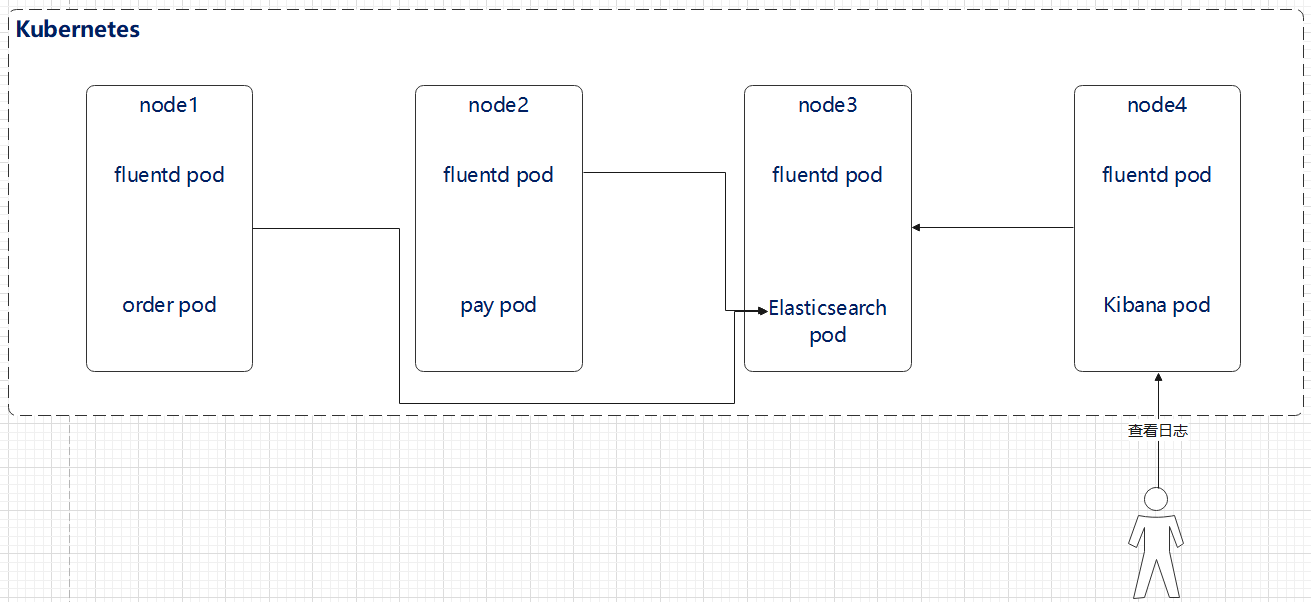
第三部分 asp.netcore on kubernetes
在本部门,我们将使用asp.netcore结合CI/CD来构建完成的云原生架构环境.实现网关自动注册与发现,自动伸缩等.
第一章 节点规划
在原有虚拟机上我们在增加一台服务器,用来做代码库以及CI/CD服务与某些中间件.整体服务器规划如下,并在每台服务器中配置hosts解析.
| 系统 | 节点 | 用途 | IP | 规格 |
|---|---|---|---|---|
| centos8 | master | 主节点 | 192.168.137.46 | 2核,3G |
| centos8 | node1 | 工作节点 | 192.168.137.147 | 2核,3G |
| centos8 | node2 | 工作节点 | 192.168.137.18 | 2核,3G |
| centos8 | cd | CI/CD及数据库与中间件 | 192.168.137.81 | 2核,6G |
1. 部署数据库
数据库的选择在大多数场景下有两种
- MS SQL Server
- My SQL
基于生态原因,我们先选择My SQL作为我们的数据库.我们使用docker来部署一个My SQL
端口号:3306,用户名:root,密码:123456
docker run -d -p 3306:3306 --restart=always \
-v /usr/local/docker/mysql/conf:/etc/mysql \
-v /usr/local/docker/mysql/logs:/var/log/mysql \
-v /usr/local/docker/mysql/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
-d mysql:5.7
2
3
4
5
6
1. CI/CD选择
CI被称为持续集成(Continuous Integration),CD有两种语义一种是持续交付(Continuous Delivery),另一种是持续部署(Continuous Deployment),持续交付与持续部署意义不同,本文所致为持续部署.
实现CI/CD的工具有很多,比如常用的Jekins,Travis等,本文介绍的工具是大名鼎鼎的JetBrains旗下的Teamcity.
Teamcity有三个版本
- 专业版,该版本为免费的,支持100个构建配置及3个Agent(代理),对于中小型团队足够用了
- 企业版,该版本为收费版本
- Cloud云托管版本
为什么不用Jekins,因为太丑了!而且配置复杂. 相比起来Teamcity有以下优点
- 开箱即用,不需要复杂配置,即可满足功能需求
- 升级简单,只需要升级镜像即可
- UI用户体验好,自带两套UI界面
- Agent原生支持.Net Core与.Net Framework

2. CI/CD部署
Teamcity部署相当容易,只需要执行两个步骤即可
- 部署服务端
- 部署Agent端
1. 部署Server
首先部署服务端,该命令挂载了两个本地目录
- /teamcity/datadir 为数据目录,只要有该目录存在,我们更换机器,然后在挂载该目录,依然有效.
- /teamcity/logs 为日志目录
docker run -dit -u=root --privileged --name teamcity-server-instance \
-v /teamcity/datadir:/data/teamcity_server/datadir \
-v /teamcity/logs:/opt/teamcity/logs \
-p 81:8111 \
--restart=always\
jetbrains/teamcity-server
2
3
4
5
6
7
[root@cd ~]# docker run -dit -u=root --privileged --name teamcity-server-instance \
> -v /teamcity/datadir:/data/teamcity_server/datadir \
> -v /teamcity/logs:/opt/teamcity/logs \
> -p 81:8111 \
> --restart=always\
> jetbrains/teamcity-server
b49cc9c3c1125a078a8f613de203166a671d26301c43cc7bbf840f0c08d3bf50
[root@cd ~]#
2
3
4
5
6
7
8
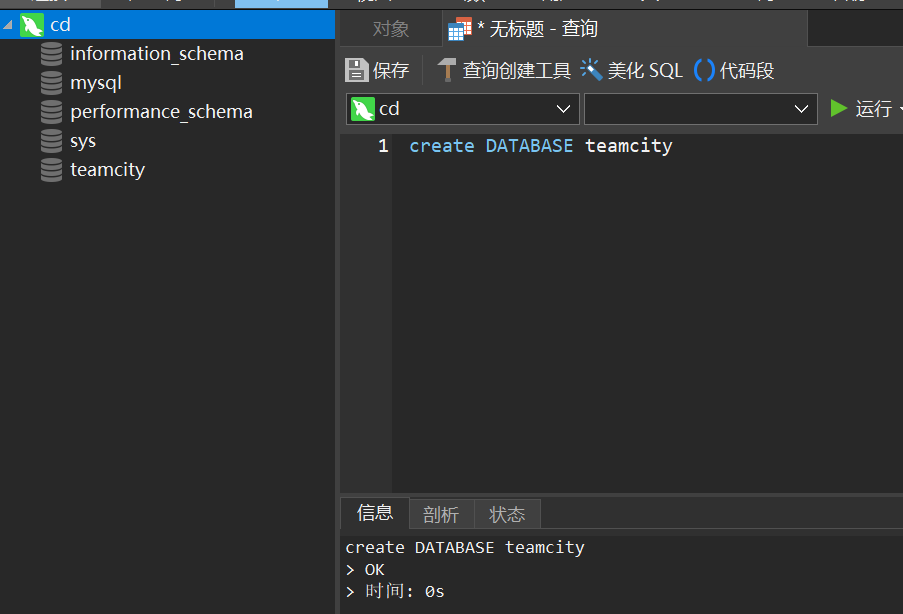
接下来,我们连接MY SQL实例,创建一个数据名为:teamcity
这时候我们访问http://cd:81,可以看到Teamcity的容器已经部署完毕,
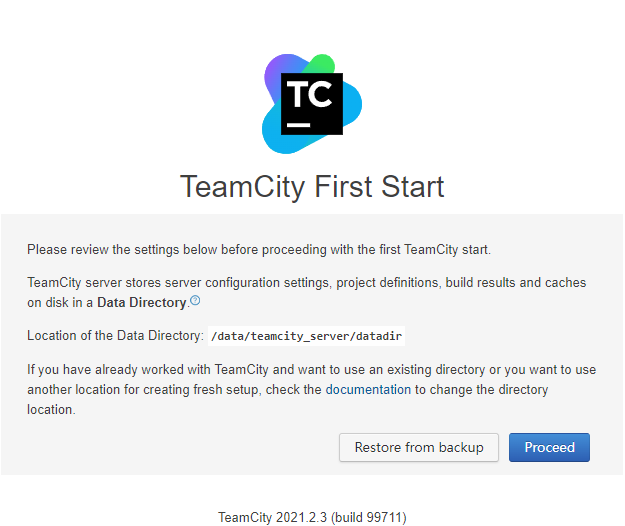
我们点击Proceed,然后出现现则数据库的页面.
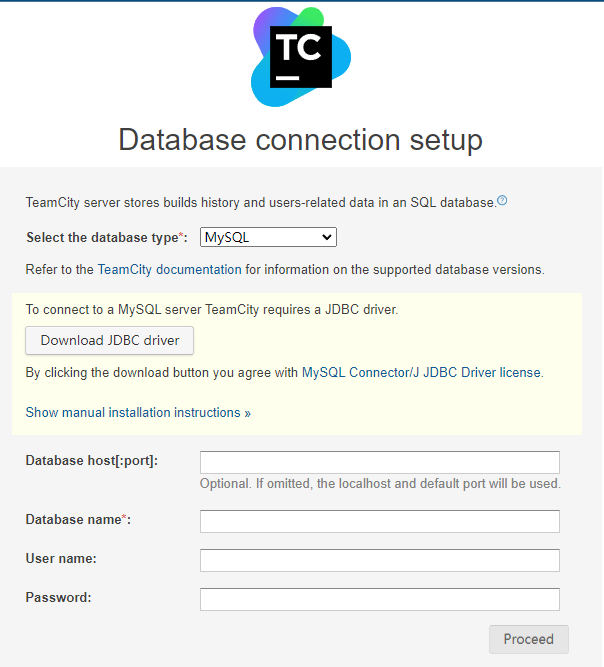
Teamcity需要将数据存储到数据库,Teamcity支持多种数据库,默认为HSQL2,我们将数据库切换成My SQL. 根据提示,我们需要下载JDBC的jar包,下载地址
http://mvnrepository.com/artifact/mysql/mysql-connector-java
