层配置重启策略为 restart always 的话,Pod 就会被重启。
2. 就绪探测
readiness probe,就绪探测.用来判断一个 Pod 是否处于就绪状态,是否能对外提供相应服务了。当Pod处于就绪状态时,负载均衡器才会将流量打到这个 Pod,否则将把流量从这个 Pod 上面摘除。比如我们的一个服务在启动时,需要从数据库缓存大量数据,所以就会启动的比较慢,那么这个时候则需要等待程序完全启动以后,在接入请求流量
以上两种类型的探测的选项一致,那么我来看下这几个选项的意思
- initialDelaySeconds:延迟探测,单位秒,意为pod启动后,延迟几秒进行探测
- periodSeconds:探测周期,单位秒,意为每隔多少秒探测一次
- timeoutSeconds:超时时间,单位秒
- successThreshold:健康阈值
- failureThreshold:不健康阈值
3. 探针
本示例的yaml文件中配置的选两项是:pod启动后,10秒探测一次,每隔3秒探测一次,如果失败次数超过3则会触发restartPolicy重启策略
一共有三种类型的探针,本实例使用的是httpGet探针,
httpGet
Kubernetes对指定的容器**路径(path)与端口(port)**执行一个HTTP Get请求,可以看到每3秒nginx就会输出请求日志与
kubectl logs nginx-pod-name ... ... 192.168.1.196 - - [25/Jan/2022:18:04:49 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:52 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:52 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:55 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:55 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:58 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" 192.168.1.196 - - [25/Jan/2022:18:04:58 +0800] "GET / HTTP/1.1" 200 615 "-" "kube-probe/1.22" "-" ...1
2
3
4
5
6
7
8
9
10
11liveness probe使用该类型探针
- 状态码:200-300,视为正常.
- 状态码4XX-5XX,视为错误,pod会被重启.
readiness probe使用该类型探针
- 状态码:200-300,视为正常.
- 状态码4XX-5XX,pod会被标记不健康,Kubernetes不在调度流量请求此pod.
tcpSocket
tcpSocket探针与httpGet非常相似,对指定的容器的端口执行一个TCP检查,如果端口能被打开则表示探测成功,否则表示失败,使用方式也很简单
...
...
#4.5 健康检查
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- exec
该类型的探针通过在目标容器中执行由用户自定义的命令来判断容器的监控状态,若命令状态返回值为0则表示“成功”通过检测,其他值则均为“失败”状态。
该命令使用方式也比较简单,具体格式如下:
...
...
#4.5 健康检查
livenessProbe:
exec:
command: ["/bin/sh" ,"-c","echo from-livenessProbe > livenessProbe.txt"]
initialDelaySeconds: 10
periodSeconds: 3
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
exec:
command: ["/bin/sh" ,"-c","echo from-readinessProbe > readinessProbe.txt"]
initialDelaySeconds: 10
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
我们部署修改后的yaml文件后,进入到pod内部来查看当前目录是否存在这两个文件
[root@master ~]# kubectl exec -it nginx-pod-name bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-pod-name:/# ls
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 livenessProbe.txt media mnt opt proc readinessProbe.txt root run sbin srv sys tmp usr var
2
3
4
可以看到当前目录已经生成了livenessProbe.txt与readinessProbe.txt两个文件.
探针每次探测都将获得以下三种结果之一:
Success(成功):容器通过了诊断。Failure(失败):容器未通过诊断。Unknown(未知):诊断失败,因此不会采取任何行动。
至此三种类型探针已经介绍完毕,这三种类型的探针,同时只能使用一种,不能同时使用.在实际应用中大多使用httpGet方式.
4.6 资源限制
Kubernetes对于资源限制只能限制两种资源类型cpu与内存,对于网络与存储目前是无法限制的.
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 256Mi
2
3
4
5
6
7
requests,是资源需求,即pod最少需要的使用量.
本示例中的yaml配置的是:最少需要内存128mb,cpu为100m.
limits,是资源限制,pod运行期间,最大的使用量.
本示例中的yaml配置的是:pod运行期间,最大只能使用内存为256mb,cpu为500m
这个cpu的资源我们该怎么理解?1个cpu等于1000m,假如node节点上cpu是4核,这么整个cpu资源就为4000m.如果requests的资源需求在所有的node节点上无法被满足,那么这个pod就会被Pending,直到有node节点的资源满足才会被调度.
为什么要资源限制?试想一下,如果不对pod进行资源限制,那么集群资源相对紧张的时候,每个pod会争抢内存与cpu, 当node节点资源不够的时候,可能会造成pod的漂移,即可能会被Kubernetes终止占用资源最大的pod,然后调度到认为合适的node节点上.当然也肯能会处于Pending状态
4.7 重启策略
restartPolicy来指定容器的重启策略,该参数有以下三个选项
- Always:默认值,只要退出就重启
- OnFailure:失败退出时(exit code 不为 0)才重启
- Never: 永远不重启
kubelet 会按指数回退方式计算重启的延迟(10s、20s、40s、...),其最长延迟为 5 分钟。 一旦某容器执行了 10 分钟并且没有出现问题,kubelet 对该容器的重启回退计时器执行 重置操作
4.8 生命周期
pod被认为是相对临时性(而不是长期存在)的实体。 Pod 会被创建,并赋予一个唯一的 ID, 并被调度到节点,并在终止(根据重启策略)或删除之前一直运行在该节点。
如果一个node节点挂掉了,那么该节点 的pod也被计划在给定超时期限结束后被删除.Pod 自身不具有自愈能力。如果 pod 被调度到某node节点,而该节点之后失效,pod会被删除;类似地,pod无法在因节点资源 耗尽或者节点维护而被驱逐期间继续存活。Kubernetes使用一种高级抽象 来管理这些相对而言可随时丢弃的pod实例,称作 控制器
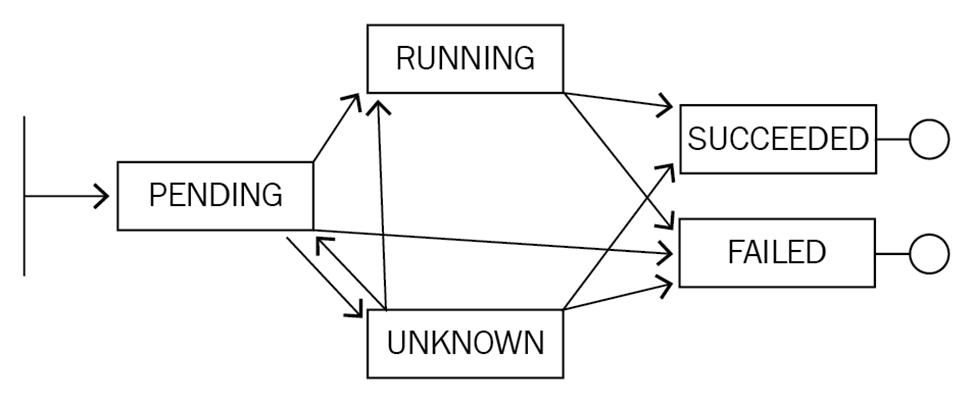
pod状态一共有以下五种状态
- Pending: Kubernetes 已经创建并确认该 Pod,可能两种情况: 1. Pod 还未完成调度(例如没有合适的节点);2. 正在从镜像仓库拉取镜像
- Running: 该 Pod 已经被绑定到一个节点,并且该 Pod 所有的容器都已经成功创建,其中至少有一个容器正在运行,或者正在启动/重启
- Succeeded:Pod 中的所有容器都已经成功终止,并且不会再被重启
- Failed:Pod 中的所有容器都已经终止,至少一个容器终止于失败状态:容器的进程退出码不是 0,或者被系统 kill
- Unknown: 因为某些未知原因,不能确定 Pod 的状态,通常的原因是 master 与 Pod 所在节点之间的通信故障
4.9 Init容器
init 容器是一种特殊的容器,它会在pod内应用容器启动之前运行,用于执行一些初始化操作.该容器与普通的容器非常像,但是除了以下2点:
- init 容器总是最先运行
- 运行完成后才会于运行下一个容器
如果init 容器出现错误,那么Kubernetes会不断重启该容器,直到成功为止.如果restartPolicy重启策略为Never,则整个pod的状态会被设置成失败.
init 容器不支持livenessProbe与readinessProbe,如果有多个init 容器,Kubernetes会依次按照顺序逐个执行,每一个必须执行成功,下一个才能执行.
下面我们看一个init 容器示例,该示例是使用init 容器将ningx的启示页面更改成百度.
...
...
#4.2 节点调度
nodeSelector:
app: app
#4.9 init容器
initContainers:
- name: downloand-index-page
image: busybox
imagePullPolicy: IfNotPresent
command: ["wget","-O","/wwwroot/index.html","https://www.baidu.com"]
#本实例用到了存储卷,该功能我们将在第六章介绍
volumeMounts:
- name: wwwroot
mountPath: "/wwwroot"
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx-container-name
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
...
...
restartPolicy: Always
volumes:
- name: wwwroot
emptyDir: {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
首先我们挂载了一个wwwroot目录到init容器,然后通过wget下载了百度的首页,保存到了wwwroot目录,名为index.html.然后启动nginx容器,nginx容器上同样挂载了wwwroot目录,映射到了容器内部nginx的默认目录内,即**/usr/share/nginx/html**,这样nginx的index.html就被替换了.
pod成功启动以后,我使用curl命令来访问pod的IP地址,可以看到首页已经被替换成百度了
第四章 存储卷
Kubernetes支持很多种类型的存储卷,在此章节中,我主要讲解emptyDir,hostPath,持久卷这三种类型.还有其他类型的存储卷如:
- **SAN(存储区域网络)😗*iSCSI,FB
- **NAS(网络附加存储)😗*NFS,CIFS
- 分布式存储: cephfs,Glusterfs,ceph(rbd)
- **云存储:**Azure Disk,Amazon EBS
1. emptyDir
2. hostPath
此类型的存储方式,类似在创建容器时,我们使用的**-v xx/xx**这样挂载目录,意思是在将宿主机的目录映射到容器内部目录,如果目录不存在则会自动创建目录,当pod被删除时,emptyDir中存储的数据与目录也会被一起删除
3. 持久卷
第五章 Secret与ConfigMap
1. Secret
在真实业务场景下,有一些敏感信息,不能使用明文,Secret就是用来解决该场景的组件.