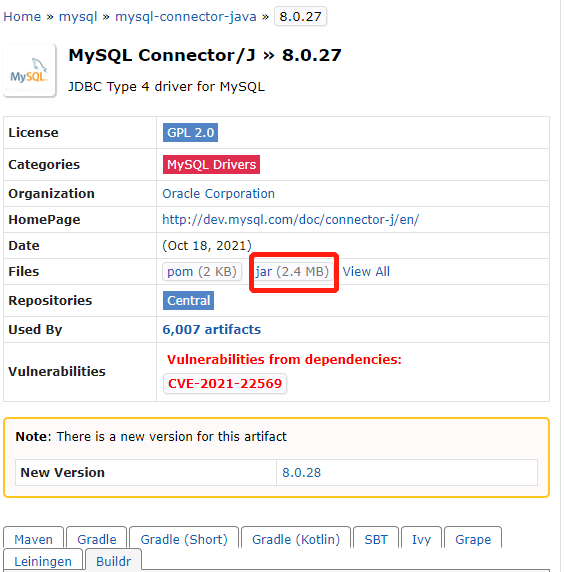
我们将jar包复制到目录**/data/teamcity_server/datadir/lib/jdbc**
[root@cd jdbc]# pwd
/teamcity/datadir/lib/jdbc
[root@cd jdbc]# ls
mysql-connector-java-8.0.27.jar
[root@cd jdbc]#
2
3
4
5
6
然后点击Reresh JDBC driver
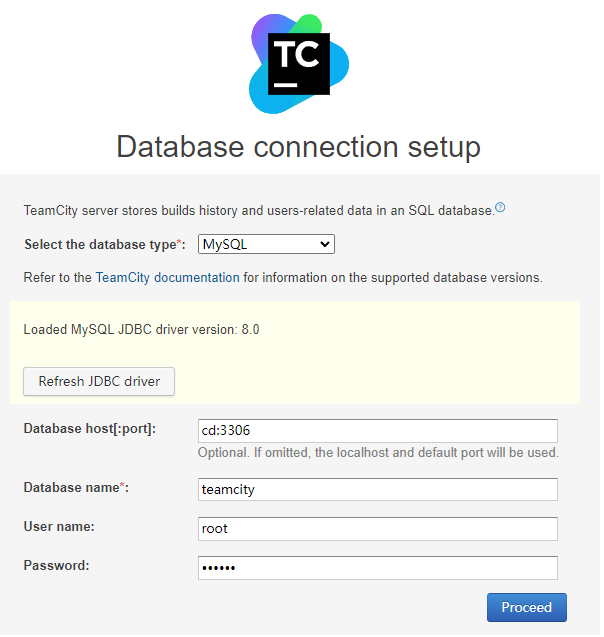
Teamcity已经加载驱动,然后输入刚刚我们创建的数据库即可.初始化完毕以后,设置管理员用户与密码即可
登录以后首页
Teamcity有两套UI,点击有上角的切换按钮,可以进行切换
切换一下
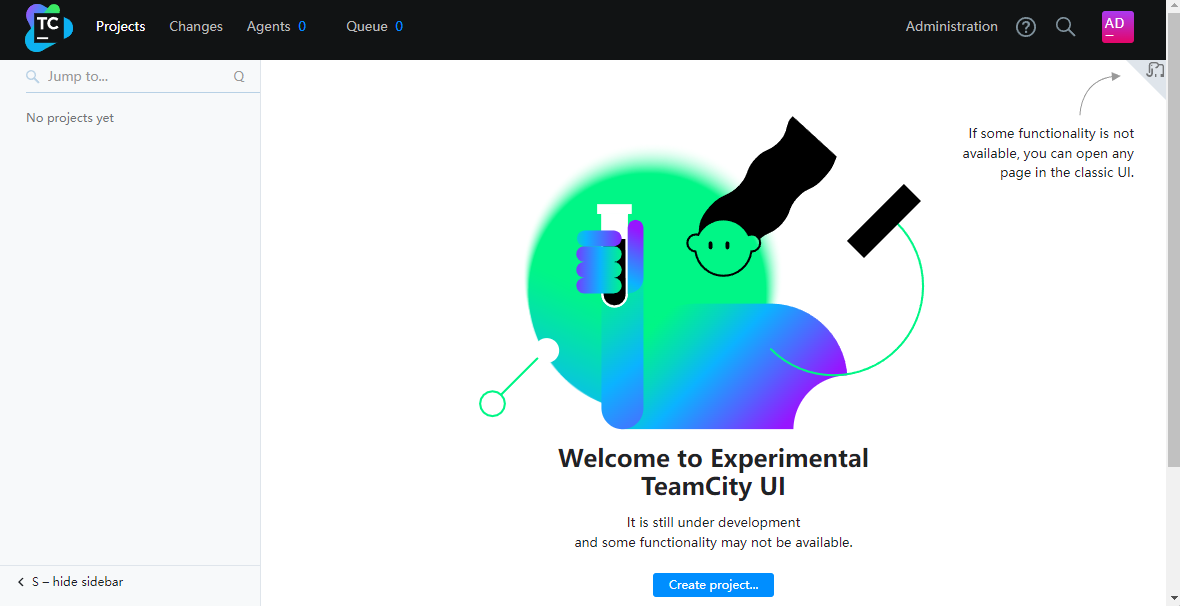
我们来介绍一下一级导航的用途
- Projects: 为我们要构建的项目
- Changes:为我们的代码变更记录,并且显示每次提交的message
- Agents:为构建代理,CI工具本身是不会去构建的,需要靠一个代理程序去编译程序.CI与Agent相互通讯.这种模式包括Jekins,Gitlab Runner都是一样的,通过docker安装的Teamcity没有带有Agent
- Queue:为构建的队列,一个Agent在同一时间只能有一个构建,Teamcity可以有3个免费的Agent,这就是同时可以构建3个项目
2. 部署Agent
然后部署Agent,SERVER_URL为Teamcity服务的地址,AGENT_NAME该Agent的名字
docker run -dit -u=root --privileged -e SERVER_URL='cd:81' -e AGENT_NAME='linux-agent-1' \
-v /proc:/host/proc \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /opt/buildagent/work:/opt/buildagent/work \
-v /opt/buildagent/temp:/opt/buildagent/temp \
-v /opt/buildagent/tools:/opt/buildagent/tools \
-v /opt/buildagent/plugins:/opt/buildagent/plugins \
-v /opt/buildagent/system:/opt/buildagent/system \
--name teamcity-agent-1 \
--restart=always \
jetbrains/teamcity-agent
2
3
4
5
6
7
8
9
10
11
部署完Agent以后,可以在Teamcity看到已经出现一个Agent,状态是未授权,我们进行授权即可
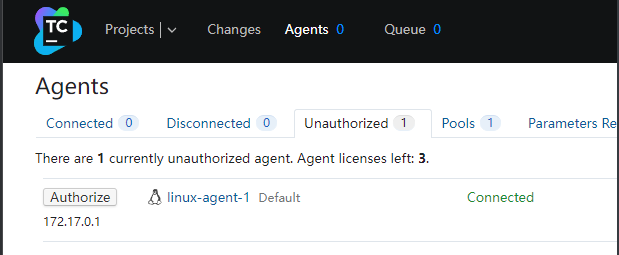
授权后,点击Agent名称,可以看到关于该Agent的详细信息
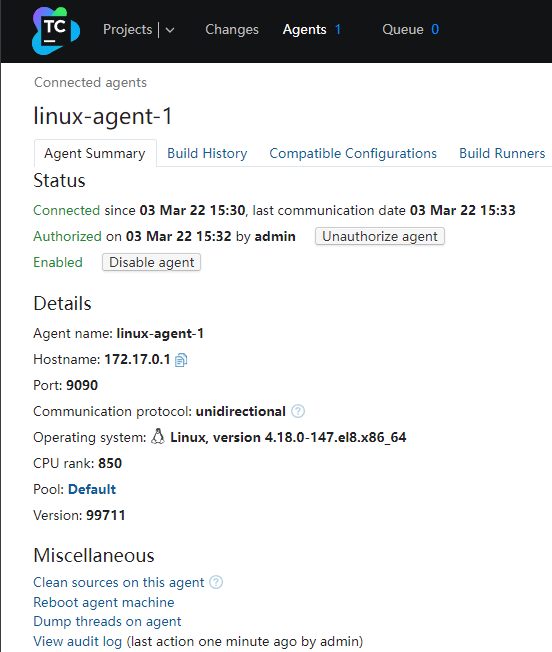
其中关于Build Runners,指的是这个Agent的能力,我们没有在cd这台服务器安装dotnet sdk,但是可以看到Agent已经原生的支持.net项目
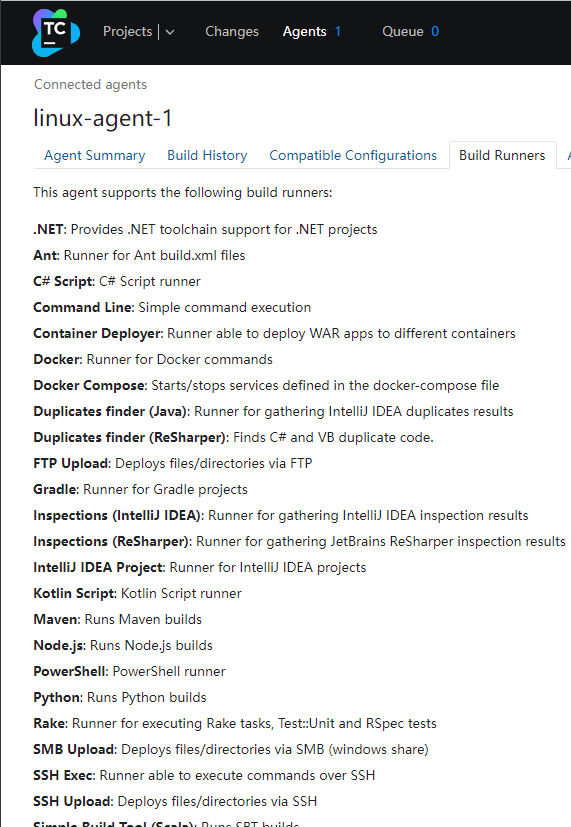
Teamcity工具至此部署完毕.已经处于可用状态
第二章 架构规划
1. 架构图
架构设计没有银弹,受制于公司的业务场景,技术负责人的能力,团队的接受程度等.借助于Kubernetes通常有两种做法
方案一:All in one
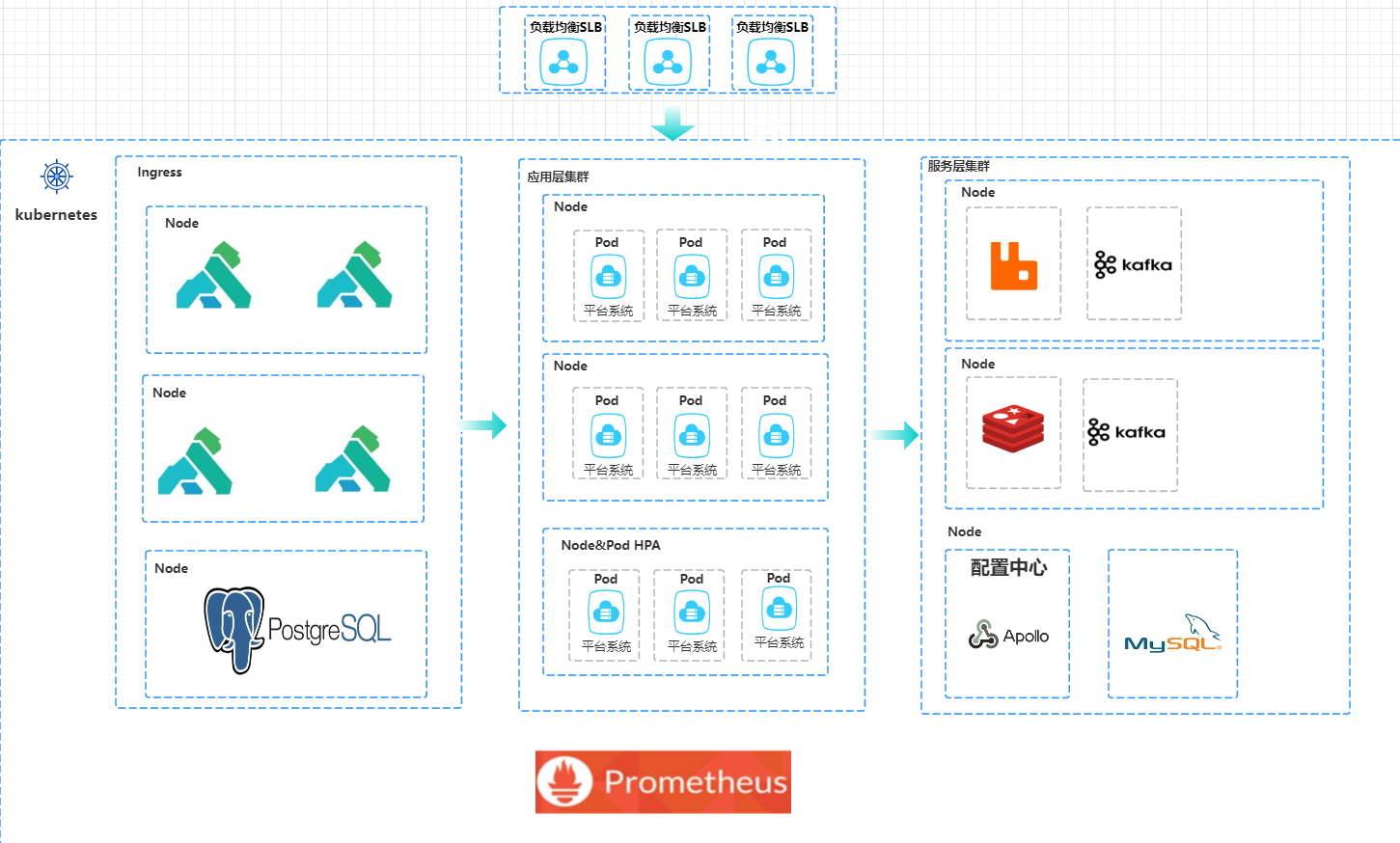
将应用服务与所有组件通通部署到Kubernetes中,借助于Deployment控制器与StatsfulSet控制器来完成该方案.前端应用访问SLB.SLB负责将应用转发到Kubernetes的Kong Ingress上,
方案二:无状态部署
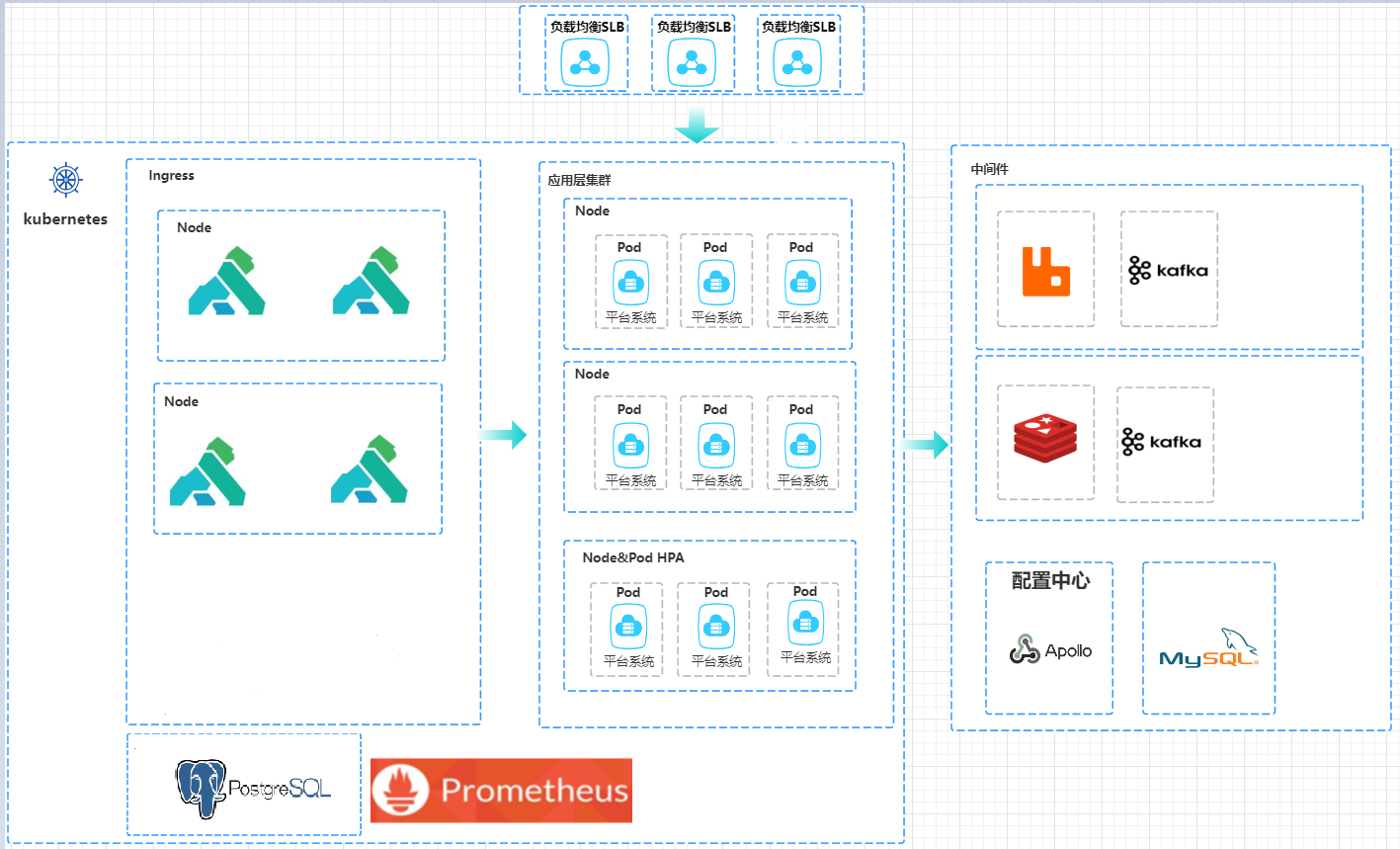
第二种方案Kubernetes只部署无状态的应用服务,其他带有数据持久化的中间件则放到外部.
这两种方案各有利弊,第一种方案需优势是借助于Kubernetes的统一管控能力, 缺点是需要团队具有较强的运维能力,且Kubernetes的网络IO,存储IO,内存管控会成中间件的性能瓶颈.第二种方案比较轻量,因为部署的都是无状态的应用服务,所以整个集群的可控性比较高,即使整个Kubernetes的崩掉了,但是所有数据存储都在外部,我们通过DNS解析,快速将请求流量切换到备用Kubernetes集群.所以我们在本节中只说第二种方案.
2. 服务治理
1. 注册与发现
服务发现主要存在客户端发现与服务端发现两种模式.
1. 客户端发现
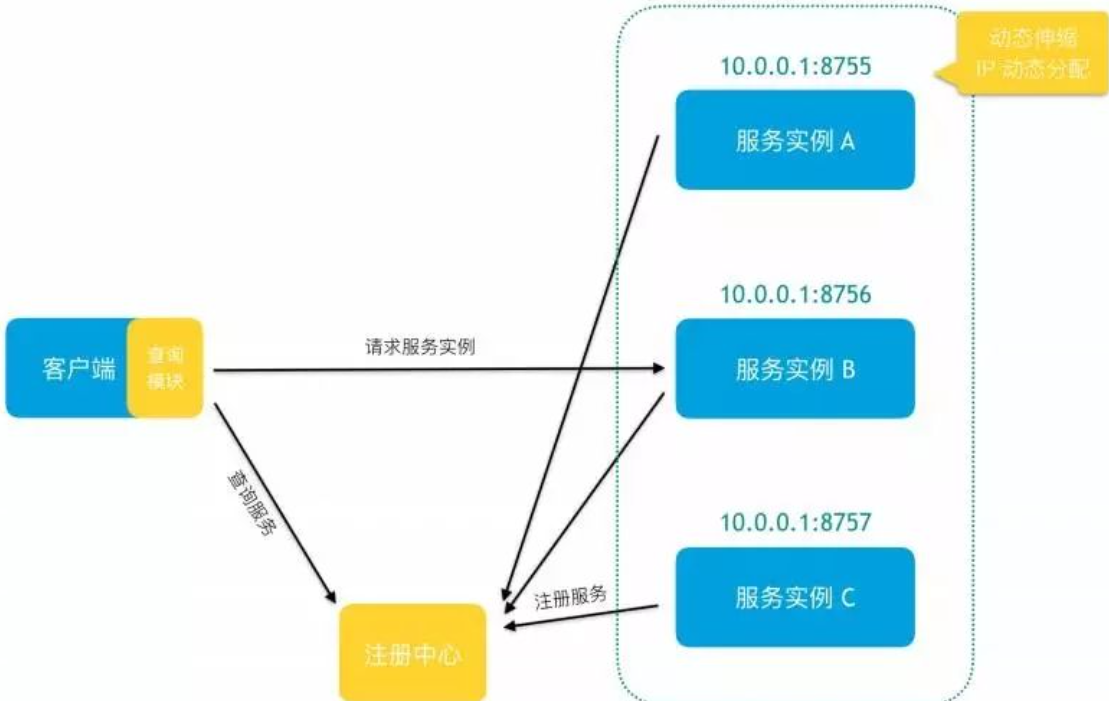
客户端发现模式需要有一个服务注册中心,服务中心管理服务与服务所在的IP与端口的映射.常用的组件有Consul,Nacos等
在该模式下,服务实例启动时,需要向服务注册中心注册,告诉服务注册中心本服务的IP地址与名称.客户端在需要调用该服务的时候,需要向注册中心查询,获得该服务的IP地址,然后通过该IP地址进行远程调用该服务.通常注册服务中心会对注册的服务进行健康检查,对于有问题的服务,会屏蔽该服务的IP地址.