1. 查看
[root@master ~]# kubectl get secret
NAME TYPE DATA AGE
default-token-kctt5 kubernetes.io/service-account-token 3 8dxxxxxxxxxx kubectl get sc[root@master ~]# kubectl get secretNAME TYPE DATA AGEdefault-token-kctt5 kubernetes.io/service-account-token 3 8d
#描述指定的secret
[root@master ~]# kubectl describe secret default-token-kctt5
Name: default-token-kctt5
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: b7ebc16d-ad92-4240-99d2-236abfbe1eb5
Type: kubernetes.io/service-account-token
Data
====
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjQ0bjlCSDZiOGM0ejR3akpoZDlkV0pZZU5iRWtQY0RkVnB5b3ctRnVrdzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImRlZmF1bHQtdG9rZW4ta2N0dDUiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGVmYXVsdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImI3ZWJjMTZkLWFkOTItNDI0MC05OWQyLTIzNmFiZmJlMWViNSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmRlZmF1bHQifQ.tNWsCzQawHVKqpu4Bg7uuGr5jN3njtPGHdPIfBGWGgU5MWBbP4bwDWiuKga2PGqsl3x_e3OVKngqE3RpNFmwD2u3RBb22w_NsBM6wdzTATbXB1oYf3OaYNQOgrFCyeuNqV1WqI276BPMzElbQNdFlz3_2roi0MJ8GK28MHP1eOIVcAB81v5b4G3vEI0jji4RpSYl1s0uBrALSZdfiecuRXbdKvm_v-jBVy1krLhKpZIUt_Qtc9CePPu_Wlnynmcn6CcFB8hIlclNs2MfRXnG_Q3BEjJTzeVDwXEg5WI07sxaBxuVUhIIkODDks_sURWiVhj_14BpOjXYeZhbUC5CnQ
ca.crt: 1099 bytes
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2. 创建
创建secret有两种方式,
- 使用**kubectl create secret generic 名称 --from-literal=key名称=base64值 **方式
#我们创建一个sqlserver的连接字符串
#直接利用echo生成base64字符串
#生成base64字符串
[root@master ~]# echo -n 'server=.;db=users;uid=sa;pwd=123456;' | base64
c2VydmVyPS47ZGI9dXNlcnM7dWlkPXNhO3B3ZD0xMjM0NTY7
#创建secret
[root@master ~]# kubectl create secret generic db-connection --from-literal=connection=c2VydmVyPS47ZGI9dXNlcnM7dWlkPXNhO3B3ZD0xMjM0NTY7
secret/db-connection created
#查看该secret
[root@master ~]# kubectl get secret
NAME TYPE DATA AGE
db-connection Opaque 1 58s
default-token-kctt5 kubernetes.io/service-account-token 3 8d
[root@master ~]# kubectl describe secret default-token-kctt5
Name: default-token-kctt5
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: b7ebc16d-ad92-4240-99d2-236abfbe1eb5
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1099 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjQ0bjlCSDZiOGM0ejR3akpoZDlkV0pZZU5iRWtQY0RkVnB5b3ctRnVrdzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImRlZmF1bHQtdG9rZW4ta2N0dDUiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGVmYXVsdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImI3ZWJjMTZkLWFkOTItNDI0MC05OWQyLTIzNmFiZmJlMWViNSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmRlZmF1bHQifQ.tNWsCzQawHVKqpu4Bg7uuGr5jN3njtPGHdPIfBGWGgU5MWBbP4bwDWiuKga2PGqsl3x_e3OVKngqE3RpNFmwD2u3RBb22w_NsBM6wdzTATbXB1oYf3OaYNQOgrFCyeuNqV1WqI276BPMzElbQNdFlz3_2roi0MJ8GK28MHP1eOIVcAB81v5b4G3vEI0jji4RpSYl1s0uBrALSZdfiecuRXbdKvm_v-jBVy1krLhKpZIUt_Qtc9CePPu_Wlnynmcn6CcFB8hIlclNs2MfRXnG_Q3BEjJTzeVDwXEg5WI07sxaBxuVUhIIkODDks_sURWiVhj_14BpOjXYeZhbUC5CnQ
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 使用声明式的yam文件
#将该内容保存为secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: db-connection2
type: Opaque
data:
connection: c2VydmVyPS47ZGI9dXNlcnM7dWlkPXNhO3B3ZD0xMjM0NTY7
2
3
4
5
6
7
8
[root@master ~]# kubectl apply -f secret.yaml
secret/db-connection created
2
3. 删除
[root@master ~]# kubectl delete secret default-token-kctt5
secret "default-token-kctt5" deleted
[root@master ~]#
2
3
4. 使用
使用secret的方式有两种
- 以环境变量的方式注入
- 以挂载卷的形式注入
下面我们将使用变量注入的方式来使用该变量
#将该内容保存为get_secret.yaml
apiVersion: v1
kind: Pod
metadata:
name: get-db-connection
spec:
containers:
- name: get-db-connection
image: nginx
imagePullPolicy: IfNotPresent
env:
- name: DB_CONNECTION
valueFrom:
secretKeyRef:
#这里为secret名称
name: db-connection
#这里为key
key: connection
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@master ~]# kubectl apply -f get_secret.yaml
pod/get-db-connection created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
get-db-connection 1/1 Running 0 4s
#进入到该Pod内部,并查看环境变量
[root@master ~]# kubectl exec -it get-db-connection bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
#可以看到该环境变量已经注入,并且已经从base64解析
[root@get-db-connection:/# echo $DB_CONNECTION
server=.;db=users;uid=sa;pwd=123456;
[root@get-db-connection:/#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们来使用挂载卷的方式来使用该secret
# 将内容保存到get_secret_volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: get-secret-volume
spec:
containers:
- name: get-secret-volume
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: dbstr
#挂载到根目录下的db
mountPath: "/db"
volumes:
- name: dbstr
secret:
secretName: db-connection
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@master ~]# kubectl apply -f get_secret_volume.yaml
pod/get-secret-volume created
[root@master ~]# kubectl exec -it get-secret-volume bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
#可以看到db目录已经生成了
root@get-secret-volume:/# ls
bin boot db dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
#读取该目录
root@get-secret-volume:/# cat /db/connection
server=.;db=users;uid=sa;pwd=123456;
2
3
4
5
6
7
8
9
10
11
12
13
2. configmap
configmap简称cm,通常用于来注入配置文件,使用key=value键值对的像是来配置数据.
1. 查看
[root@master ~]# kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 8d
#描述指定的configmap
[root@master ~]# kubectl describe configmap kube-root-ca.crt
Name: kube-root-ca.crt
Namespace: default
Labels: <none>
Annotations: kubernetes.io/description:
Contains a CA bundle that can be used to verify the kube-apiserver when using internal endpoints such as the internal service IP or kubern...
Data
====
ca.crt:
----
-----BEGIN CERTIFICATE-----
MIIC/jCCAeagAwIBAgIBADANBgkqhkiG9w0BAQsFADAVMRMwEQYDVQQDEwprdWJl
cm5ldGVzMB4XDTIyMDEyMDEzMDQ0NVoXDTMyMDExODEzMDQ0NVowFTETMBEGA1UE
AxMKa3ViZXJuZXRlczCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBALnF
vVmqOx3PYFZU4iQiNX9Izs2SMf043UT5EOKvulWyLN81DiHxXaGkNfXdx2f4Msj6
NhAVlf9NKWxcJsjqdzVkve9J72HW2qBeQvK4YdNilBioVGlMX/gd/HdPFn70p/Gw
cdGi5feO16kf2oqlD2PlCtCXqifKX8rq/EWKR95tDuhWVYzS0uw0y5A48SC72S2U
9xuDOP2oCbpnIl2nwdgeo9UZlLklIIZTrAEVLinQgHExXH1z7jJoXcFuLUIhcNsv
EOWkOwc4lXLwWuW7nJoxo9x3Caw+SJFBPfp32PjdsH4lU7FI+KnYHMLoRKv57RiE
LtmTJtoxw2kaKNN22asCAwEAAaNZMFcwDgYDVR0PAQH/BAQDAgKkMA8GA1UdEwEB
/wQFMAMBAf8wHQYDVR0OBBYEFHtus55PiONH7Z4zoR3kppjLZc2pMBUGA1UdEQQO
MAyCCmt1YmVybmV0ZXMwDQYJKoZIhvcNAQELBQADggEBAH/CQItVAhUM25xaWZAa
T2tt5qTAbN7PqxnGSRm5b5j17j33V3FUCLx6jBW1PLxA+AP/JGCcu+V4yns6I6Mh
A6HqiFzIAaE4dA8wEICD1/fmlloz92OxltB5OrIKaUxtw3GKFywnOeipe+rM56AU
CcnH8+/pWbRxBm9H1+q14wK7Jvk3irM+pwfhblUaxYpXFA2/fyp6nwBPZo818BP4
sNG3zP+7aoCDPG7844Rgyrq6Dfju+T5GSGgiTNaHt6Y10+iYXU47AOj0jFYqPUhT
V1C/NZKQUe5QpI361PLqo7VZCHufP9Y45Pk91+jt6GOuz4qwyZeFGvwSNJCviraB
ApY=
-----END CERTIFICATE-----
BinaryData
====
Events: <none>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2. 创建
configmap创建与使用的方式与secret很相似.
- 使用**kubectl create configmap 名称 --from-literal=key=value **方式
[root@master ~]# kubectl create configmap appsetting --from-literal=db.conneciton='server=.;db=users;uid=sa;pwd=123456;' --from-literal=redis.connection='localhost:6379'
configmap/appsetting created
[root@master ~]# kubectl get cm
NAME DATA AGE
appsetting 2 7s
kube-root-ca.crt 1 8d
[root@master ~]# kubectl describe cm appsetting
Name: appsetting
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
redis.connection:
----
localhost:6379
db.conneciton:
----
server=.;db=users;uid=sa;pwd=123456;
BinaryData
====
Events: <none>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 通过yaml的方式进行创建
#将以下内容保存为cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: appsetting
data:
db.conneciton: 'server=.;db=users;uid=sa;pwd=123456;'
redis.connection: 'localhost:6379'
2
3
4
5
6
7
8
[root@master ~]# kubectl create -f cm.yaml
configmap/appsetting created
2
3. 删除
[root@master ~]# kubectl delete cm appsetting
configmap "appsetting" deleted
2
4. 使用
使用configmap的方式有两种
以环境变量的方式注入
以挂载卷的形式注入
下面我们将使用变量注入的方式来使用该变量
#将该内容保存为get_configmap.yaml
apiVersion: v1
kind: Pod
metadata:
name: get-configmap
spec:
containers:
- name: get-configmap
image: nginx
imagePullPolicy: IfNotPresent
env:
- name: DB_CONNECTION
valueFrom:
configMapKeyRef:
#这里为configmap名称
name: appsetting
#这里为key
key: db.conneciton
- name: REDIS_CONNECTION
valueFrom:
configMapKeyRef:
#这里为configmap名称
name: appsetting
#这里为key
key: redis.connection
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[root@master ~]# kubectl apply -f get_configmap.yaml
pod/get-configmap created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
get-configmap 1/1 Running 0 2s
#进入到该Pod内部,并查看环境变量
[root@master ~]# kubectl exec -it get-configmap bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
#可以看到该环境变量已经注入
root@get-configmap:/# echo $DB_CONNECTION
server=.;db=users;uid=sa;pwd=123456;
root@get-configmap:/# echo $REDIS_CONNECTION
localhost:6379
root@get-configmap:/#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我们来使用挂载卷的方式来使用该configmap
# 将内容保存到get_config_volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: get-config-volume
spec:
containers:
- name: get-config-volume
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: config-volume
#挂载到根目录下的configmap
mountPath: "/configmap"
volumes:
- name: config-volume
configMap:
name: appsetting
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@master ~]# kubectl apply -f get_config_volume.yaml
pod/get-config-volume created
[root@master ~]# kubectl exec -it get-config-volume bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
#可以看到configmap目录已经生成了
root@get-config-volume:/# ls
bin dev etc lib64 opt run sys var
boot docker-entrypoint.d home media proc sbin tmp
configmap docker-entrypoint.sh lib mnt root srv usr
root@get-config-volume:/#
#读取该目录
root@get-config-volume:/# cat /configmap/db.conneciton
server=.;db=users;uid=sa;pwd=123456;
root@get-config-volume:/# cat /configmap/redis.connection
localhost:6379
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
第六章 控制器
Kubernetes中有一组不同的控制器,来确保集群当前的状态保持预期,控制器主要是用来控制Pod的状态和行为,Kubernetes一共有6种不同的类型的控制器,适用于不同场景的需求.
1. Deployment
Deployment简称deploy, 顾名思义,是用于部署应用的对象。它使Kubernetes中最常用的一个对象,它为Pod的创建提供了一种声明式的定义方法
适合无状态的服务部署,什么是无状态的?就是应用程序内部没有存储数据,应用程序可以随意启动与关闭.
比如我们告诉Deployment,我们需要3个pod,那么Deployment控制器就会始终保持3个pod,如果其中的1个pod挂掉了,那么Deployment控制器则会马上重新生成一个pod,保证环境里有3个pod,那么如果挂掉的pod又恢复了,则Deployment控制器则会删除其中的一个pod.
创建Deployment控制器有两种方式,第一种直接使用kubectl create deploy 名称创建,我们来创建一个具有4个副本(pod)的控制器
#kubernetes1.18版本以后使用以下命令
[root@master ~]# kubectl create deploy nginx-deploy --image=nginx --port=80 --replicas=4
deployment.apps/nginx-deploy created
#查看已经部署的Deployment控制器
[root@master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 4/4 4 4 30s
#Kubernetes1.18版本以前使用以下命令
[root@master ~]# kubectl run nginx-deploy --image=nginx --port=80 --replicas=4
2
3
4
5
6
7
8
9
可以看到一个Deployment控制器已经被创建,并且READY中显示为4,说明4个副本(pod)已经全部就绪.我们来查看一下副本(pod)的具体分布
[root@master ~]# kubectl get pod -owide | grep nginx-deploy
nginx-deploy-84bf7bc885-hxpnv 1/1 Running 0 3m43s 172.16.166.138 node1 <none> <none>
nginx-deploy-84bf7bc885-pm6ml 1/1 Running 0 3m43s 172.16.104.58 node2 <none> <none>
nginx-deploy-84bf7bc885-tnwxf 1/1 Running 0 3m43s 172.16.166.139 node1 <none> <none>
nginx-deploy-84bf7bc885-wm22j 1/1 Running 0 3m43s 172.16.104.57 node2 <none> <none>
2
3
4
5
可以看到每个node节点上启动了2个pod.接下来,我删除其中名为nginx-deploy-84bf7bc885-wm22j的pod,看看会发生什么
[root@master ~]# kubectl delete pod nginx-deploy-84bf7bc885-wm22j
pod "nginx-deploy-84bf7bc885-wm22j" deleted
[root@master ~]# kubectl get pod -owide | grep nginx-deploy
nginx-deploy-84bf7bc885-hfbw4 1/1 Running 0 26s 172.16.104.59 node2 <none> <none>
nginx-deploy-84bf7bc885-hxpnv 1/1 Running 0 6m18s 172.16.166.138 node1 <none> <none>
nginx-deploy-84bf7bc885-pm6ml 1/1 Running 0 6m18s 172.16.104.58 node2 <none> <none>
nginx-deploy-84bf7bc885-tnwxf 1/1 Running 0 6m18s 172.16.166.139 node1 <none> <none>
2
3
4
5
6
7
可以看到,nginx-deploy-84bf7bc885-wm22j虽然被删除了,但是又重新启动了一个,这就是Deployment控制器的特性之一,下面,我们在Hyper-V中将node2节点直接关机,再来查看pod会发生什么变化
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 34d v1.23.1
node1 Ready <none> 33d v1.23.1
node2 NotReady <none> 33d v1.23.1
[root@master ~]# kubectl get pod -owide | grep nginx-deploy
nginx-deploy-84bf7bc885-4kn9w 0/1 ContainerCreating 0 2m59s <none> node1 <none> <none>
nginx-deploy-84bf7bc885-5w66q 1/1 Running 0 14m 172.16.166.140 node1 <none> <none>
nginx-deploy-84bf7bc885-76j6h 1/1 Terminating 0 14m 172.16.104.60 node2 <none> <none>
nginx-deploy-84bf7bc885-fhfx8 1/1 Running 0 14m 172.16.166.141 node1 <none> <none>
nginx-deploy-84bf7bc885-jwk6c 0/1 ContainerCreating 0 2m59s <none> node1 <none> <none>
nginx-deploy-84bf7bc885-r94fg 0/1 Terminating 0 14m <none> node2 <none> <none>
2
3
4
5
6
7
8
9
10
11
12
13
可以看到node2节点上的pod开始处于Terminating状态,而node1节点上正在创建新的pod,并且node1节点pod的数量为4
对于已经部署的Deployment控制器,我们可以通过kubectl describe 名称来查看具体信息
[root@master ~]# kubectl describe deploy nginx-deploy
Name: nginx-deploy
Namespace: default
CreationTimestamp: Wed, 23 Feb 2022 09:19:17 -0500
Labels: app=nginx-deploy
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx-deploy
Replicas: 4 desired | 4 updated | 4 total | 1 available | 3 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx-deploy
Containers:
nginx:
Image: nginx
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available False MinimumReplicasUnavailable
Progressing True ReplicaSetUpdated
OldReplicaSets: <none>
NewReplicaSet: nginx-deploy-84bf7bc885 (4/4 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 15s deployment-controller Scaled up replica set nginx-deploy-84bf7bc885 to 4
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
删除Deployment控制器使用kubectl delete deploy 名称
[root@master ~]# kubectl delete deploy nginx-deploy
deployment.apps "nginx-deploy" deleted
2
另外一种创建Deployment控制的方式就是使用声明式的yaml文件进行创建
#该文件定义了一个Deployment对象
apiVersion: apps/v1
kind: Deployment
metadata:
#指定该控制器的名称
name: nginx-deploy
spec:
#指定pod数量为4
replicas: 4
selector:
#指定该控制器需要匹配的pod的标签
#即需要与下template中metadata里的labels的值一模一样
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
#镜像为nginx
- image: nginx
name: nginx
ports:
- containerPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
[root@master ~]# kubectl apply -f deploy.yaml
deployment.apps/nginx-deploy created
[root@master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 4/4 4 4 7s
2
3
4
5
我们可以通过kubectl edit deploy 名称的方式直接编辑已经被创建的控制器,
#比如将该控制器的副本(pod)数更改成2,更改replicas值就可以
[root@master ~]# kubectl edit deploy nginx-deploy
...
...
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: nginx
...
...