一般服务注册中心都有对服务进行健康检查,如果健康检查不通过,则该服务的IP地址会被屏蔽,客户端就发现不了.
2. 服务端发现
服务端发现基本有两种结构
第一种,会引入网关或者负载均衡器,服务启动时向注册中心注册,网关或者负载均衡器会去服务注册中心查询注册的服务与对应的IP地址.客户端直接向网关或者负载均衡器发起调用,网关或者负载均衡器去请求对应的服务.
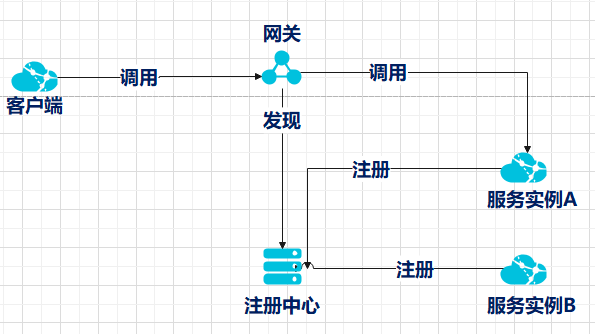
第二种方式,网关内部集成了服务注册与发现的能力.服务启动时向网关进行注册,客户端直接对网关进行调用即可.
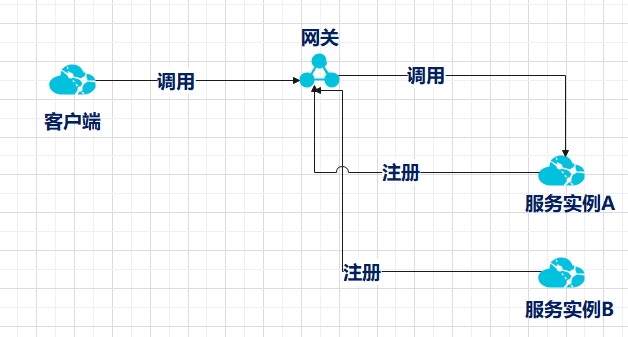
基于这三种方式来说,可以看到第三种的技术复杂度与代码复杂度明显低于前两者,所以我个人比较推荐第三种方式
服务发现这两种模式可以看到客户端发现模式比服务端发现模式多一次请求,所以个人建议使用服务端发现模式.
3. 网关Kong
随着微服务架构的流行,API网关也越来越受欢迎,在微服务体系架构中,跟据业务领域,划分多个服务,服务与服务之间为低耦合,每个服务都可有不同的技术栈进行构建与升级。
API网关可以充当这些服务的入口,客户端不必访问数十个单独的服务。客户端只需将请求发送给API网关即可。
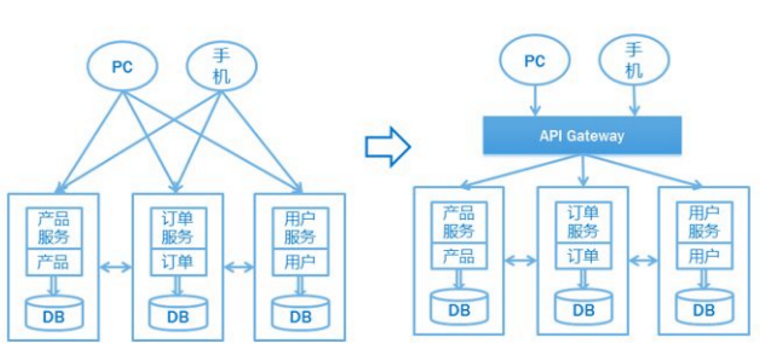
引入网关主要有以下几个好处
- 聚合接口使得服务对调用者透明,客户端与后端的耦合度降低
- 聚合后台服务,节省流量,提高性能,提升用户体验
- 提供安全、流控、过滤、缓存、监控等 API 管理功能
- 提供统一的身份验证
- 进行响应转换
网关的选项是有非常多的选择,如Java系的Spring-cloud Gateway,国产的Apache APISIX,Golang编写且开源的Traefik,asp.netcore平台的Ocelot,还有基于Nginx+Lua编写的Kong等等,
下面我们主要介绍一下Kong.

Nginx是一款非常优秀发的Web服务与反向代理服务器,很多大型互联网公司都会采用Nginx来做代理,千万流量也可胜任.
Kong是一款基于OpenResty(Nginx + Lua模块)编写的高可用、易扩展的,由Mashape公司开源的API Gateway项目.Kong是基于NGINX和Apache Cassandra或PostgreSQL构建的,能提供易于使用的RESTful API来操作和配置API管理系统,所以它可以水平扩展多个Kong服务器,通过前置的负载均衡配置把请求均匀地分发到各个Server,来应对大批量的网络请求,并且Kong自身提供基于REST API,可供我们外部应用程序使用.
Kong主要有三个组件
- Kong Server :基于Nginx的服务器,用来接收API请求。
- Apache Cassandra/PostgreSQL :用来存储数据。
- Kong Dashboard:目前主要有两个pgbi/kong与pantsel/konga,推荐使用pantsel/konga
Kong提供了丰富的内置插件,支持安全验证,流量控制,监控,HTTP日志等,亦可以使用Lua开发自定义插件.
Kong除了充当网关使用,还有以下的部署方案
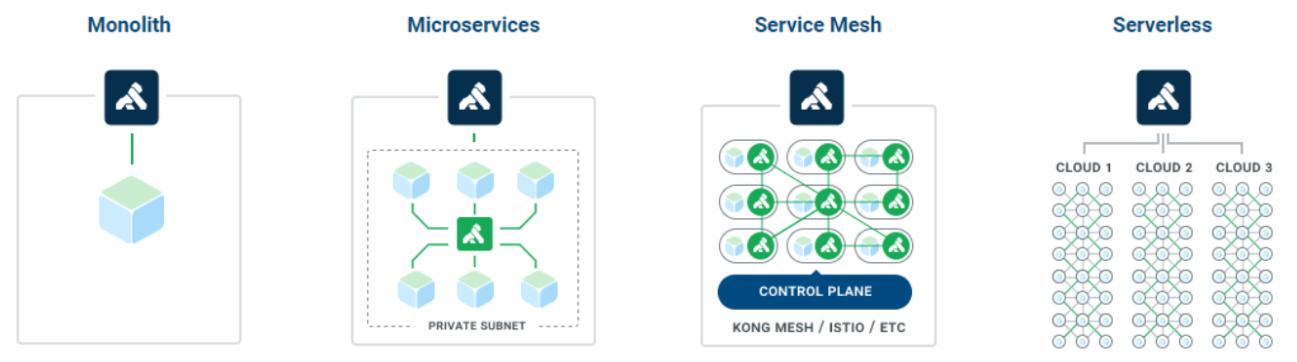
(来源:https://konghq.com/solutions/kubernetes-ingress/)
1. 部署Kong
下面我们就在Kubernetes集群中部署Kong.Kong的部署方式有两种
1 使用Helm组件,一站式安装Kong,https://charts.konghq.com
2 手动利用Yaml文件安装Kong:https://github.com/Kong/kubernetes-ingress-controller,为了加深印象,本次安装使用该方式
根据我们的部署架构规划,所有数据存储都需要放到Kubernetes集群的外部.所以部署分为三步
一 部署PostgreSql数据库
在cd服务器上使用docker来部署PostgreSql数据库
docker run -d --name kong-database \
-p 5432:5432 \
-v /data/postgresql:/var/lib/postgresql/data \
-e "POSTGRES_USER=kong" \
-e "POSTGRES_DB=kong" \
-e "POSTGRES_PASSWORD=kong" \
--restart=always \
postgres:9.6
[root@cd ~]# docker logs kong-database
...
...
PostgreSQL init process complete; ready for start up.
...
...
2
3
4
5
6
7
8
9
10
11
12
13
14
初始化Kong所需要的数据,以下注入的参数需要与部署的Kong容器一致
[root@cd ~]# docker run --rm \
> -e "KONG_DATABASE=postgres" \
> -e "KONG_PG_HOST=192.168.137.81" \
> -e "KONG_PG_PORT=5432" \
> -e "KONG_PG_USER=kong" \
> -e "KONG_PG_PASSWORD=kong" \
> -e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" \
> kong:2.1.3 kong migrations bootstrap
Bootstrapping database...
migrating core on database 'kong'...
core migrated up to: 000_base (executed)
...
...
38 migrations processed
38 executed
Database is up-to-date
[root@cd ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
至此数据库准备完毕.
二 Kubernetes中部署Kong服务
下载yaml文件,我本人改写的yaml文件:https://netcore.wiki/wp-content/uploads/2022/03/kong-dev.yaml_.txt
修改675行,数据连接KONG_PG_HOST修改成192.168.137.81即可
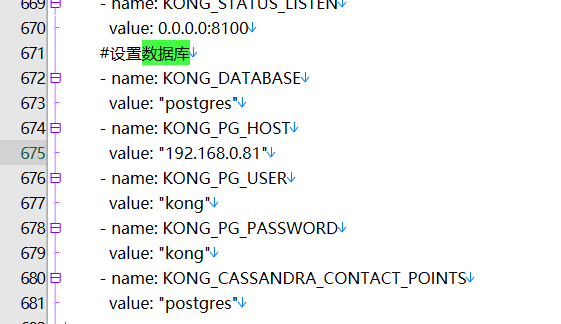
[root@master ~]# kubectl apply -f kong.yaml
namespace/kong created
serviceaccount/kong-serviceaccount created
service/kong-proxy created
service/kong-validation-webhook created
service/kong-ingress-controller created
deployment.apps/ingress-kong created
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "CustomResourceDefinition" in version "apiextensions.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "ClusterRole" in version "rbac.authorization.k8s.io/v1beta1"
unable to recognize "kong.yaml": no matches for kind "ClusterRoleBinding" in version "rbac.authorization.k8s.io/v1beta1"
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[root@master ~]# kubectl get all -n kong
NAME READY STATUS RESTARTS AGE
pod/ingress-kong-555d669bd6-svfb9 2/2 Running 0 6m11s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kong-ingress-controller NodePort 10.111.229.107 <none> 8001:30001/TCP 6m11s
service/kong-proxy LoadBalancer 10.105.83.254 <pending> 80:32310/TCP,443:30868/TCP 6m11s
service/kong-validation-webhook ClusterIP 10.102.163.186 <none> 443/TCP 6m11s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-kong 1/1 1 1 6m11s
NAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-kong-555d669bd6 1 1 1 6m11s
[root@master ~]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到所有kong命名空间下的资源都已经准备完毕,Kong已经处于可用状态.这里需要说一下,Kong暴漏的Service为service/kong-proxy的类型为LoadBalancer,而EXTERNAL-IP为pending.这是正常的.
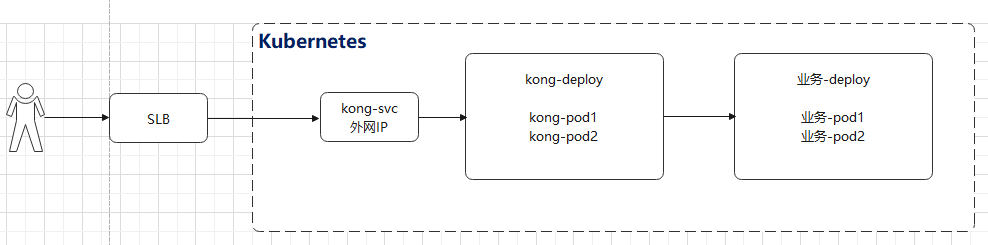
如果我们是直接使用云厂商提供的托管版的Kubernetes,云厂商会为LoadBalancer自动提供公网IP,如下图

所以基于云厂商提供的Kubernetes集群,我们可以直接通过EXTERNAL-IP进行外网暴漏,不过生产环境不建议直接使用EXTERNAL-IP,而是在Kubernetes集群前端再加上SLB.比如下图结构
在我们本地自建环境测试当中,因为没有外部IP,所以访问网关的方式就要特殊一些,我们知道,网关也是一个pod,是一个pod,那么就会存在一个node节点上,所以我们直接访问网关pod所在的节点IP即可(在Kubernetes中我们说过pod是不稳定的,会有漂移现象,可以使用nodeSelector来指定node节点或者使用DaemonSet控制器来部署Kong也可以),如下图接口
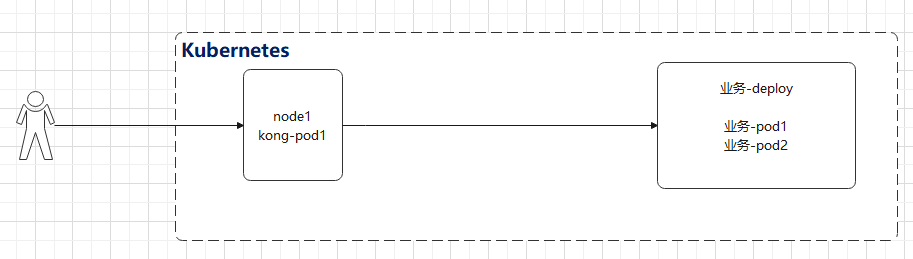
查看kong的pod所在的节点为node1节点
[root@master ~]# kubectl get pod -n kong -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-kong-555d669bd6-svfb9 2/2 Running 0 5m41s 172.16.166.129 node1 <none> <none>
2
3
4
5
查看kong的svc名为kong-proxy端口80映射到32310.
[root@master ~]# kubectl get svc -n kong
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kong-ingress-controller NodePort 10.111.229.107 <none> 8001:30001/TCP 7m11s
kong-proxy LoadBalancer 10.105.83.254 <pending> 80:32310/TCP,443:30868/TCP 7m11s
kong-validation-webhook ClusterIP 10.102.163.186 <none> 443/TCP 7m11s
[root@master ~]#
2
3
4
5
6
我们直接在浏览器访问node1节点http://node1:32310
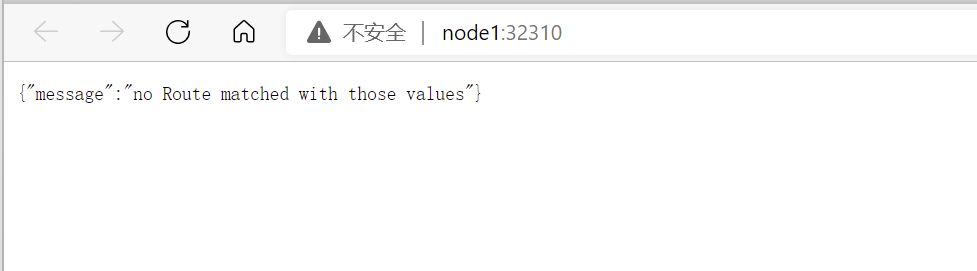
可以看到kong返回的信息:no Route matched with those values,这是因为我们没有设置任何的路由,然后我们在hosts文件中添加域名解析服务,假设我们的网关地址是http://api.kong.com,修改本机C:\Windows\System32\drivers\etc\hosts,以便域名api.kong.com解析到Kong网关的地址
PS C:\Users\Yan> ping api.kong.com
正在 Ping api.kong.com [192.168.137.147] 具有 32 字节的数据:
来自 192.168.137.147 的回复: 字节=32 时间<1ms TTL=64
来自 192.168.137.147 的回复: 字节=32 时间<1ms TTL=64
2
3
4
5
添加完解析后,可以访问

对于Kong生产环境的一些建议
- 将网关尽量调度到专用node节点,该节点不要受业务Pod影响
- PostgreSql数据库需要部署为高可用架构
- 适当调整Kong的副本(pod)实例,适当调整副本内部的工作进程数
- 集群前端需要结合SLB进行使用,不要直接使用Kong
2. 部署Konga
Kubernetes中部署控制面板konga服务
一 初始化数据库
在cd服务器上执行以下脚本
[root@cd ~]# docker run --rm pantsel/konga -c prepare -a postgres -u postgresql://kong:kong@192.168.137.81:5432/konga
...
...
...
debug: Seeding User...
debug: User seed planted
debug: Seeding Kongnode...
debug: Kongnode seed planted
debug: Seeding Emailtransport...
debug: Emailtransport seed planted
debug: Database migrations completed!
2
3
4
5
6
7
8
9
10
11
二 集群部署Konga
kind: Deployment
apiVersion: apps/v1
metadata:
name: konga
namespace: kong
labels:
app: dashboard-konga
spec:
replicas: 1
selector:
matchLabels:
app: dashboard-konga
template:
metadata:
labels:
app: dashboard-konga
spec:
containers:
- name: konga
image: pantsel/konga
ports:
- containerPort: 1337
env:
- name: TOKEN_SECRET
value: kong
- name: NODE_ENV
value: production
- name: DB_ADAPTER
value: postgres
- name: DB_URI
#修改该数据库连接信息
value: postgresql://kong:kong@192.168.137.81:5432/konga
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: svc-konga
namespace: kong
spec:
type: NodePort
selector:
app: dashboard-konga
ports:
- protocol: TCP
port: 1441
targetPort: 1337
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
[root@master ~]# kubectl apply -f konga.yaml
deployment.apps/konga created
service/svc-konga created
[root@master ~]# kubectl get pod -n kong -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-kong-555d669bd6-svfb9 2/2 Running 0 25m 172.16.166.129 node1 <none> <none>
konga-76c8664445-xscr2 1/1 Running 0 19s 172.16.166.132 node1 <none> <none>
[root@master ~]# kubectl get svc -n kong -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kong-ingress-controller NodePort 10.111.229.107 <none> 8001:30001/TCP 25m app=ingress-kong
kong-proxy LoadBalancer 10.105.83.254 <pending> 80:32310/TCP,443:30868/TCP 25m app=ingress-kong
kong-validation-webhook ClusterIP 10.102.163.186 <none> 443/TCP 25m app=ingress-kong
svc-konga NodePort 10.111.81.40 <none> 1441:31023/TCP 25s app=dashboard-konga
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到konga部署到node1节点上,svc对应的端口为31023,所以我们直接访问http://192.168.137.147:31023/

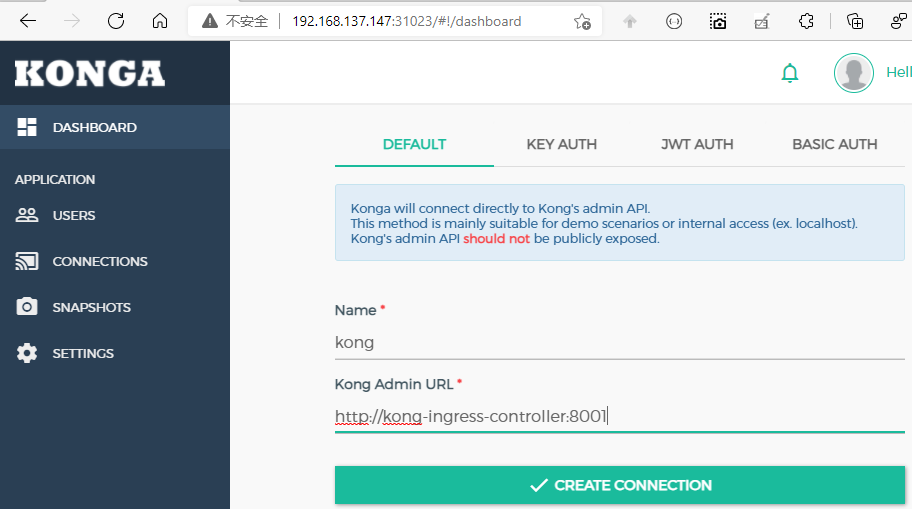
填写我们自己的用户名密码即可,至此Konga部署成功,接下来我们用Konga来管理Kong.
登录Konga以后,会让我填写Kong的admin url,可以通过 kubectl get svc -n kong来查看 kong-ingress-controller为Kong的admin url
[root@master ~]# kubectl get svc -n kong
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kong-ingress-controller NodePort 10.111.229.107 <none> 8001:30001/TCP 42m
2
3
点击CREATE CONNECTION以后,可以看到当前网关的详细信息
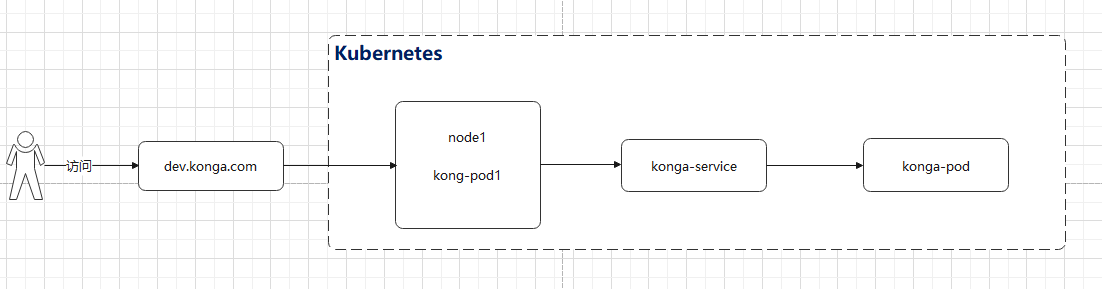
3. 让Kong代理Konga
我们的目的是让网关作为统一的入口,通过网关访问Konga服务.
首先让我们看一段配置
upstream xx_name {
server 192.168.1.1:8080 weight=100;
}
server {
listen 80;
server_name: xx.com;
location /path{
proxy_pass http://xx_name;
}
}
2
3
4
5
6
7
8
9
10
11
相比很多同学都知道,这是Nginx的反向代理配置,Kong有四个核心组件upstream,target,service,route,这四个组件则对应以上的配置
- upstream: 用来定义upstream模块,对应上面的upstream
- target: 即后端服务器,即上面upstream中的 server 192.168.1.1:8080 weight=100;
- service: 用来定义上面结构的: server模块
- route: 用来定义 上面server结构中的location模块
接下来,我通过konga进行设置,让Kong代理konga,整体请求流程如下
- 先添加解析,修改本机C:\Windows\System32\drivers\etc\hosts,以便域名dev.konga.com解析到Kong网关的地址,即node1的IP地址
PS C:\Users\Yan> ping dev.konga.com
正在 Ping dev.konga.com [192.168.137.147] 具有 32 字节的数据:
来自 192.168.137.147 的回复: 字节=32 时间<1ms TTL=64
2
3
4
5
在Konga中添加upstream
点击左侧导航UPSTREAM,然后添加名为ups-konga,然后点击SUBMIT UPSTREAM即可
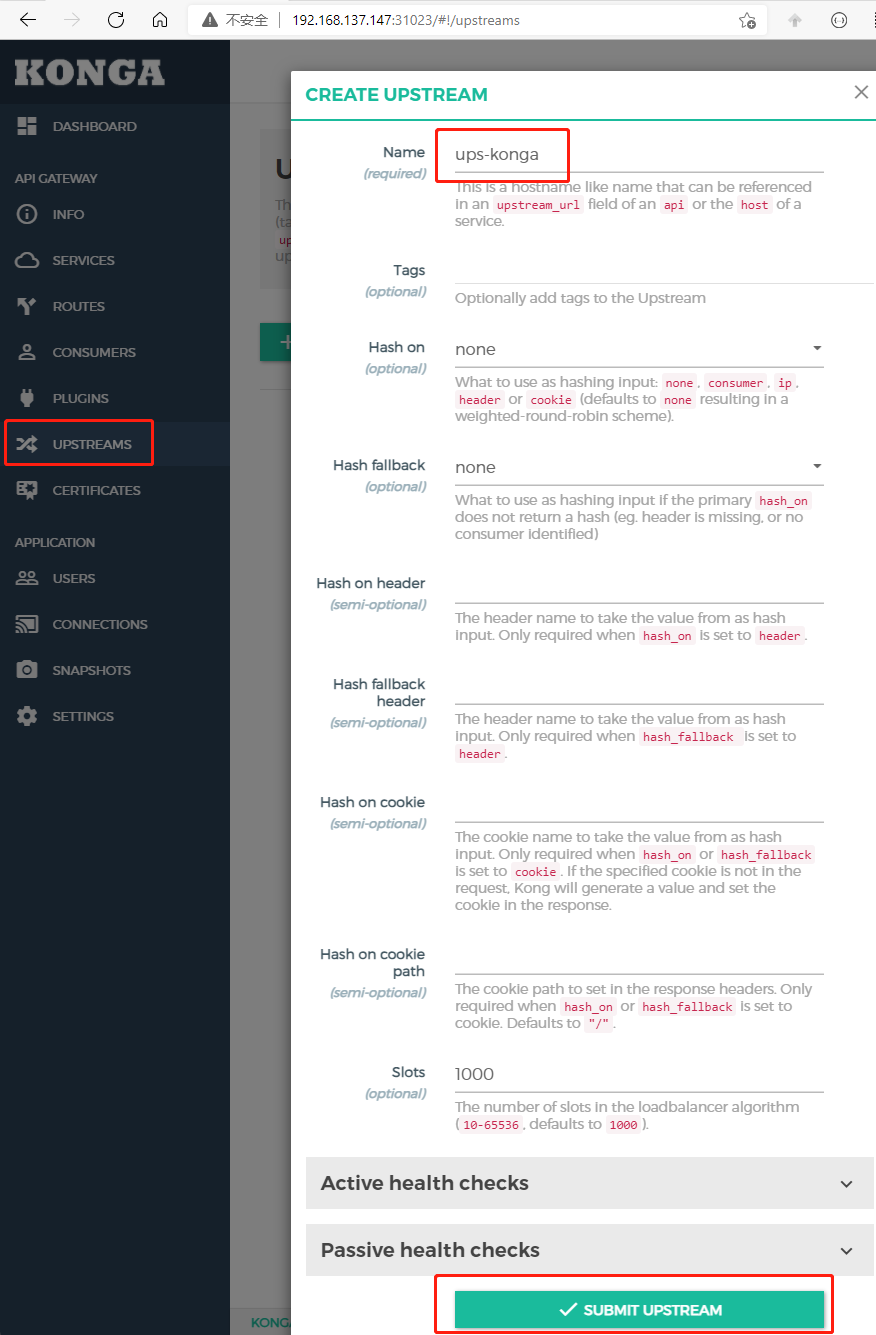
创建完后后,点击列表中的DETAILS
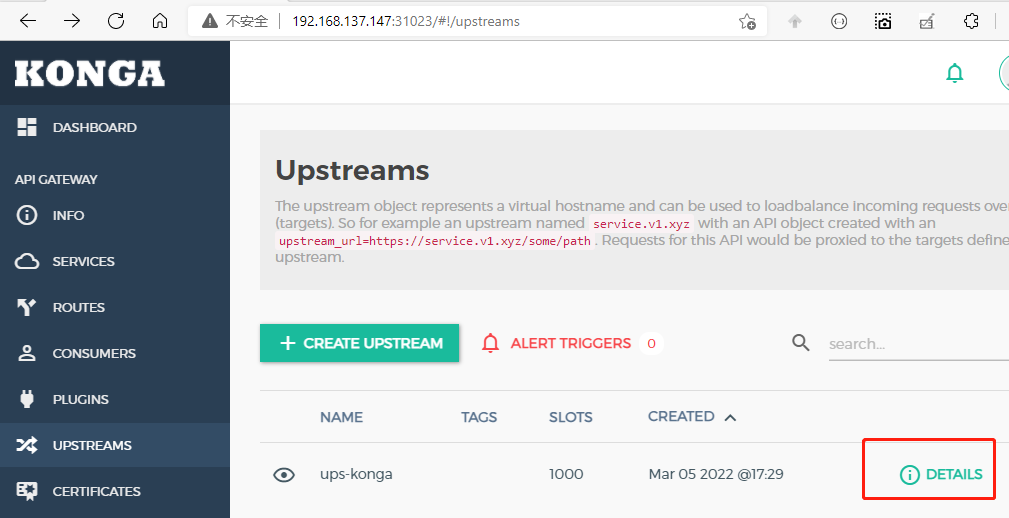
然后添加target,在Target处填写konga在Kubernetes中的svc地址与端口,可以通过kubectl get svc -n kong查看,然后SUBMIT TARGET即可,可以看到svc-konga端口是1441.