[root@master ~]# kubectl get pod | grep nginx-deploy
nginx-deploy-66857ff745-4qgcv 1/1 Running 0 8m43s
nginx-deploy-66857ff745-xktrn 1/1 Running 0 8m43s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们亦可以直接伸缩正在运行中的Deployment控制器
#使用以下命令对副本伸缩到4个
[root@master ~]# kubectl scale deploy nginx-deploy --replicas=4
deployment.apps/nginx-deploy scaled
2
3
我们对Deployment控制器进行镜像的更新与回滚,通过使用命令**kubectl set image deploy/名称 容器名称=镜像 <--record>**命令,来进行镜像更新
#由于我们示例中的nginx镜像版本为最新的,所以我们将镜像更改成为比较旧的版本,比如:1.19.9
[root@master ~]# kubectl set image deploy/nginx-deploy nginx=nginx:1.19.9 --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/nginx-deploy image updated
[root@master ~]# kubectl get pod | grep nginx-deploy
nginx-deploy-54f8496db5-6hw5f 0/1 ContainerCreating 0 65s
nginx-deploy-54f8496db5-c8tcn 0/1 Terminating 0 62m
nginx-deploy-54f8496db5-httwj 0/1 ContainerCreating 0 65s
nginx-deploy-66857ff745-8pw9v 1/1 Running 0 58m
nginx-deploy-66857ff745-bb7hw 1/1 Running 0 58m
nginx-deploy-66857ff745-qw78c 1/1 Running 0 58m
[root@master ~]# kubectl get pod | grep nginx-deploy
nginx-deploy-54f8496db5-6hw5f 1/1 Running 0 17m
nginx-deploy-54f8496db5-httwj 0/1 ContainerCreating 0 17m
nginx-deploy-54f8496db5-qxsnh 1/1 Running 0 4m58s
nginx-deploy-54f8496db5-t5n4q 0/1 ContainerCreating 0 4m56s
nginx-deploy-66857ff745-bb7hw 1/1 Running 0 75m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
可以看到其中的一个副本(pod),处于Terminating状态,正在被终结,另外有2个正在创建中.这说明Deployment控制器并没有将全部的副本(pod)同时进行更新,而是终结了1个副本(pod),这样另外Running的副本(pod)依然可以接受流量处理请求,这样每次更新一个副本(pod),这就是Deployment控制器的滚动升级的特性.
我们再次将镜像更新到最新版本
[root@master ~]# kubectl set image deploy/nginx-deploy nginx=nginx --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/nginx-deploy image updated
[root@master ~]# kubectl get pod | grep nginx-deploy
nginx-deploy-66857ff745-kz7t9 1/1 Running 0 3m47s
nginx-deploy-66857ff745-vj6wq 1/1 Running 0 3m48s
nginx-deploy-66857ff745-x5s2j 1/1 Running 0 3m48s
nginx-deploy-66857ff745-zpqt4 1/1 Running 0 3m47s
2
3
4
5
6
7
8
--reord参数的意义是记录每次更新信息,这样,我们可以通过kubectl rollout history deploy/名称来查看所有的镜像变更历史记录
[root@master ~]# kubectl rollout history deploy/nginx-deploy
deployment.apps/nginx-deploy
REVISION CHANGE-CAUSE
2 kubectl set image deploy/nginx-deploy nginx=nginx:1.19.9 --record=true
3 kubectl set image deploy/nginx-deploy nginx=nginx --record=true
2
3
4
5
我们可以通过命令kubectl rollout undo deploy/名称 --to-revision=版本号 进行回滚
#我再次切换到1.19.9版本
[root@master ~]# kubectl rollout undo deploy/nginx-deploy --to-revision=2
deployment.apps/nginx-deploy rolled back
[root@master ~]# kubectl get pod | grep nginx-deploy
nginx-deploy-54f8496db5-66f94 1/1 Running 0 12s
nginx-deploy-54f8496db5-hrw8b 1/1 Running 0 10s
nginx-deploy-54f8496db5-vn2s8 1/1 Running 0 10s
nginx-deploy-54f8496db5-zjq85 1/1 Running 0 12s
2
3
4
5
6
7
8
控制器的镜像更新受制于更新策略
[root@master ~]# kubectl describe deploy nginx-deploy
Name: nginx-deploy
Namespace: default
CreationTimestamp: Thu, 24 Feb 2022 06:44:10 -0500
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 4
kubernetes.io/change-cause: kubectl set image deploy/nginx-deploy nginx=nginx:1.19.9 --record=true
Selector: app=nginx
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
#此处定义更新策略
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.19.9
Port: 80/TCP
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
max unavailable:升级过程中最多有多少个副本(pod)处于无法提供服务的状态, 该值为百分比或者整型值,该值默认为25%,通过计算max unavailable=4x0.25=1,即每次终结1个副本(pod)
max surge:升级过程中最多可以比原先设置多出的副本(pod)数量, 该值为百分比或者整型值.这个值指定为25%时,也就是说,新旧副本(pod)的总量不能超过125%。简单来讲,就是在滚动升级时,会先启动25%的新的副本(pod)。然后开始杀掉旧的副本(pod),每当一个旧的副本(pod)被杀掉,一个新的副本(pod)的会被启动,始终保持总量不超过125%,直至更新完成.
2. StatefulSet
适合有状态的服务部署,
3. DaemonSet
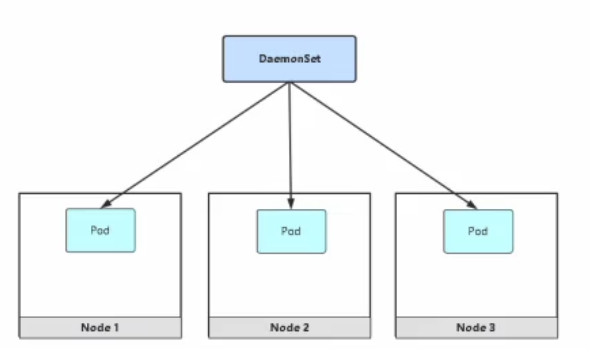
DaemonSet简称(ds)会在所有的节点上或者某些节点都运行一个pod的副本.当有node节点加入时,也会在该节点上增加一个pod.反之如果node节点被移除,则pod也会消失.
**DaemonSet **控制器的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行监控守护进程
- 在每个节点上运行日志收集守护进程
下面我们就使用该控制器,在每一个node节点上部署一个nginx镜像
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: busybox
spec:
selector:
#指定该控制器需要匹配的pod的标签
#即需要与下template中metadata里的labels的值一模一样
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
#busybox镜像是无法常驻的,所以使用sleep命令,让进程停住36000秒
command:
- sleep
- "36000"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-89bmx 1/1 Running 0 9s 172.16.166.186 node1 <none> <none>
busybox-jkjl9 1/1 Running 0 9s 172.16.104.43 node2 <none> <none>
2
3
4
可以看到,我们在yaml文件中没有使用任何关于数量的参数,然后在每个节点上依然创建了pod
#删除
[root@master ~]# kubectl delete ds busybox
daemonset.apps "busybox" deleted
2
3
DaemonSet控制器依然受限于污点,有污点的node节点,是无法进行创建pod的.同样的,我们也可以增加nodeSelector来指定Pod部署到某些节点上
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: busybox
spec:
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
#只在具有标签disktype=ssd的node节点部署
nodeSelector:
disktype: ssd
containers:
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command:
- sleep
- "36000"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
4. Job
Job就是任务,通常用在批处理一些自动化脚本或者预处理一些数据,执行一次性的任务,他保证一个或者多个pod成功结束.
我们使用busybox镜像来输出一个hello job字符串
apiVersion: batch/v1
kind: Job
metadata:
name: job-hello
spec:
template:
metadata:
name: job-hello
spec:
containers:
- name: job-hello
image: busybox
command: ["echo", "hello job!"]
restartPolicy: Never
2
3
4
5
6
7
8
9
10
11
12
13
14
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-hello-64jfl 0/1 Completed 0 91s
[root@master ~]# kubectl logs job-hello-64jfl
hello job!
2
3
4
5
6
可以看到pod完成以后,状态为Completed,查看pod日志,已经输出hello job !
1. 重启策略
Job的重启策略只支持Never和OnFailure,不支持Always,如果pod执行失败,则会收到 restartPolicy的影响
具体如下
Never,集群会不断的生成新的pod,但不会让它一直开下去,默认参数 spec.backoffLimit: 6 会进行阻止
OnFailure,集群不会生成新的pod,会不断的重启该pod.
2. 并行度
parallelism选项为并行度,可以理解为,该pod同时运行指定副本数量,我们来试一下将该选项改为5,在看一下pod的数量
apiVersion: batch/v1
kind: Job
metadata:
name: job-hello
spec:
# 并行度选项
parallelism: 5
template:
metadata:
name: job-hello
spec:
containers:
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
执行以上文件,然后在看结果
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-hello-jd8lt 0/1 Completed 0 79s
job-hello-m5d8c 0/1 Completed 0 79s
job-hello-mp4bs 0/1 Completed 0 79s
job-hello-npvvc 0/1 Completed 0 79s
job-hello-w42gv 0/1 Completed 0 79s
2
3
4
5
6
7
可以看到更改parallelism选项后,pod同时出现了5个副本
5. CronJob
CronJob周期性的调度执行Job,接下来我们将job章节中的yaml稍微改一下
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: cronjob-hello
image: busybox
command: ["echo","cronjob hello!"]
restartPolicy: OnFailure
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们执行以上yaml文件,等待几分钟来查看一下
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
cronjob-hello-27389276-chn4f 0/1 Completed 0 3m5s
cronjob-hello-27389277-qgbtf 0/1 Completed 0 2m5s
cronjob-hello-27389278-cvz8b 0/1 Completed 0 65s
cronjob-hello-27389279-sxrbh 0/1 ContainerCreating 0 5s
2
3
4
5
6
可以看到每一分钟集群都会执行一个Job
CronJob最小只支持以分钟为最小单位调度,
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6) (周日到周一;在某些系统上,7 也是星期日)
# * * * * *
2
3
4
5
6
第七章 自动伸缩
在Kubernetes中自动伸缩通常有三中类型
- CA(Cluster Autoscaler):node节点级别的弹入弹出,通常云厂商提供了该能力
- HPA(Horizontal Pod Autoscaler):pod个数的自动扩容与缩容.本文主要介绍该该特性
- VPA(Vertical Pod Autoscaler):pod配置(request和Limites限额)自动扩融与缩容,该组件目前不是很成熟,应用的比较少
Horizontal Pod Autoscaler简称HPA,是Kubernetes另一个高级特性之一,该特性能够根据某些特定指标自动对pod进行动态伸缩.HPA可以监控pod的CPU使用率,来动态伸缩Deployment与StatefulSet控制器中的pod的数量,但是无法用于DaemonSet控制器
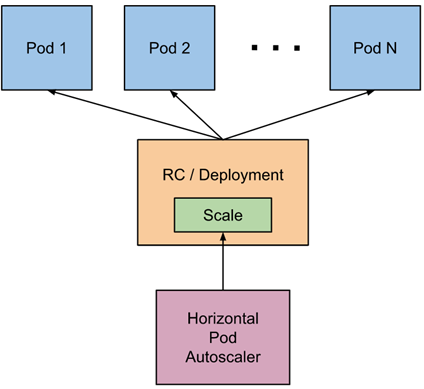
在真实的业务场景中,我们可以将核心业务配置上HPA,以便应对高峰期的流量请求.