[root@master ~]# kubectl get svc -n kong
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kong-ingress-controller NodePort 10.111.229.107 <none> 8001:30001/TCP 19h
kong-proxy LoadBalancer 10.105.83.254 <pending> 80:32310/TCP,443:30868/TCP 19h
kong-validation-webhook ClusterIP 10.102.163.186 <none> 443/TCP 19h
svc-konga NodePort 10.111.81.40 <none> 1441:31023/TCP 19h
2
3
4
5
6
至此konga的upstream创建完毕
- 在Konga中添加Service
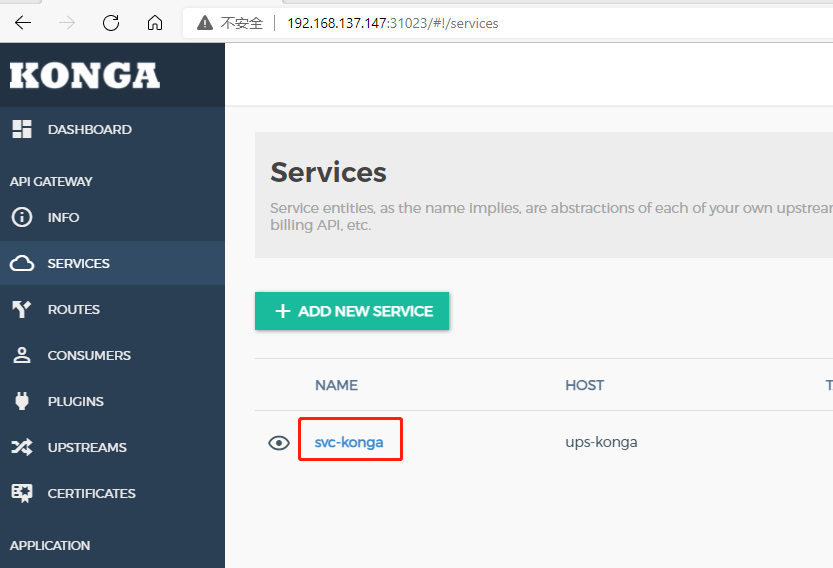
点击左侧导航SERVICE,然后添加SERVICE,该表单中4个字段为必填
- Name:定义一个名称
- Protocol:转发的协议,内网一般都是http
- Host:填写上一步我们定义的upstream的名称,即ups-konga
- Port:端口80
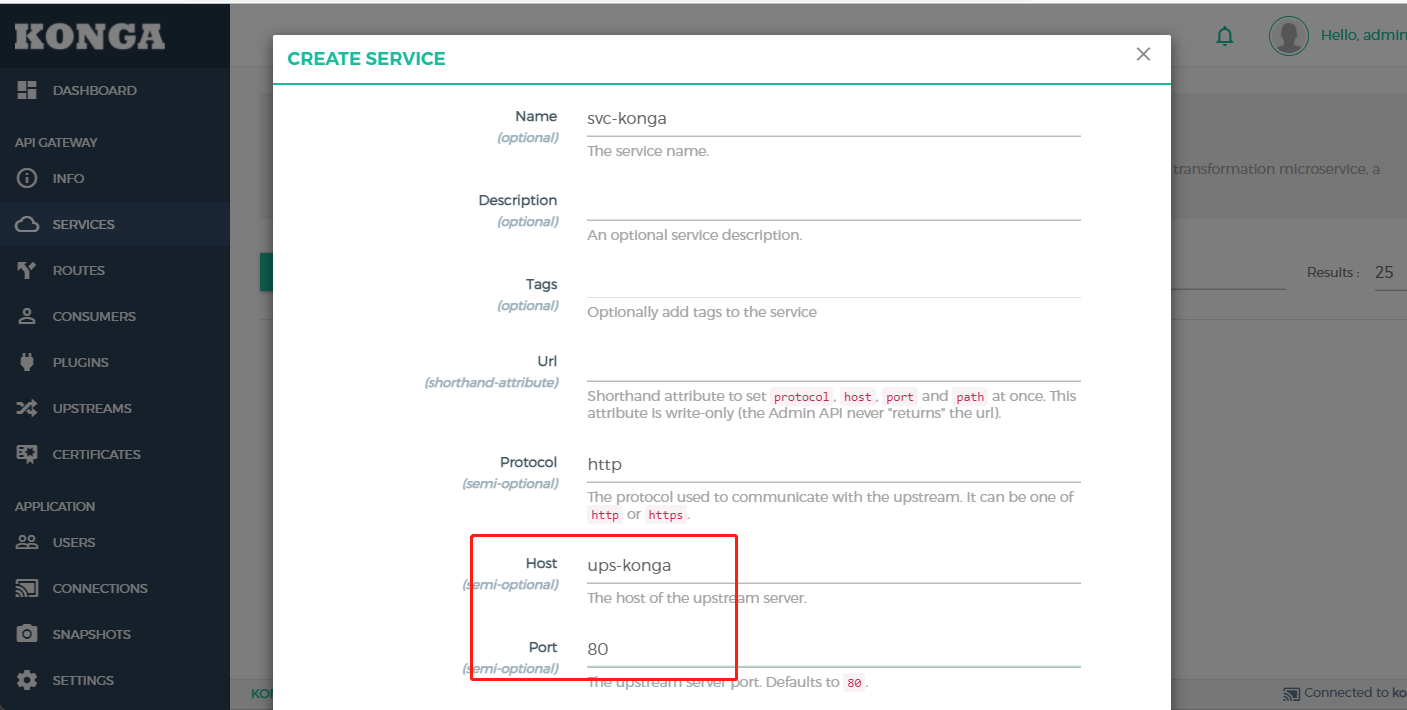
然后保存即可.然后在列表中点击该Service
然后添加一个Route,该表单有三个选项必填
- Name: 定义个名字
- Hosts: 这里填写我们要路由的名称
- Methods: 这里指定httpMethod才会路由
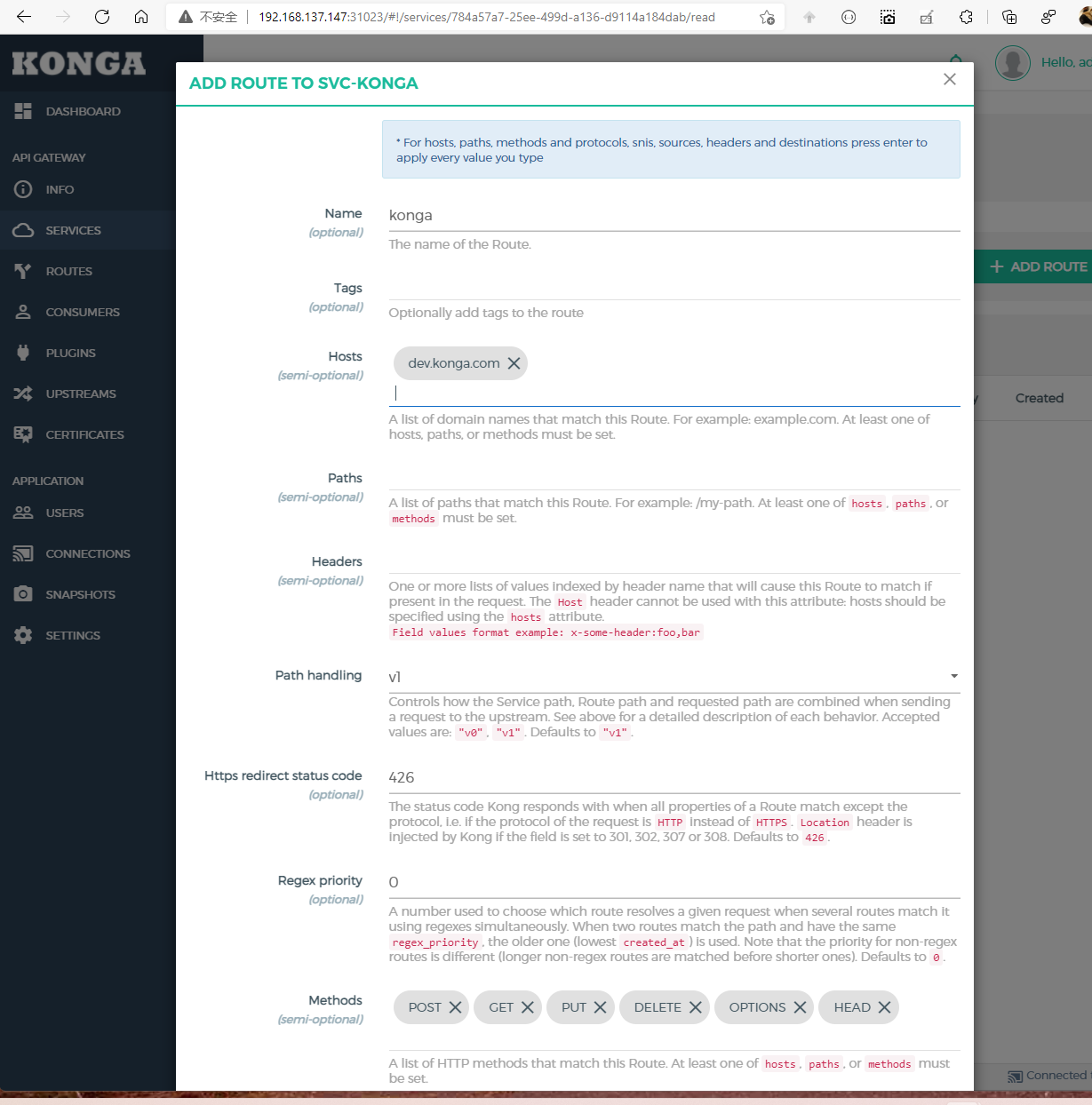
然后保存即可,至此已经配置完毕,我们在浏览器中访问:http://dev.konga.com:32310/.因为node1节点上的Kong暴漏的端口是32310,所以访问是需要加上端口号.可以看到已经正确路由

这个实验因为Kong与Konga都是在node1节点上的,所以效果可能不是很明显,大家可以利用nodeSelector特性,将Konga调度到node2接上,再试试看通过http://dev.konga.com:32310,是否依然可以访问?
4. 自动注册
从本章节中我们正式步入云原生时代,从提交代码到自动构建镜像到自动部署到Kubernetes集群中并实现自动注册等.
1. 路由规划
在整体架构中,我们采用服务端发现模式,所以希望我们的应用能够有自动注册的能力,我们规划自动注册的流程如下.
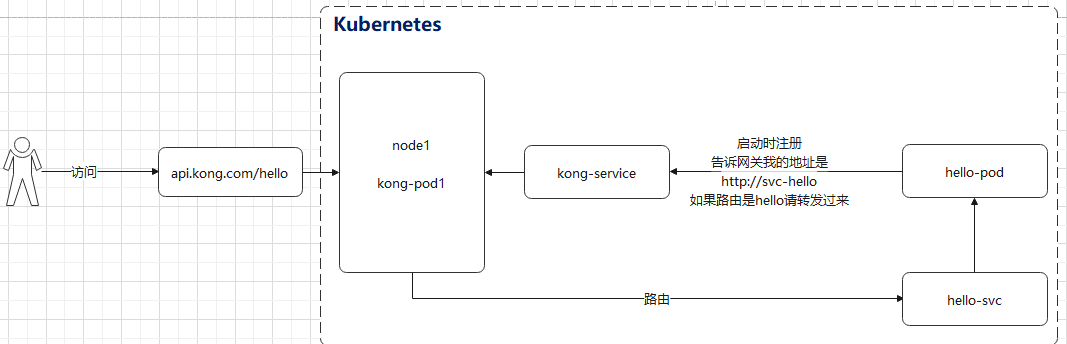
在应用启动的时候,向Kong网关注册,服务名称,路由规则等,外部访问Kong网关的时候,匹配路由规则,然后路由到应用服务中.
首先我们定义好我们的网关路由规则,网关的路由规则很重要,影响到前端应用的访问和后续业务服务的扩展.
比如我们定义规则: http://网关地址/业务服务/模块/执行方法
根据这个规则,我们的hello.http服务请求的路径就是http://api.kong.com:32310/hello/greeting/get,本次实例以**.netcore3.1**为基准,代码如下
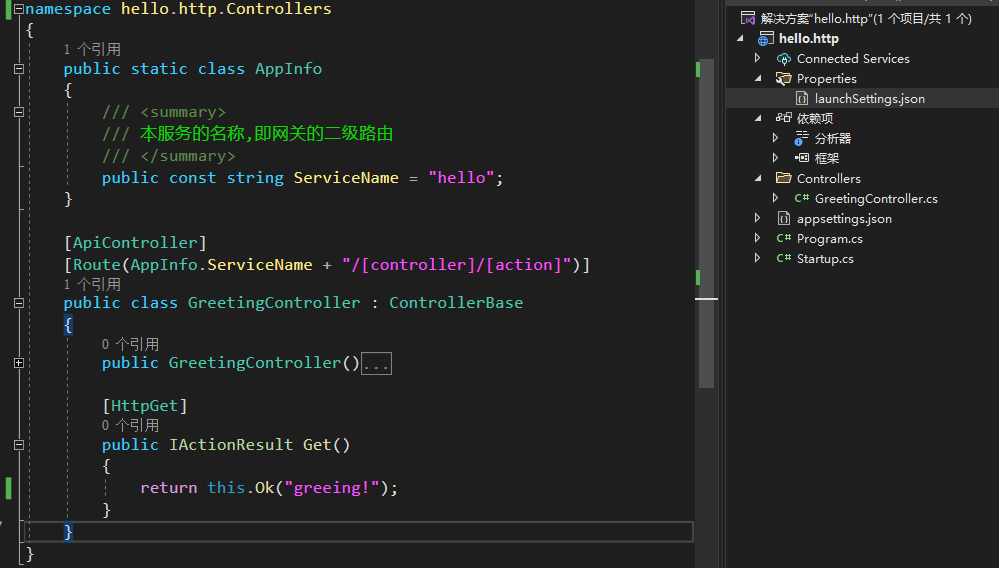
其中我们增加了AppInfo类,用来定义二级路由名称,作用于GreetingController上,所以我们的应用中GreetingController访问路径应该http://localhost:5000/hello/greeting/get

2. 引用相关包
我们需要使用以下包,来实现Kong的网关自动注册
Kong.Net
Kong.Extension
Microsoft.AspNet.WebApi.Client
3. 注册代码
在appsettings.json添加kong需要的配置
//添加Kong的配置
"kong": {
//1. 这里填写Kubernetes中的Kong的Service地址
"host": "http://kong-ingress-controller.kong:8001",
"upstream": {
//2. 这里定义本服务在Kong中的upstream名称
"name": "ups-hello.http",
"hash_on": "none",
"healthchecks": {
"active": {
"unhealthy": {
"http_statuses": [ 429, 500, 501, 502, 503, 504, 505 ],
"tcp_failures": 1,
"timeouts": 1,
"http_failures": 1,
"interval": 5
},
"type": "http",
"http_path": "/kong/healthchecks",
"timeout": 1,
"healthy": {
"successes": 1,
"interval": 5,
"http_statuses": [ 200, 302 ]
},
"https_verify_certificate": true,
"concurrency": 1
},
"passive": {
"unhealthy": {
"http_statuses": [ 429, 500, 501, 502, 503, 504, 505 ]
},
"healthy": {
"http_statuses": [ 200, 302 ]
},
"type": "http"
}
},
"hash_on_cookie_path": "/",
"hash_fallback": "none",
"slots": 10000
},
"target": {
//3. 该值是指Kong路由到后端服务地址,所以填写本服务在Kubernetes中的ServiceName与端口
// 注意跨命名空间的访问规则
"target": "svc-hello-http.dotnet:80",
"weight": 100
},
"service": {
//4. 这里定义本服务在kong中的service名称
"name": "svc-hello-http",
"protocol": "http",
//5. 这里upstream名称
"host": "ups-hello.http",
"port": "80",
"connect_timeout": "60000",
"write_timeout": "60000",
"read_timeout": "60000"
},
"route": {
//6. 这里定义本服务在Kong中的route名称
"name": "route-hello.http",
"protocols": [ "https", "http" ],
//7. 这里填写网关的域名
"hosts": [ "api.kong.com" ],
//8. 这里填写二级路由,也就是我们定义的AppInfo.ServiceName
"paths": [ "/hello/(?i)" ],
"methods": [ "POST", "GET", "PUT", "DELETE", "OPTIONS", "HEAD", "TRACE", "CONNECT" ],
"https_redirect_status_code": 426,
"Regex_priority":2
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
注意以上的8条注释,其他值默认均可
在Startup.cs中相关代码
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
//添加健康检查,这里是为了Kubernetes的探针
services.AddHealthChecks();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
//配置健康检查的路由
endpoints.MapHealthChecks($"{Controllers.AppInfo.ServiceName}/health");
});
//如果是生产环境或者集群环境则向网关发起注册
//在本地开始时因为无法访问Kubernetes内部地址,所以会出错
if (env.IsProduction())
UseKong(app, this.Configuration);
}
public static IApplicationBuilder UseKong(IApplicationBuilder app, IConfiguration configuration)
{
KongClient kongClient = new KongClient(new KongClientOptions(HttpClientFactory.Create(), configuration["kong:host"]));
#region 注册upstream
var upStream = configuration.GetSection("kong:upstream").Get<UpStream>();
var target = configuration.GetSection("kong:target").Get<TargetInfo>();
app.UseKong(kongClient, upStream, target, context => context.Response.StatusCode = 200);
#endregion
#region 注册service
var service = configuration.GetSection("kong:service").Get<ServiceInfo>();
#Id应该唯一,这里可以用指定常量,也可以随机生成,
#随机生成的话,这样每次重启应用都会向Kong网关进行注册,会失败,但是不影响第一次注册成功的,所以
#即使失败,之前的依然有效.
#失败后应用是无法启动的,所以需要特殊处理
service.Id = new Guid("f7fe09f2-4f29-4d1c-baf7-f86cf7bef62f");
kongClient.Service.UpdateOrCreate(service);
#endregion
#region 注册路由
var route = configuration.GetSection("kong:route").Get<RouteInfo>();
#同ServiceId
route.Id = new Guid("f035103c-9ba4-4e63-9d02-106870f11d32");
route.Service = new RouteInfo.ServiceId() { Id = service.Id.Value };
kongClient.Route.UpdateOrCreate(route);
#endregion
return app;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
以上就是我们实现自动注册的主要代码与配置,小伙伴可以根据实际情况进行优化代码结构.
最后,可能有的小伙伴就会问起,既然有服务注册了,那么怎么没有服务卸载呢?因为Kubernetes中所有的pod的都是不稳定的,如果我们采用在应用程序停止的时候进行向网关卸载,那么假如我们的其中一个pod崩溃了,而另外的pod正在运行,这时候会发生什么现象? Kong将路由卸载,无法转发请求,其他正在运行的pod就无法接受请求了.同理,在我们使用滚动式更新也是会出现同样的问题.所以建议使用手动卸载服务,而不是自动卸载.
3. 持续集成
在本章节,我们将我们写好的代码利用CI/CD工具Teamcity发布到Kubernetes集群中.部署到集群中主要有以下4个步骤
- 添加Dockerfile
- 添加Kubernetes的部署文件
- 将代码上传代码库
- 配置持续集成
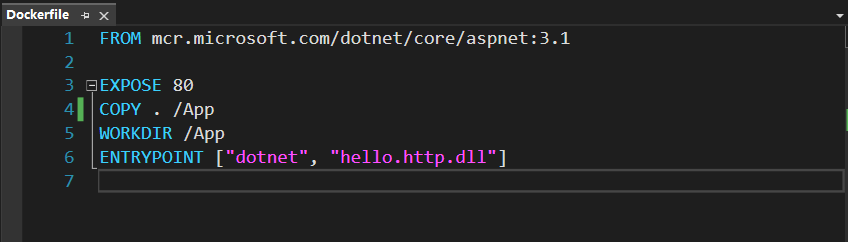
1. 添加Dockerfile
在解决方案中添加Dockerfile,
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1
EXPOSE 80
COPY . /App
WORKDIR /App
ENTRYPOINT ["dotnet", "hello.http.dll"]
2
3
4
5
6
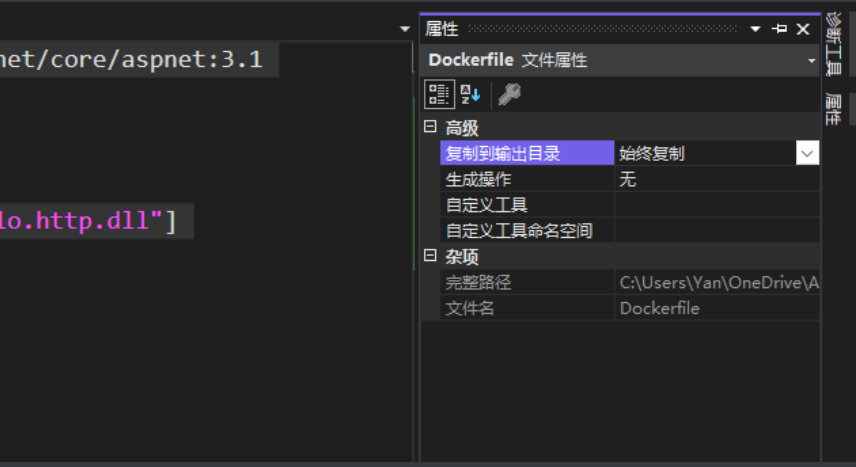
并右键Dockerfile,选择始终复制,我们在构建镜像时需要使用
2. 部署脚本
解决方案中添加kubernetes.yaml,用于集群内部署
#创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-http
#指定命名空间,不建议通过在该文件中创建命名空间,否则在删除对象时,会造成该命名空间也会被删除
#可以预先在集群中手动创建该命名空间即可
namespace: dotnet
spec:
replicas: 1
selector:
matchLabels:
app: hello-http
template:
metadata:
labels:
app: hello-http
spec:
containers:
- name: hello-http
env:
#注入环境变量
- name: ASPNETCORE_ENVIRONMENT
value: Production
#为了演示效果,这里使用的是DockerHub地址
#ImageVersionTag为变量,有CI传入进来
image: a121984376/hello-http:ImageVersionTag
imagePullPolicy: IfNotPresent
#资源限制
resources:
requests:
cpu: "150m"
limits:
cpu: "500m"
ports:
- containerPort: 80
#存活探针,健康检查的地址
livenessProbe:
httpGet:
path: /hello/health
port: 80
initialDelaySeconds: 10
periodSeconds: 3
#可读探针,健康检查的地址
readinessProbe:
httpGet:
path: /hello/health
port: 80
initialDelaySeconds: 10
periodSeconds: 3
---
#创建Service
apiVersion: v1
kind: Service
metadata:
name: svc-hello-http
namespace: dotnet
spec:
type: ClusterIP
selector:
app: hello-http
ports:
- protocol: TCP
port: 80
targetPort: 80
---
#创建HPA
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-hello-http
namespace: dotnet
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hello-http
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
以上文件需要有几个注意的地方
- 为了演示效果镜像仓库使用的是DockerHub,在真实场景中使用的应该是私有仓库,Kubernetes如何使用私有仓库可以查阅相关资料
- 命名空间,业务应用都应该部署一个单独的命名空间,不应使用default命名空间
- HPA水平伸缩的设置不是必须的,取决于业务是否需要
- 这里并没有指定nodeSelector,真实环境中业务应用应该调度到相关node节点上
- 27行有个字符串ImageVersionTag,指定镜像版本号,需要CI/CD在执行构建时进行替换
部署脚本
解决方案中添加deploy.sh
#!/bin/bash
# author:岩
# message: 对容器执行部署或者升级
echo "服务:$1"
echo "版本: $2"
echo "部署文件: $3"
get_deploy=`kubectl get deployments $1 -n dotnet 2>&1 |grep -v NotFound |grep $1 | wc -l`
if [ $get_deploy -gt 0 ];then
echo "更新镜像"
kubectl set image deployment/$1 $1=a121984376/$1:$2 -n dotnet
else
echo "部署镜像"
kubectl apply -f $3
fi
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
部署脚本判断执行逻辑,新部署镜像还是更新镜像
最终文件结构
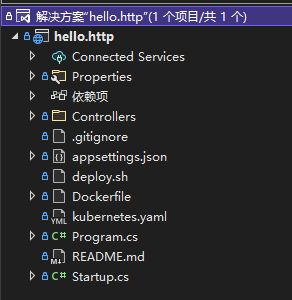
3. 上传代码库
将解决方案上传到代码库,本示例使用的是Azure DevOps Server,免费托管版本.
4. 配置持续集成
我们打开Teamcity,创建一个Project
然后填写代码仓库的地址以及访问仓库的用户名与密码,然后点击Processd
Teamcity会自动识别代码仓库的类别,接下来显示的我们这个仓库的分支,我们默认是用main分支,点击Processd
Teamcity会自动探测你的项目是用什么开发语言创建的,并自动生成构建步骤, 不过通常自动的是无法满足需求,需要我们自定义步骤
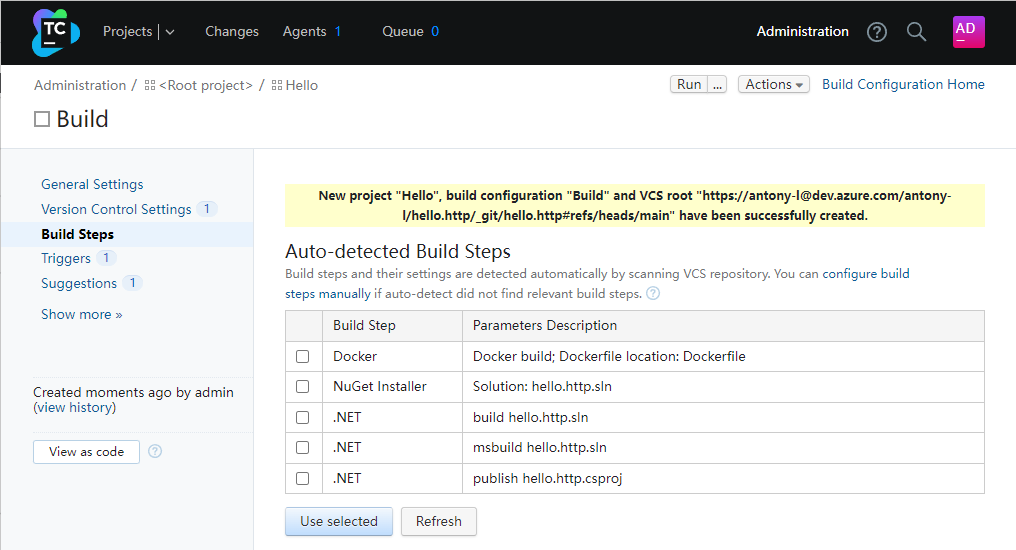
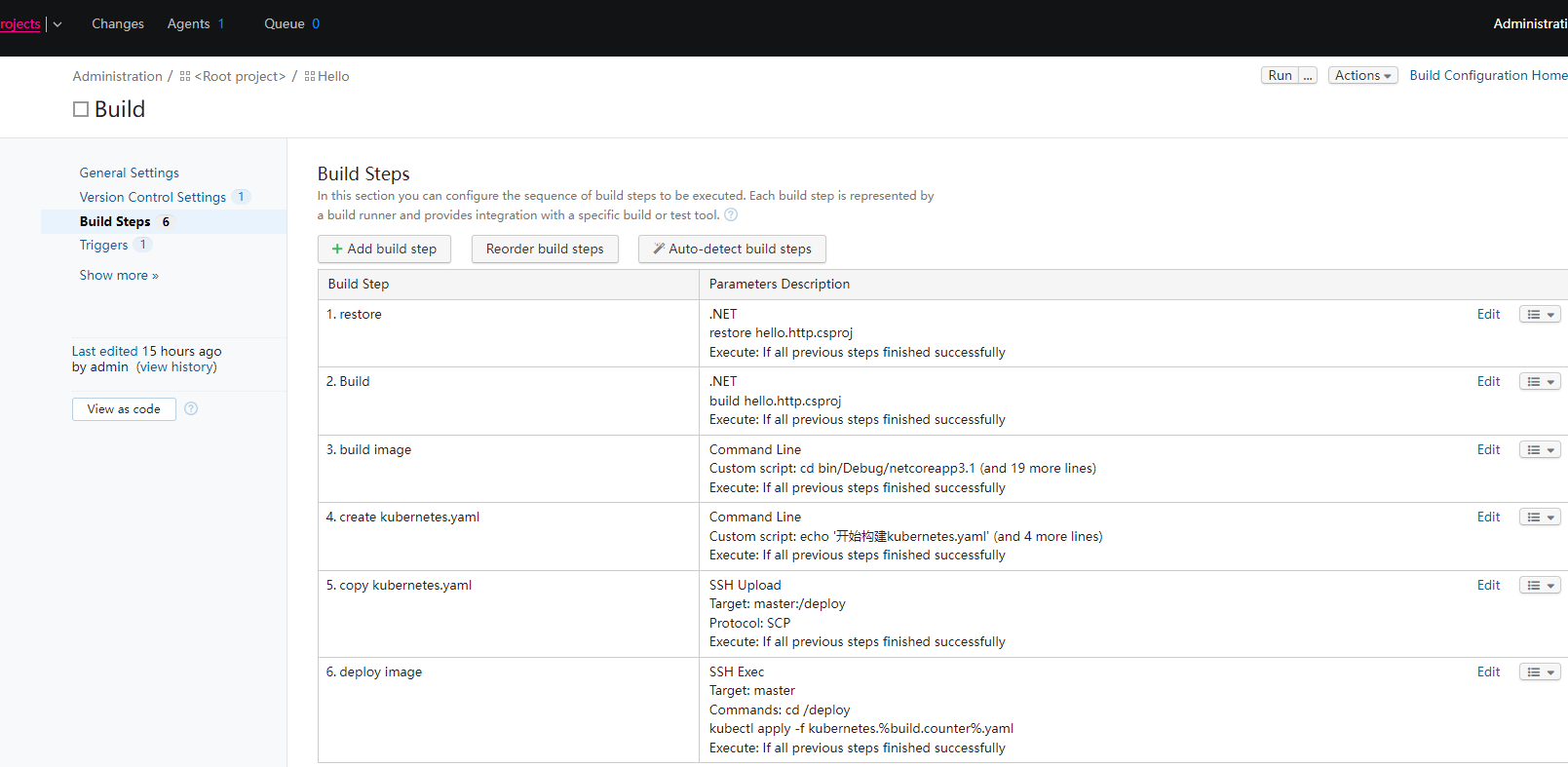
构建步骤一共分为6步:
- 还原项目
- 编译项目
- 构建镜像
- 创建部署文件
- 将部署文件与部署脚本复制到master节点
- 在master节点上部署该文件
我们来手动配置构建步骤.点击Add build step
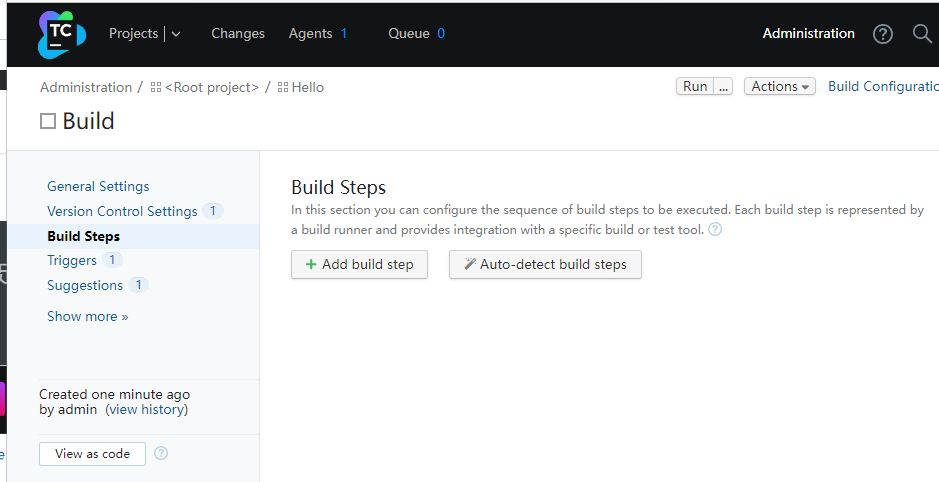
首先我需要还原项目.使用的是dotnet restore命令,指定项目的项目文件.然后保存
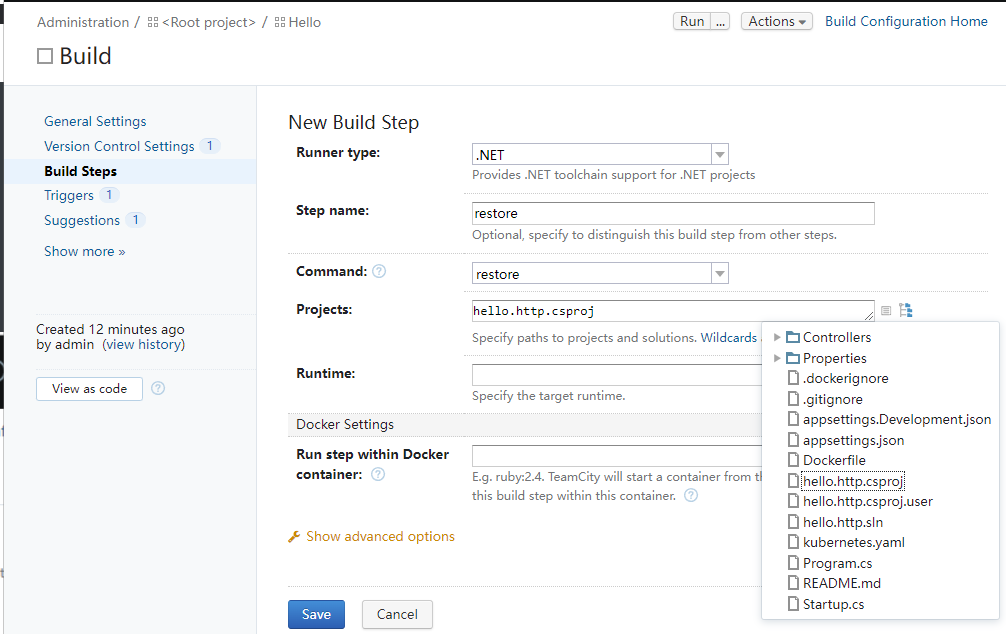
然后我们在添加一步,这一步我们使用的dotnet build命令,来编译项目
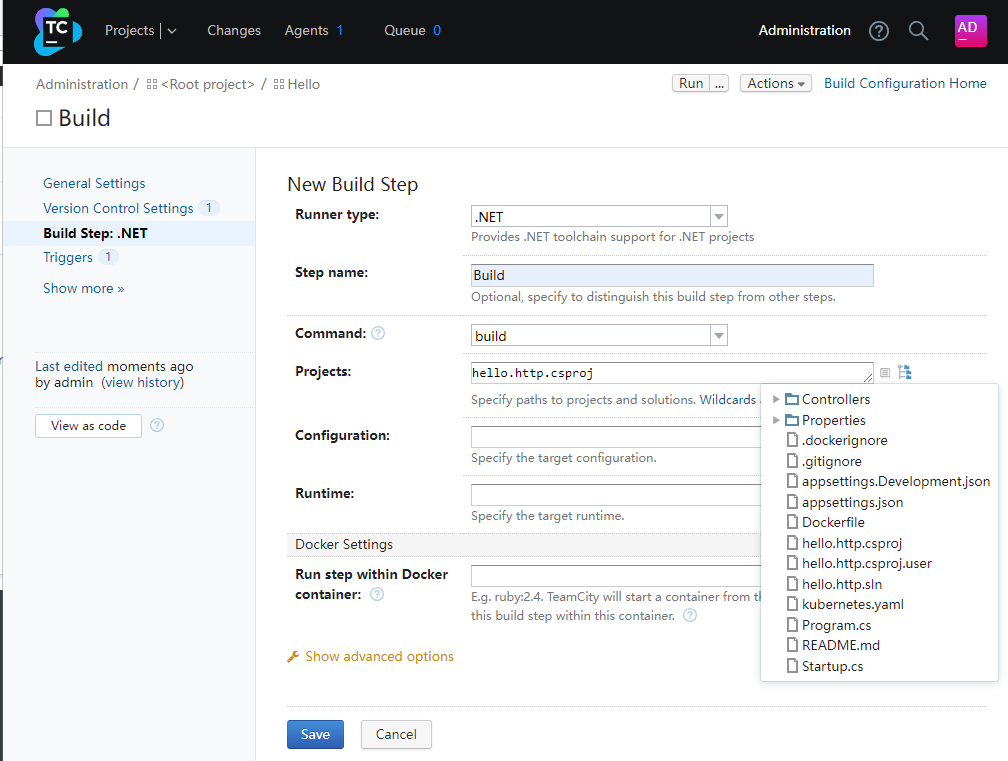
接下来我们需要使用Command Line的类型来执行构建镜像的命令,
cd bin/Debug/netcoreapp3.1
echo '开始构建镜像'
echo '-----------------'
docker build -t hello-http:v%build.counter% .