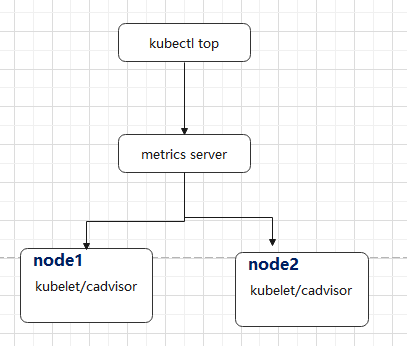
1. metric-server
HPA依赖于metric-server组件来获得核心指标,所以需要安装该组件,metric-server从每个节点上收集各个资源指标,每个node节点上kubelet组件已经内置了cadvisor组件
下载地址: https://github.com/kubernetes-sigs/metrics-server/releases,下载最新版本的yaml文件
下载yaml文件后修改以下内容
...
...
- args:
- --cert-dir=/tmp
- --secure-port=4443
#1. 增加该参数,意为不用验证证书
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
#2. 将k8s.gcr.io修改成registry.cn-hangzhou.aliyuncs.com/google_containers
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.1
imagePullPolicy: IfNotPresent
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
执行该文件
[root@master ~]# kubectl apply -f metrics.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
#可以看到metrics-server的pod正在创建
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-85b5b5888d-26w6v 1/1 Running 11 (25d ago) 35d
calico-node-2n6dg 1/1 Running 10 (45h ago) 35d
calico-node-bwf72 1/1 Running 11 (25d ago) 35d
calico-node-m4gmc 1/1 Running 9 (25d ago) 35d
coredns-6d8c4cb4d-4dqgc 1/1 Running 0 45h
coredns-6d8c4cb4d-86j99 1/1 Running 11 (25d ago) 35d
etcd-master 1/1 Running 11 (25d ago) 35d
kube-apiserver-master 1/1 Running 12 (25d ago) 35d
kube-controller-manager-master 1/1 Running 11 (25d ago) 35d
kube-proxy-8brfp 1/1 Running 9 (25d ago) 35d
kube-proxy-qvqcf 1/1 Running 11 (25d ago) 35d
kube-proxy-vx4ch 1/1 Running 10 (45h ago) 35d
kube-scheduler-master 1/1 Running 11 (25d ago) 35d
metrics-server-7999786998-dhv2t 0/1 ContainerCreating 0 22s
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
安装成功以后,我们使用两个命令来查看资源使用率最高的node节点与pode节点
#该命令查看资源使用率最高的node节点
[root@master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 95m 9% 1260Mi 75%
node1 46m 4% 879Mi 52%
node2 45m 4% 813Mi 48%
#该命令查看资源使用率最高的pod
[root@master ~]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-deploy-66857ff745-vdw7x 0m 2Mi
2
3
4
5
6
7
8
9
10
11
可以通过命令kubectl get hpa来查看当前是否配有HPA
[root@master ~]# kubectl get hpa
No resources found in default namespace.
2
2. 示例
为了模拟自动伸缩效果,我们先部署一个Deployment控制器,副本数为1
#创建Deployment控制器
apiVersion: apps/v1
kind: Deployment
metadata:
#指定该控制器的名称
name: nginx
spec:
#指定pod数量为1
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
#镜像为nginx
- image: nginx
name: nginx
imagePullPolicy: IfNotPresent
resources:
requests:
#该值为必须
cpu: 200m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
部署以上文件
[root@master ~]# kubectl apply -f nginx.yaml
deployment.apps/nginx created
[root@master ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 65s
2
3
4
5
接下来我们部署一个HPA
#创建HPA
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
#需要与刚刚部署的Deployment控制器的名称一样
name: nginx
#定义最少pod数量
minReplicas: 1
#定义最大pod数量
maxReplicas: 3
#当整体资源使用率超过50%则进行扩容,该指标会监视Deployment中的requests的CPU资源使用率
targetCPUUtilizationPercentage: 50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
部署以上文件
[root@master ~]# kubectl apply -f hpa.yaml
horizontalpodautoscaler.autoscaling/nginx-hpa created
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/nginx <unknown>/50% 1 3 1 31s
2
3
4
5
6
接下里我们进入模拟环节,我们重新打开一个终端,原有终端链接不要断开,连接master节点,进入pod内部,并执行以下命令
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
get-configmap 1/1 Running 2 (25d ago) 26d
nginx-54986548c9-t8k69 1/1 Running 0 5m31s
[root@master ~]# kubectl exec -it nginx-54986548c9-t8k69 bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
#执行以下命令
root@nginx-54986548c9-t8k69:/# cat /dev/zero > /dev/null
2
3
4
5
6
7
8
9
然后切换到原有终端查看pod使用率,如果没有数据,请等待一段时间
[root@master ~]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-85b98978db-h9bss 688m 3Mi
2
3
可以看到nginx的pod的CPU使用率已经越来越高,等待一段时间以后,再次查看pod数量
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-54986548c9-b69ht 1/1 Running 0 46s
nginx-54986548c9-t8k69 1/1 Running 0 2m38s
nginx-54986548c9-zn9gb 1/1 Running 0 46s
2
3
4
5
可以看到,nginx的pod数量已经扩容到了3个,这刚刚是我们部署HPA的最大副本数.
接下来,我们将刚刚那个pod杀死
[root@master ~]# kubectl delete pod nginx-54986548c9-t8k69
pod "nginx-54986548c9-t8k69" deleted
2
3
等待大概5分钟左右,再次查看pod数量,发现pod数量已经开始逐渐减少
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-54986548c9-b69ht 1/1 Running 0 7m56s
nginx-54986548c9-zn9gb 1/1 Running 0 7m56s
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
get-configmap 1/1 Running 2 (25d ago) 27d
nginx-54986548c9-b69ht 1/1 Running 0 8m45s
2
3
4
5
6
7
8
另外一种方式,我们可以直接使用以下命令来创建HPA,具体参数可以查看kubectl autoscale --help
kubectl autoscale deploy nginx --min=1 --max=3 --cpu-percent=50 --name=nginx-hpa
第八章 Service
前面的所有示例中,我们从来没有讨论过pod是如何被外接访问的,接下来就说一下pod被外接访问的规则.
Service简称(svc)是Kubernetes一个非常重要的概念,作用就是作为一个代理服务器将pod内部的服务发布出去.这样请求端就只需记住相应的svc服务名称即可,而无需关心背后的pod的真实IP地址是什么在哪个node节点.
通常情况下,集群内部pod之间相互访问都是访问对方的svc,整体请求流程如下
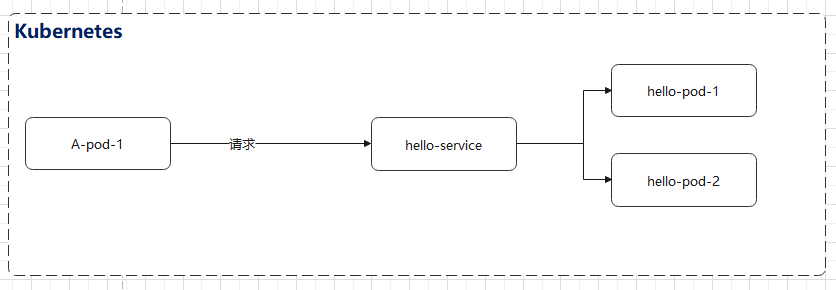
Service会将请求流量依次转发给后端的pod,这就起到了一个负载均衡的功能.所以整体来说Service起到了服务发现与负载均衡的作用
1. 查看
使用命令kubectl get svc -n 命名空间来查看svc
[root@master ~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46d
2
3
可以看到default命名空间下存在kubernetes的svc
查看该svc具体的详细信息
[root@master ~]# kubectl describe svc kubernetes
Name: kubernetes
Namespace: default
Labels: component=apiserver
provider=kubernetes
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.96.0.1
IPs: 10.96.0.1
Port: https 443/TCP
TargetPort: 6443/TCP
Endpoints: 192.168.137.46:6443
Session Affinity: None
Events: <none>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2. 创建
创建Service使用以下yaml
apiVersion: v1
kind: Service
metadata:
name: svc-nginx
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 80
nodePort: 30066
targetPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
我首先利用这个文件来创建一个svc
[root@master ~]# kubectl apply -f nginx-service.yaml
service/svc-nginx created
[root@master ~]# kubectl get svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46d <none>
svc-nginx NodePort 10.110.327.150 <none> 80:30066/TCP 4s app=nginx
[root@master ~]#
2
3
4
5
6
7
可以看到svc创建成功了,所以svc的创建并没有依赖任何控制器或者pod.接下来,我们在创建一个nginx的pod
使用以下文件
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx-service-demo
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx-service-demo
ports:
- containerPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
[root@master ~]# kubectl apply -f nginx-service-pod.yaml
pod/nginx-service-demo created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-service-demo 1/1 Running 0 3s
[root@master ~]#
2
3
4
5
6
接下来我们进入nginx-service-demo这个pod,更改index.html的内容为from server
[root@master ~]# kubectl exec -it nginx-service-demo bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-service-demo:/# cat > usr/share/nginx/html/index.html << EOF
from server
EOF
root@nginx-service-demo:/# cat usr/share/nginx/html/index.html
from server
2
3
4
5
6
7
然后我们在临时创建一个nginx pod,名为nginx-client
[root@master ~]# kubectl run nginx-client --image=nginx --image-pull-policy=IfNotPresent
pod/nginx-client created
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-client 1/1 Running 0 10s
nginx-service-demo 1/1 Running 0 19m
2
3
4
5
6
可以看到现在存在两个nginx的pod,一个nginx-client,一个nginx-service-demo,现在集群的内部如下:
现在我们进入到nginx-client内部,使用命令curl svc-nginx
[root@master ~]# kubectl exec -it nginx-client bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-client:/# curl svc-nginx
from server
root@nginx-client:/#
2
3
4
5
大家发现什么了吗?该命令返回了from server,正式我更改的nginx-service-demo的index.html文件!