docker tag hello-http:v%build.counter% a121984376/hello-http:v%build.counter%
echo '登录DockerHub'
echo '-----------------'
docker login --username=Docker账号 --password=密码
echo '开始推送镜像'
echo '-----------------'
docker push a121984376/hello-http:v%build.counter%
echo '清理本地镜像'
echo '-----------------'
docker rmi hello-http:v%build.counter%
docker rmi a121984376/hello-http:v%build.counter%
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
%build.counter%参数为Teamcity的构建计数器变量,Teamcity内置很多变量,我们可以利用这个值为镜像版本号
注意这里用的是DockerHub公用仓库,请更改成自己的账号
然后我们验证一下,这三个步骤是否正确,回到首页,点击右下角的Run
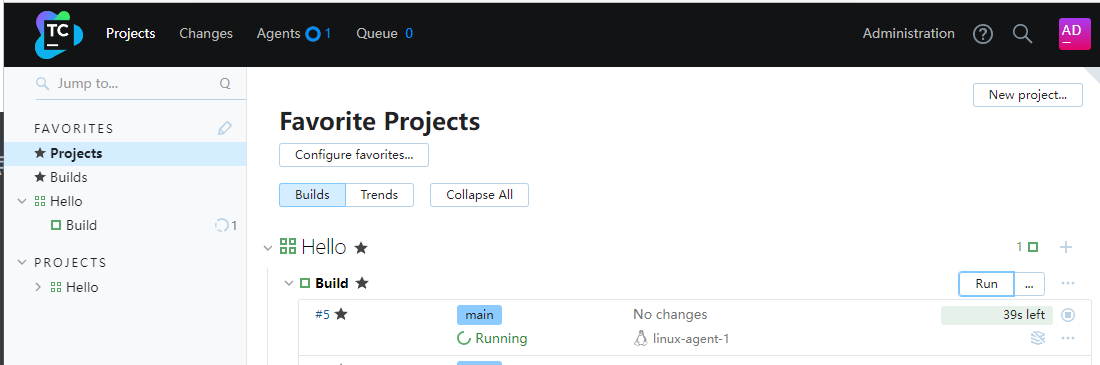
可以看到已经开始执行了,点击进去,我们还可以看到输出的日志.可以看到Build finished,这时候镜像已经推送到DockerHub,可以登录到自己的经DockerHub来查看推送的镜像
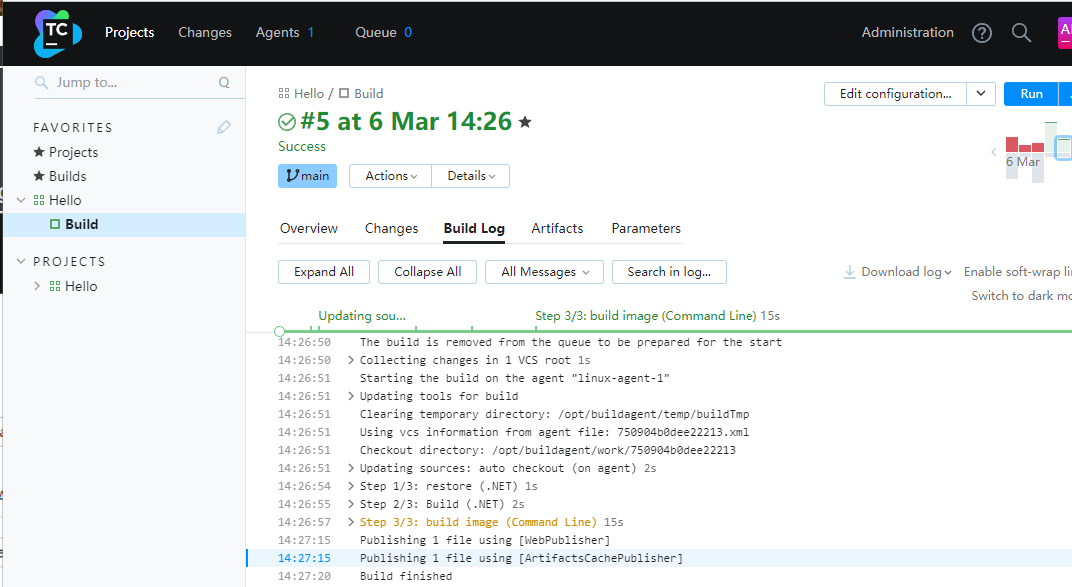
接下来,我们在增加一个Build step,点击Edit configuration,然后在Add build step,
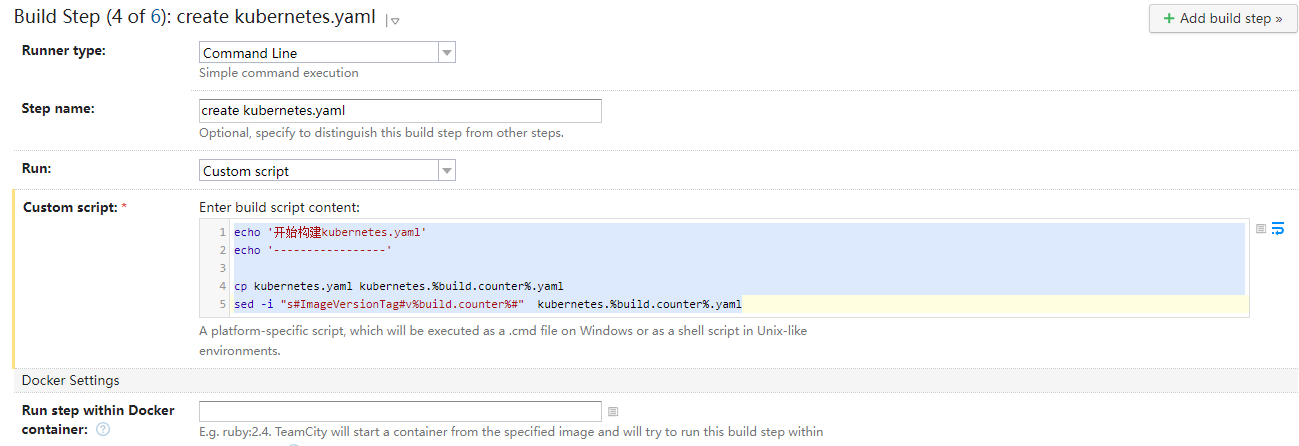
这一步我们主要是构建Kubernetes部署文件,还记得我们的kubernetes.yaml文件里定义了一个镜像版本号标识符,这一步主要是替换这个标识符
echo '开始构建kubernetes.yaml'
echo '-----------------'
cp kubernetes.yaml kubernetes.%build.counter%.yaml
sed -i "s#ImageVersionTag#v%build.counter%#" kubernetes.%build.counter%.yaml
2
3
4
5
替换镜像版本标识后的文件,就是我们用来部署的yaml文件,然后我们需要将这个yaml文件与deploy.sh部署脚本复制到master节点上.
在增加一步build step,Runner type选择SSH Upload,将这两个文件复制到master节点的根目录下的deploy文件夹下
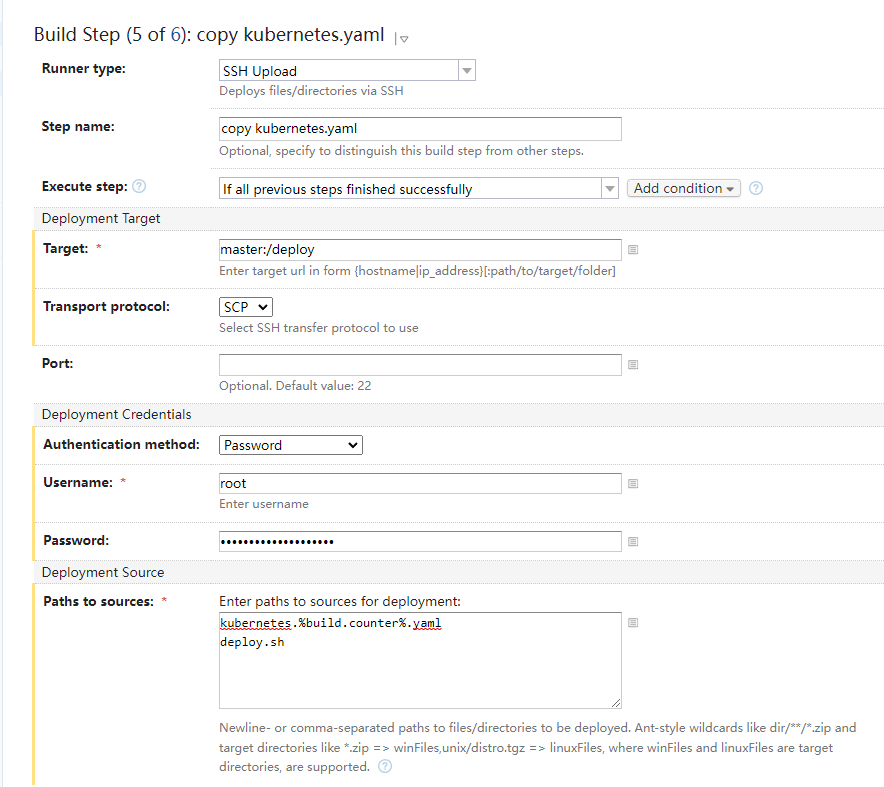
最后一步,增加一个build step.
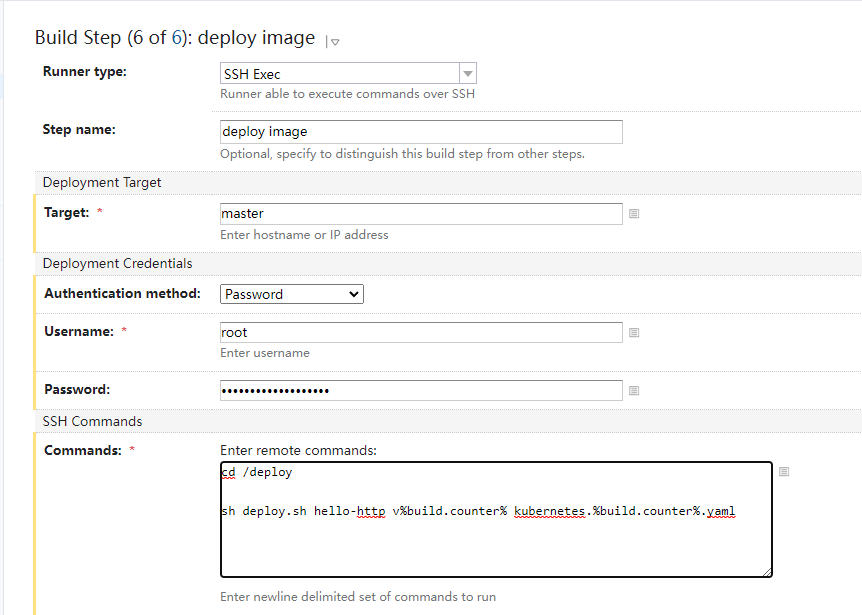
在master节点的根目录下的deploy目录中,执行部署脚本,传入我们定义好的三个参数,名称,版本,部署文件
最终如下.
5. 验证
经过以上配置,我们的持续集成就算是配置好了,当然实际应用中,每个团队的业务情况不一样,或许有些区别,但是大体逻辑与步骤是一样的,小伙伴可以根据实际情况进行调整.