然后我们在创建一个nginx-service-demo2的pod
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: nginx-service-demo2
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx-service-demo2
ports:
- containerPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
现在的集群内部情况如下
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-client 1/1 Running 0 168m 172.16.104.20 node2 <none> <none>
nginx-service-demo 1/1 Running 0 3h6m 172.16.104.9 node2 <none> <none>
nginx-service-demo2 1/1 Running 0 1s 172.16.166.150 node1 <none> <none>
2
3
4
5
进入到nginx-service-demo2内部,将index.html内容更改成了from server2
[root@master ~]# kubectl exec -it pod/nginx-service-demo2 bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-service-demo2:/# cat > usr/share/nginx/html/index.html << EOF
from server2
EOF
root@nginx-service-demo2:/# cat usr/share/nginx/html/index.html
from server2
2
3
4
5
6
7
现在集群内容情况如下

我们回到client内部,在多次使用curl svc-nginx看一下效果
[root@master ~]# kubectl exec -it nginx-client bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@nginx-client:/# curl svc-nginx
from server
root@nginx-client:/# curl svc-nginx
from server2
root@nginx-client:/#
2
3
4
5
6
7
可以看到,第一次返回from server,第二次返回from server2.这就是svc的负载均衡与服务发现的能力.那么svc如何具有服务发现的能力呢?
svc通过节点selector属性来绑定具有相同标签的pod,也就是绑定具有app: nginx标签的pod
#svc
...
...
selector:
app: nginx
...
...
#pod
...
...
metadata:
labels:
app: nginx
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2. type
svc的类型一种有三种类型
1. NodePort
...
...
spec:
type: NodePort
...
...
2
3
4
5
6
该类型的svc会在每个node节点都开上都开启nodePort端口号,访问集群中任意的节点该端口号,都可以访问该服务
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-client 1/1 Running 0 145m 172.16.104.20 node2 <none> <none>
nginx-service-demo 1/1 Running 0 164m 172.16.104.9 node2 <none> <none>
nginx-service-demo2 1/1 Running 0 126m 172.16.166.150 node1 <none> <none>
#我们先将nginx-service-demo2这个pod删除
[root@master ~]# kubectl delete -f nginx-service-demo2.yaml
pod "nginx-service-demo2" deleted
#可以看到现在只有一个nginx-service-demo的pod了
[root@master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-client 1/1 Running 0 148m 172.16.104.20 node2 <none> <none>
nginx-service-demo 1/1 Running 0 167m 172.16.104.9 node2 <none> <none>
2
3
4
5
6
7
8
9
10
11
12
13
然后我们通过浏览器访问http://node1:30066与http://node2:30066看一下效果
可以看到都能访问到这个pod
2. ClusterIP
默认值,是Kubernetes集群给给Service的自动分配的虚拟IP,该IP只能在集群内部访问.这个虚拟IP(VIP)通常情况下是没有办法ping通的,因为这个VIP不是一个真实的实体网络来响应
通常情况我们不会直接使用这个VIP地址,而是使用对方ServiceName服务名称请求访问.比如下图
3. LoadBalancer
该类型的svc通常是一些云服务厂商会提供该接口,会为该类型的svc提供一个公网的IP.从来将我们的服务公布在互联网上.如下图是我司的Kong网关,为EXTERNAL-IP提供了一个公网IP.

通常我们不会直接使用该公网IP,而是会在网关前面加上一个SLB即负载均衡器,比如下图
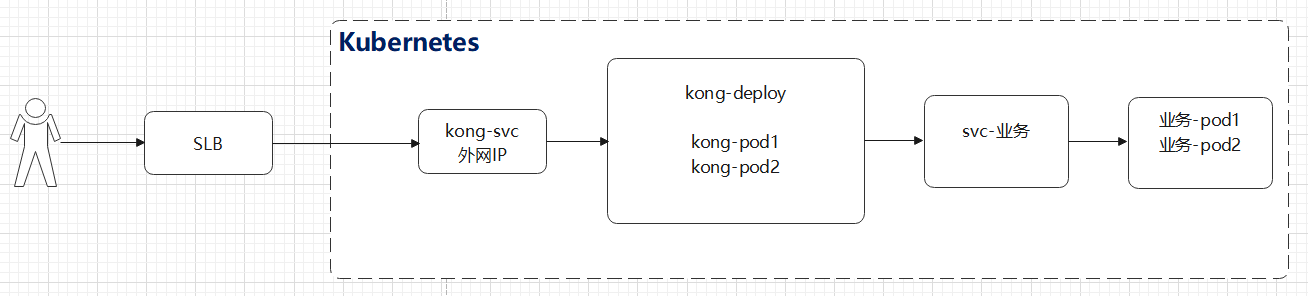
3. ports
在yaml文件中,我们看到ports节点下有三个端口
...
...
ports:
- protocol: TCP
port: 80
nodePort: 30066
targetPort: 80
2
3
4
5
6
7
那么这三个端口都是用来做什么的呢?
- targetPort:就是后端容器的端口,比如我们nginx使用的就是80端口
- nodePort:就是这个pod所在node节点上的端口,端口范围:30000-32767,如果不指定该参数,则会随机使用一个端口
- port:集群中服务互相访问的端口.
如下图
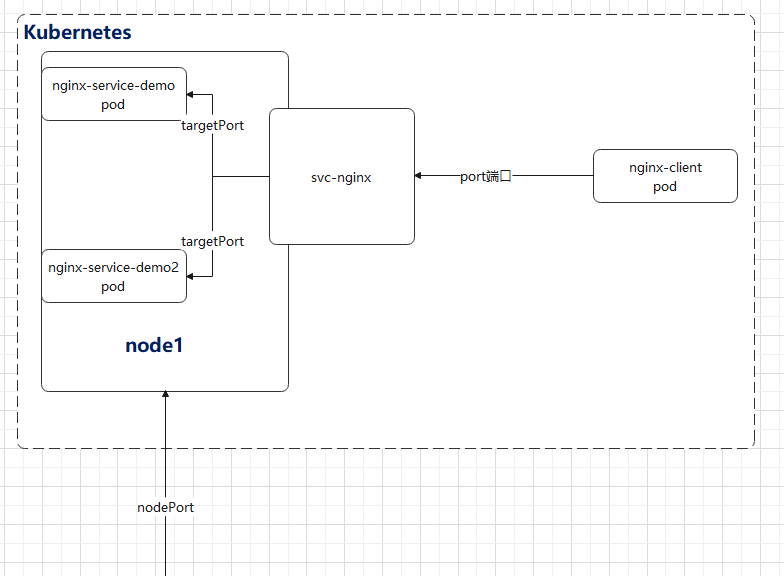
集群内部svc相互访问受限于namespace,处于相同namespace的服务可以直接使用svc进行通讯,不同namespace的服务,需要指定namespace.格式如下:
svc-nginx.default
也就是在svc名称后面增加一个**.namespace**;
5. Ingress Controller
Ingress是Kubernetes的一个对象,通过该对象,我们可以实现访问集群内部的统一入口Ingress具有反向代理和负载均能的能力,可以简单的比喻为就像是nginx的反向代理
请求示例
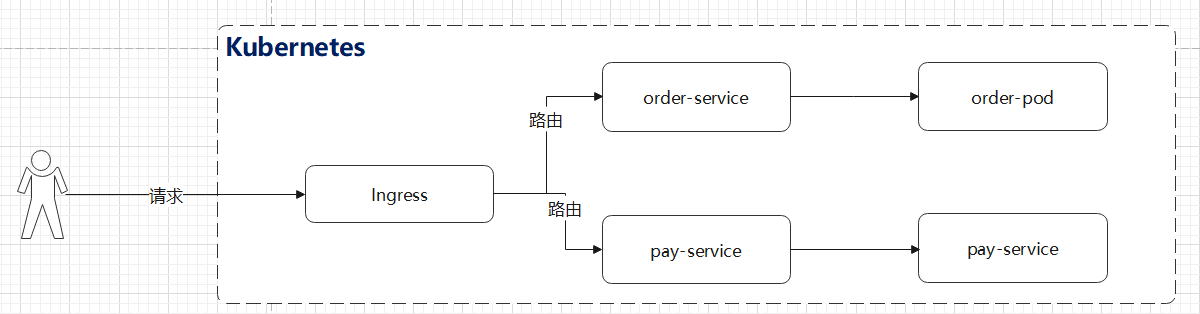
目前Kubernetes支持和维护AWS、 GCE 和 Nginx Ingress 控制器
1. 安装
我们在集群中安装Nginx Inregss,可以在官方网站中,寻找yaml文件:Installation Guide - NGINX Ingress Controller (kubernetes.github.io),在githubkubernetes/ingress-nginx: NGINX Ingress Controller for Kubernetes (github.com),查看各版本与Kubernetes版本兼容的情况
#查看集群版本
[root@master ~]# kubectl version
Client Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.3", GitCommit:"816c97ab8cff8a1c72eccca1026f7820e93e0d25", GitTreeState:"clean", BuildDate:"2022-01-25T21:25:17Z", GoVersion:"go1.17.6", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"23", GitVersion:"v1.23.1", GitCommit:"86ec240af8cbd1b60bcc4c03c20da9b98005b92e", GitTreeState:"clean", BuildDate:"2021-12-16T11:34:54Z", GoVersion:"go1.17.5", Compiler:"gc", Platform:"linux/amd64"}
2
3
4
因为部署文件中包含镜像源k8s.gcr.io国内无法访问,所以我们需要将部署文件保存到本地,然后替换镜像源
将k8s.gcr.io替换成registry.aliyuncs.com/google_containers
第九章 监控
在早期的Kubernetes(v1.11以前)的版本内置了heapster组件,不过该组件已经被废弃,内置监控则由metics-server负责.

在第七章 自动伸缩章节中,我们在集群中部署了一个metics-server组件,metics-server负责去kubelet上抽取数据.metics-server也有局限性,仅提供Node和Pod的CPU和内存使用情况,其他的Custom Metrics(自定义指标),则由社区与其他组件来完成.
1. Prometheus

Prometheus是开源的监控与度量组件,2016年加入了CNCF云原生计算基金会,2018年进入毕业状态.以下是官方给出的架构图
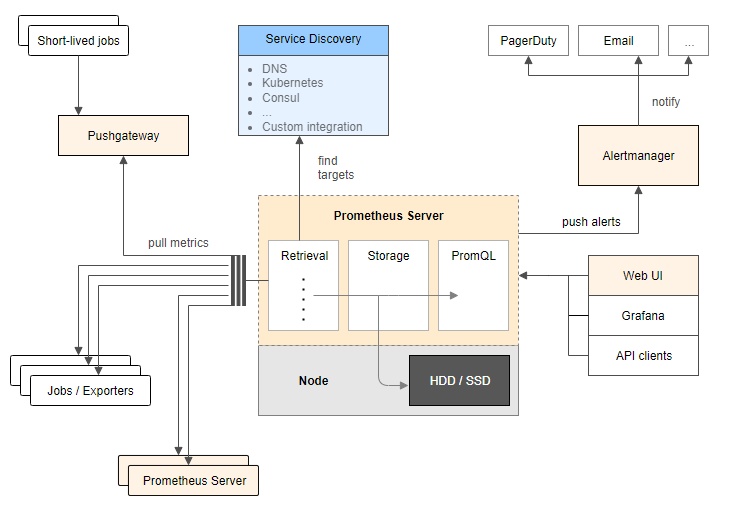
为了研发同学便于理解,用一句话概括就是Prometheus内置了一个时序数据库,targets为被监控的目标,Prometheus会定时的去targets拉取数据,然后存储到内部.然后我们通过Grafana进行数据可视化,自定义监控指标,当达标阈值后,通过Alertmanager进行报警.
2. 安装
在Kubernetes集群部署Prometheus有两种方案,prometheus-operator与kube-prometheus
prometheus-operator提供Prometheus和相关监控组件的 Kubernetes 原生部署和管理。该项目的目的是简化和自动化基于 Prometheus的Kubernetes集群的监控部署
kube-prometheus提供了一个完成整的集群监控示例与配置,并且内置了针对集群的alert与record rule,内置了grafana看板.可一键部署Prometheus的所有组件.接下来我们就使用kube-prometheus来在集群中部署Prometheus.
kube-prometheus版本兼容性
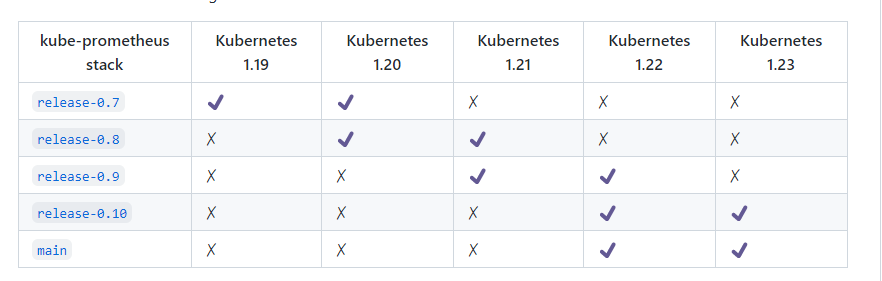
**1. ** 克隆kube-prometheus
[root@master ~]# git clone https://github.com/prometheus-operator/kube-prometheus.git
Cloning into 'kube-prometheus'...
remote: Enumerating objects: 15559, done.
remote: Counting objects: 100% (245/245), done.
remote: Compressing objects: 100% (124/124), done.
remote: Total 15559 (delta 157), reused 159 (delta 108), pack-reused 15314R
Receiving objects: 100% (15559/15559), 7.79 MiB | 2.30 MiB/s, done.
Resolving deltas: 100% (9915/9915), done.
2
3
4
5
6
7
8
2. ** 进入到manifests**目录,所有安装文件都在该目录下
├── manifests
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-podDisruptionBudget.yaml
│ ├── alertmanager-prometheusRule.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-serviceAccount.yaml
│ ├── alertmanager-serviceMonitor.yaml
│ ├── alertmanager-service.yaml
│ ├── blackboxExporter-clusterRoleBinding.yaml
│ ├── blackboxExporter-clusterRole.yaml
│ ├── blackboxExporter-configuration.yaml
│ ├── blackboxExporter-deployment.yaml
│ ├── blackboxExporter-serviceAccount.yaml
│ ├── blackboxExporter-serviceMonitor.yaml
│ ├── blackboxExporter-service.yaml
│ ├── grafana-config.yaml
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-prometheusRule.yaml
│ ├── grafana-serviceAccount.yaml
│ ├── grafana-serviceMonitor.yaml
│ ├── grafana-service.yaml
│ ├── kubePrometheus-prometheusRule.yaml
│ ├── kubernetesControlPlane-prometheusRule.yaml
│ ├── kubernetesControlPlane-serviceMonitorApiserver.yaml
│ ├── kubernetesControlPlane-serviceMonitorCoreDNS.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubelet.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
│ ├── kubeStateMetrics-clusterRoleBinding.yaml
│ ├── kubeStateMetrics-clusterRole.yaml
│ ├── kubeStateMetrics-deployment.yaml
│ ├── kubeStateMetrics-prometheusRule.yaml
│ ├── kubeStateMetrics-serviceAccount.yaml
│ ├── kubeStateMetrics-serviceMonitor.yaml
│ ├── kubeStateMetrics-service.yaml
│ ├── nodeExporter-clusterRoleBinding.yaml
│ ├── nodeExporter-clusterRole.yaml
│ ├── nodeExporter-daemonset.yaml
│ ├── nodeExporter-prometheusRule.yaml
│ ├── nodeExporter-serviceAccount.yaml
│ ├── nodeExporter-serviceMonitor.yaml
│ ├── nodeExporter-service.yaml
│ ├── prometheusAdapter-apiService.yaml
│ ├── prometheusAdapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheusAdapter-clusterRoleBindingDelegator.yaml
│ ├── prometheusAdapter-clusterRoleBinding.yaml
│ ├── prometheusAdapter-clusterRoleServerResources.yaml
│ ├── prometheusAdapter-clusterRole.yaml
│ ├── prometheusAdapter-configMap.yaml
│ ├── prometheusAdapter-deployment.yaml
│ ├── prometheusAdapter-podDisruptionBudget.yaml
│ ├── prometheusAdapter-roleBindingAuthReader.yaml
│ ├── prometheusAdapter-serviceAccount.yaml
│ ├── prometheusAdapter-serviceMonitor.yaml
│ ├── prometheusAdapter-service.yaml
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheusOperator-clusterRoleBinding.yaml
│ ├── prometheusOperator-clusterRole.yaml
│ ├── prometheusOperator-deployment.yaml
│ ├── prometheusOperator-prometheusRule.yaml
│ ├── prometheusOperator-serviceAccount.yaml
│ ├── prometheusOperator-serviceMonitor.yaml
│ ├── prometheusOperator-service.yaml
│ ├── prometheus-podDisruptionBudget.yaml
│ ├── prometheus-prometheusRule.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-serviceAccount.yaml
│ ├── prometheus-serviceMonitor.yaml
│ ├── prometheus-service.yaml
│ └── setup
│ ├── 0alertmanagerConfigCustomResourceDefinition.yaml
│ ├── 0alertmanagerCustomResourceDefinition.yaml
│ ├── 0podmonitorCustomResourceDefinition.yaml
│ ├── 0probeCustomResourceDefinition.yaml
│ ├── 0prometheusCustomResourceDefinition.yaml
│ ├── 0prometheusruleCustomResourceDefinition.yaml
│ ├── 0servicemonitorCustomResourceDefinition.yaml
│ ├── 0thanosrulerCustomResourceDefinition.yaml
│ └── namespace.yaml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
3. 首选创建命名空间
[root@master kube-prometheus-main]# kubectl apply -f manifests/setup/namespace.yaml
namespace/monitoring created
2
4. 部署安装文件
[root@master kube-prometheus-main]# kubectl apply --server-side -f manifests/setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied
namespace/monitoring serverside-applied
2
3
4
5
6
7
8
9
10
5. 因为国内无法直接访问镜像源k8s.gcr.io,在每个node节点上需要手动拉取相关镜像,并会用tag进行更改标签
检查mainfests目录下的两个deployment文件:kubeStateMetrics-deployment.yaml与prometheusAdapter-deployment.yaml的相关镜像版本号与镜像拉取策略是否为imagePullPolicy: IfNotPresent
通常来说以下三个镜像需要懂手动从DockerHub进行拉取,如果有其他镜像下载不了的,也可以使用此方法
docker pull selina5288/prometheus-adapter:v0.9.1
docker image tag selina5288/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1
docker rmi selina5288/prometheus-adapter:v0.9.1
2
3
docker pull bitnami/kube-state-metrics:2.4.2
docker image tag bitnami/kube-state-metrics:2.4.2 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.4.2
docker rmi bitnami/kube-state-metrics:2.4.2
2
3
docker pull serialt/prometheus-config-reloader:v0.55.0
docker image tag serialt/prometheus-config-reloader:v0.55.0 quay.io/prometheus-operator/prometheus-config-reloader:v0.55.0
docker rmi serialt/prometheus-config-reloader:v0.55.0
2
3
然后执行部署命令
[root@master kube-prometheus-main]# kubectl apply -f manifests/
6. 暴漏服务
可以看到所有的svc均为ClusterIP,这样我们没办法访问,所以我将三个核心服务的dashboard暴漏相关端口
[root@master ~]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.103.80.87 <none> 9093/TCP,8080/TCP 21h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 21h
blackbox-exporter ClusterIP 10.105.194.181 <none> 9115/TCP,19115/TCP 21h
grafana ClusterIP 10.104.135.57 <none> 3000/TCP 21h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 21h
node-exporter ClusterIP None <none> 9100/TCP 21h
prometheus-adapter ClusterIP 10.110.154.125 <none> 443/TCP 21h
prometheus-k8s ClusterIP 10.111.81.199 <none> 9090/TCP,8080/TCP 21h
prometheus-operated ClusterIP None <none> 9090/TCP 21h
prometheus-operator ClusterIP None <none> 8443/TCP 21h
2
3
4
5
6
7
8
9
10
11
12
使用kubectl edit svc命令修改三个svc,将类型更改为NodePort
- kubectl edit svc/prometheus-k8s -n monitoring
- kubectl edit svc/grafana -n monitoring
- kubectl edit svc/alertmanager-main -n monitoring
[root@master ~]# kubectl get svc -n monitoring | grep NodePort
alertmanager-main NodePort 10.103.80.87 <none> 9093:32603/TCP,8080:31578/TCP 21h
grafana NodePort 10.104.135.57 <none> 3000:31849/TCP 21h
prometheus-k8s NodePort 10.111.81.199 <none> 9090:30211/TCP,8080:30359/TCP 21h
2
3
4
访问node节点的相关端口,可以看到Prometheus面板已经成功访问
我们直接使用命令来查看一下每个pod的cpu使用情况
sum(rate(container_cpu_usage_seconds_total{image!="", pod!=""}[1m] )) by (pod)
接下来,我们使用使用Grafana来渲染监控数据,访问端口http://node1:31849
先测试一下Data Source是否成功
然后查看相关的看板
我们看一下Kubernetes / Compute Resources / Pod看板
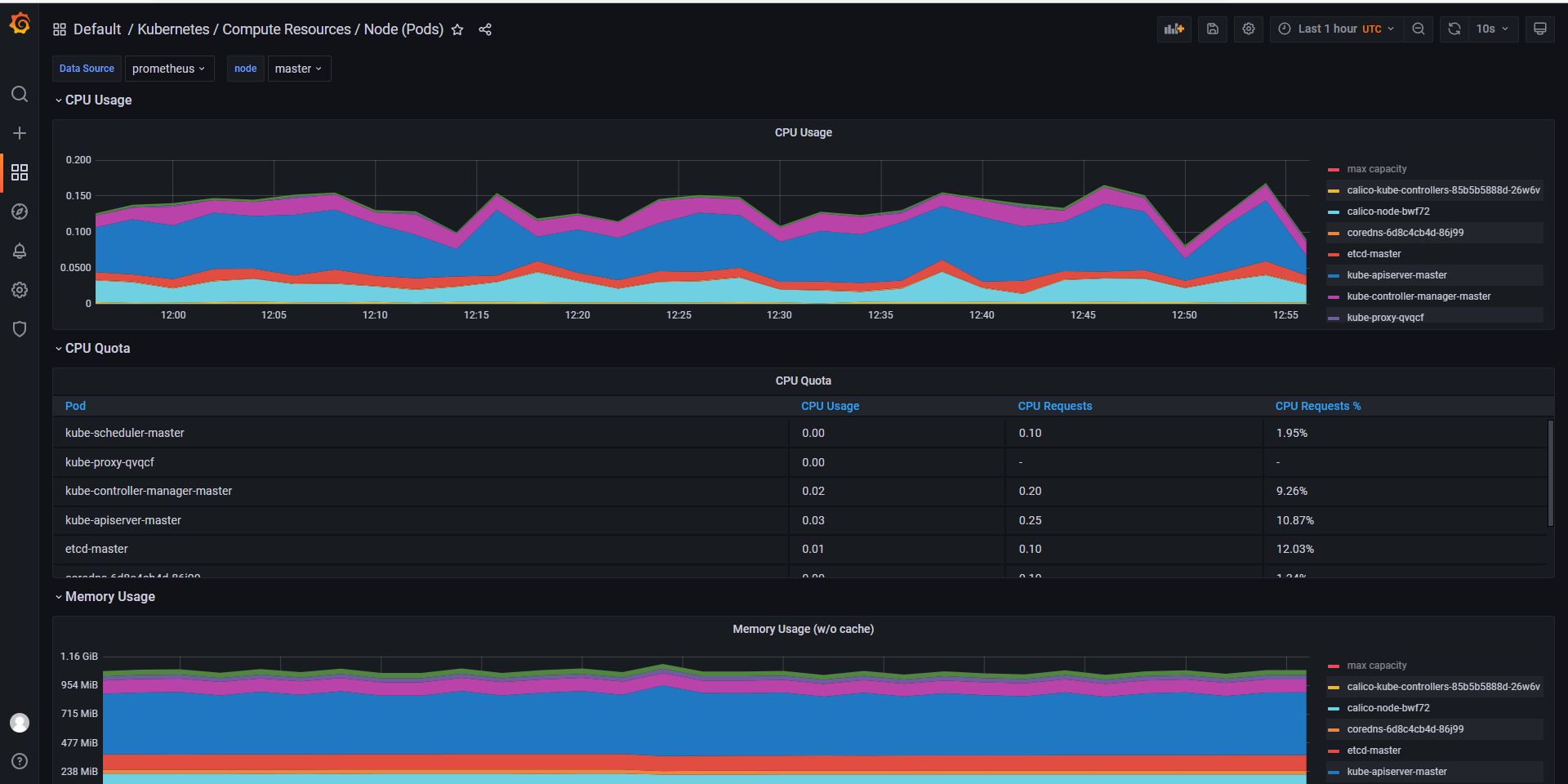
其他看板各位同学可以自行研究.
3. 卸载
如果想要全部卸载,使用命令
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
第十章 可视化管理
1. Kubernetes Dashboard
Kubernetes Dashboard是Kubernetes集群的Web UI,用户可以通过Dashboard进行管理集群内所有资源对象,例如查看资源对象的运行情况,部署新的资源对象,伸缩Deployment中的Pod数量等等一系列操作。官方库:https://github.com/kubernetes/dashboard
可以直接使用以下命令进行安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml
如果出现解析域名失败,也可以下载文件后,使用基于本地文件安装,dashboard部署在命名空间kubernetes-dashboard下
[root@master ~]# kubectl apply -f dashboard.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
[root@master ~]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-799d786dbf-z4bwl 1/1 Running 0 14m
kubernetes-dashboard-fb8648fd9-thvtj 1/1 Running 0 14m
[root@master ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.96.39.194 <none> 8000/TCP 21m
kubernetes-dashboard ClusterIP 10.103.29.152 <none> 443/TCP 21m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
可以看到kubernetes-dashboard的svc使用的类型是ClusterIP,所以我们无法通过外部访问,所以我们需要编辑该svc
[root@master ~]# kubectl edit service kubernetes-dashboard -n kubernetes-dashboard
# 定位到33行,将ClusterIP更改成NodePort
30 selector:
31 k8s-app: kubernetes-dashboard
32 sessionAffinity: None
33 type: NodePort
34 status:
35 loadBalancer: {}
2
3
4
5
6
7
8
创建Service Account与ClusterRoleBinding
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
[root@master ~]# kubectl apply -f sa.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
2
3
使用以下命令生成访问集群的token
[root@master ~]# kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
Name: admin-user-token-dmlhh
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 9a2bdbff-bbf1-44ba-abd1-acd270010f65
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1099 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjQ0bjlCSDZiOGM0ejR3akpoZDlkV0pZZU5iRWtQY0RkVnB5b3ctRnVrdzAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWRtbGhoIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI5YTJiZGJmZi1iYmYxLTQ0YmEtYWJkMS1hY2QyNzAwMTBmNjUiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.GpFdmNAJOnm5nS3ZDZ8Cjprv8BAATR4_MAMxu0vLqyb-TGnwHZGkFRaOX4EgTP9U_hkjkZ4MtcA51qFaMlC18okOZBPFA58dcWmQ47hdPQuQuNpS2cKQ7E_5It7B4tkTMiu0K4gbCyZI0U82IpHgggAD6nP3ZM0xC7AZ93hZtKGSN5-Anq9l6or-DCYW5a6N6cBjoDEkTh-pAveoydp0vTJX_IbUuh7AIdW29gxJiDke3t11_GPZYLEfiqwnSFk5W_t4Tqqns7r7d2NKk6MxcFswQp2IFCu8lXgXIdDLXtl5Fwjmho_NcBs0hUNCgzdfwuMCIDRtL-pwFcU-xD6daA
2
3
4
5
6
7
8
9
10
11
12
13
14
访问https://node1:31811/#/login,这里需要使用https放问,并把上面生成的token输入
这时可以看到整个集群的状况
2. Rancher

Rancher是笔者比较喜欢的一款用来管理Kubernetes的工具,官网https://www.rancher.cn/products.官方对Rancher的定义
提供Kubernetes即服务(Kubernetes-as-a-Service)
Rancher开源,且有两个版本,社区办与企业版,中小团队使用社区办已经足够.
Rancher安装也非常简单
[root@cd ~]# docker run -d --restart=always --privileged -p 80:80 -p 443:443 rancher/rancher