我们回到首页,点击Run来查看一下.
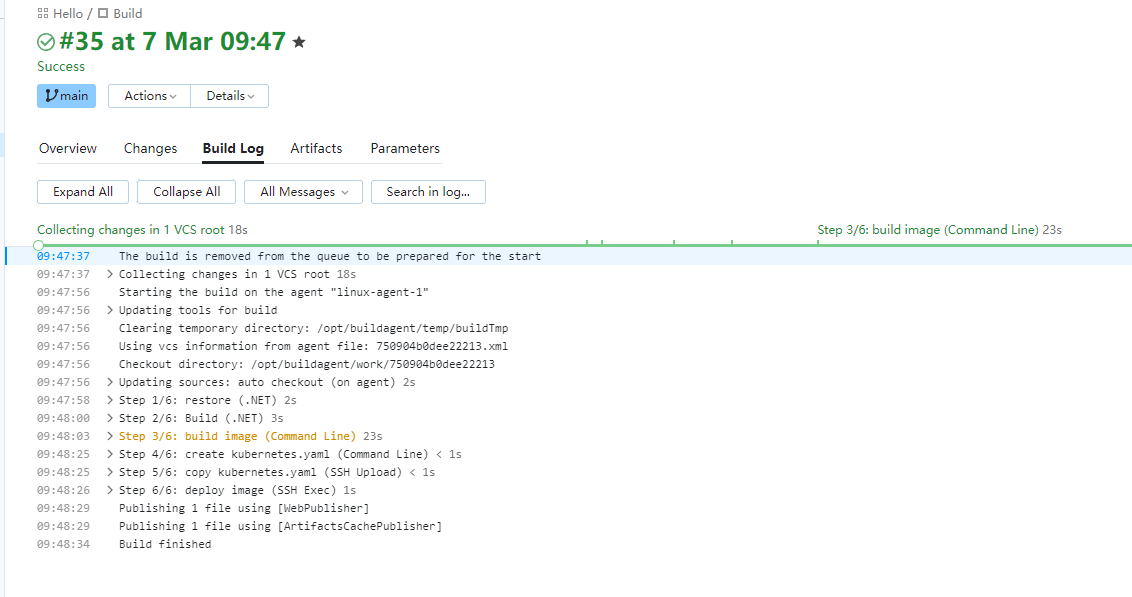
从构建日志可以看到,6个步骤跑完了,
我们先看一下pod是否存在
[root@master deploy]# kubectl get pod -n dotnet
NAME READY STATUS RESTARTS AGE
hello-http-94f4765b4-mn2c8 1/1 Running 0 9m35s
[root@master deploy]# kubectl describe pod hello-http-94f4765b4-mn2c8 -ndotnet
Name: hello-http-94f4765b4-mn2c8
Namespace: dotnet
Priority: 0
Node: node2/192.168.137.18
...
...
...
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m44s default-scheduler Successfully assigned dotnet/hello-http-94f4765b4-mn2c8 to node2
Normal Pulling 9m43s kubelet Pulling image "a121984376/hello-http:v35"
Normal Pulled 9m19s kubelet Successfully pulled image "a121984376/hello-http:v35" in 23.7004629s
Normal Created 9m19s kubelet Created container hello-http
Normal Started 9m19s kubelet Started container hello-http
[root@master deploy]#
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
可以看到pod已经启动了,并且内部镜像使用的是v35,和teamcity的构建计数器是一样的,
我们通过网关访问一下我们之前规划的路径
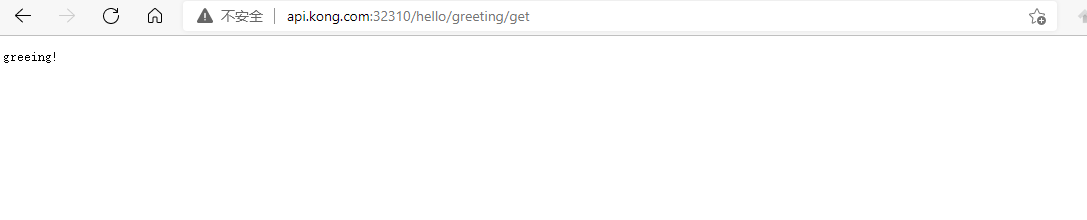
可以看到已经能够正确的路由到了.到此为止我们整个服务的自动注册与发现到集群的部署就已经完成了
以上就是基本就是整个基于云原生的自动发布框架,在实际业务中多少会有不同,不过整体流程是一样的,小伙伴可以根据自身实际情况,来优化部署文件与部署脚本,使之更为通用性.
通常需要考虑以下几个方面
- 解决方案的命名规则
- 网关二级路由规则
- 镜像命名的规则
- 健康检查路由规则
- SVC命名规则
4. 服务配置
在上一个示例中,我们使用了本地配置文件,通常情况下,我们会根据环境变量,来加载不同的配置文件,比如当时测试环境时,我们加载的是appsettings.Development.json,当生产环境时,我们加载的是appsettings.Production.json.
如果我们想变更某个配置,那就需要将所有已经发布的程序,重新发布一遍,在云原生与微服务的环境下,这种做法则会有巨大的效率问题,所以我们可以将我们的配置放到应用程序外部,这样变更配置就不用发布版本.所以我们应首选配置中心来实现我们的配置.
1. Apollo

Apollo是携程框架部门研发的分布式配置中心,能够集中化管理应用的不同环境,不同集群配置,配置修改后能够及时的推送到应用端.并且提供Web控制台,
Apollo主要分为以下几个模块
- MySQL,Apollo将所有的数据存到MySQL数据库中
- Config Service,提供配置读取,推送等功能.服务对象是客户端
- Admin Service,提供配置的修改,发布等功能,服务对象是Apollo Proral(管理界面)
- Protal管理界面
2. 环境规划
Apollo支持一套系统多个环境的配置.在本文中用到了两个环境,一个是本地的开发环境,一个是线上集群内部环境.所以我们规划两套环境配置,定义如下
- DEV为本地开发环境
- PRO为集群内部环境
整体规划如下
| 环境 | 服务名称 | 数据库 | 端口 |
|---|---|---|---|
| DEV | ConfigService | ApolloConfigDBDEV | 8080 |
| DEV | AdminService | ApolloConfigDBDEV | 8090 |
| PRO | ConfigService | ApolloConfigDBPRO | 8081 |
| PRO | AdminService | ApolloConfigDBPRO | 8091 |
| 不区分 | Protal | ApolloPortalDB | 8000 |
3. 多环境部署
由于我们的Kubernetes部署架构为无状态的,所以我们将Apollo部署到cd这台服务器.
1. 初始化数据库
DEV环境
初始化DEV环境数据库ApolloConfigDBDEV
脚本:apolloconfigdb.sql
下载地址:https://github.com/apolloconfig/apollo/blob/master/scripts/docker-quick-start/sql/apolloconfigdb.sql
注意需要更改默认数据库ApolloConfigDB->ApolloConfigDBDEV
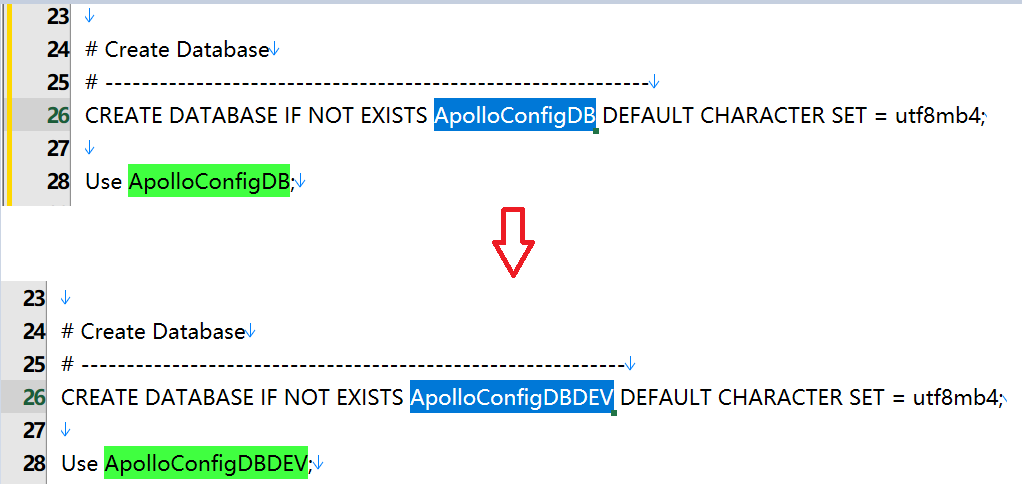
然后执行数据库脚本即可
PRO环境
初始化PRO环境数据库ApolloConfigDBPRO
脚本:apolloconfigdb.sql
下载地址:https://github.com/apolloconfig/apollo/blob/master/scripts/docker-quick-start/sql/apolloconfigdb.sql
注意需要更改默认数据库ApolloConfigDB->ApolloConfigDBPRO
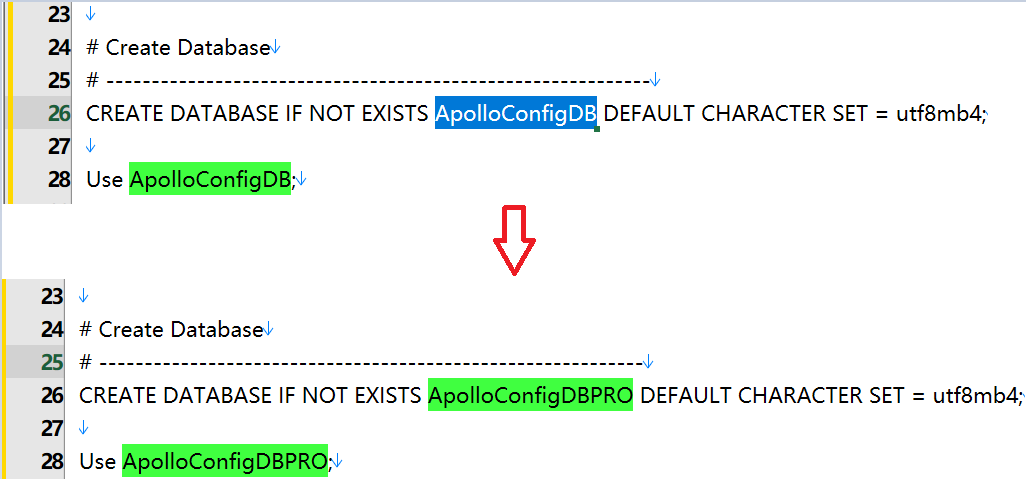
然后执行数据库脚本即可
Portal
脚本apolloportaldb.sql
下载地址:https://github.com/apolloconfig/apollo/blob/master/scripts/docker-quick-start/sql/apolloportaldb.sql
然后执行数据库脚本即可
最终数据库部署如下
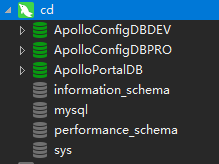
2. 部署镜像
一. 部署环境DEV
Config Service
docker run -p 8080:8080 --restart=always \
-e SPRING_DATASOURCE_URL="jdbc:mysql://cd:3306/ApolloConfigDBDEV?characterEncoding=utf8" \
-e SPRING_DATASOURCE_USERNAME=root -e SPRING_DATASOURCE_PASSWORD=123456 \
-e SERVER_PORT=8080 \
-d -v /tmp/logs:/opt/logs \
--name apollo-configservice-dev apolloconfig/apollo-configservice:1.7.1
2
3
4
5
6
Admin Service
docker run -p 8090:8090 --restart=always \
-e SPRING_DATASOURCE_URL="jdbc:mysql://cd:3306/ApolloConfigDBDEV?characterEncoding=utf8" \
-e SPRING_DATASOURCE_USERNAME=root -e SPRING_DATASOURCE_PASSWORD=123456 \
-d -v /tmp/logs:/opt/logs \
--name apollo-adminservice-dev apolloconfig/apollo-adminservice:1.7.1
2
3
4
5
二. 部署环境PRO
Config Service
docker run -p 8081:8081 --restart=always \
-e SPRING_DATASOURCE_URL="jdbc:mysql://cd:3306/ApolloConfigDBPRO?characterEncoding=utf8" \
-e SPRING_DATASOURCE_USERNAME=root -e SPRING_DATASOURCE_PASSWORD=123456 \
-e SERVER_PORT=8081 \
-d -v /tmp/logs:/opt/logs \
--name apollo-configservice-pro apolloconfig/apollo-configservice:1.7.1
2
3
4
5
6
Admin Service
docker run -p 8091:8090 --restart=always \
-e SPRING_DATASOURCE_URL="jdbc:mysql://cd:3306/ApolloConfigDBPRO?characterEncoding=utf8" \
-e SPRING_DATASOURCE_USERNAME=root -e SPRING_DATASOURCE_PASSWORD=123456 \
-d -v /tmp/logs:/opt/logs \
--name apollo-adminservice-pro apolloconfig/apollo-adminservice:1.7.1
2
3
4
5
三. 部署Portal
docker run -p 8000:8070 --restart=always \
-e SPRING_DATASOURCE_URL="jdbc:mysql://cd:3306/ApolloPortalDB?characterEncoding=utf8" \
-e SPRING_DATASOURCE_USERNAME=root -e SPRING_DATASOURCE_PASSWORD=123456 \
-e APOLLO_PORTAL_ENVS=dev,pro \
-e DEV_META=http://cd:8080 -e PRO_META=http://cd:8081 \
-d -v /tmp/logs:/opt/logs \
--name apollo-portal apolloconfig/apollo-portal:1.7.1
2
3
4
5
6
7
四. 修改apollo-portal参数
[root@cd ~]# docker exec -it apollo-portal bash
bash-4.4# vi /apollo-portal/config/apollo-env.properties
#更改为以下内容
dev.meta=http://cd:8080
pro.meta=http://cd:8081
bash-4.4# bash-4.4# cat /apollo-portal/config/apollo-env.properties
dev.meta=http://cd:8080
pro.meta=http://cd:8081
2
3
4
5
6
7
8
9
10
四. 更新数据库
apollo-configservice本身就是一个eureka服务,所以需要调整数据库配置,让其检测自身的地址
修改ApolloConfigDBDEV.ServerConfig表中的eureka.service.url字段

修改ApolloConfigDBPRO.ServerConfig表中的eureka.service.url字段

修改ApolloPortalDB.ServerConfig表中的apollo.portal.envs字段与configView.memberOnly.envs
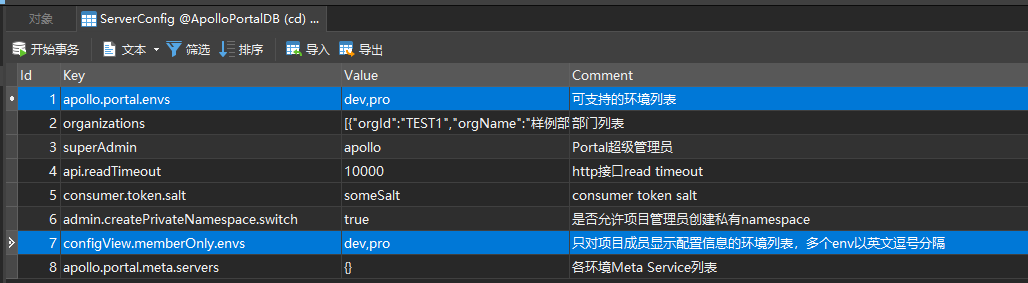
因为我们使用的是容器部署,所以apollo-configservice绑定的是容器内部的IP地址
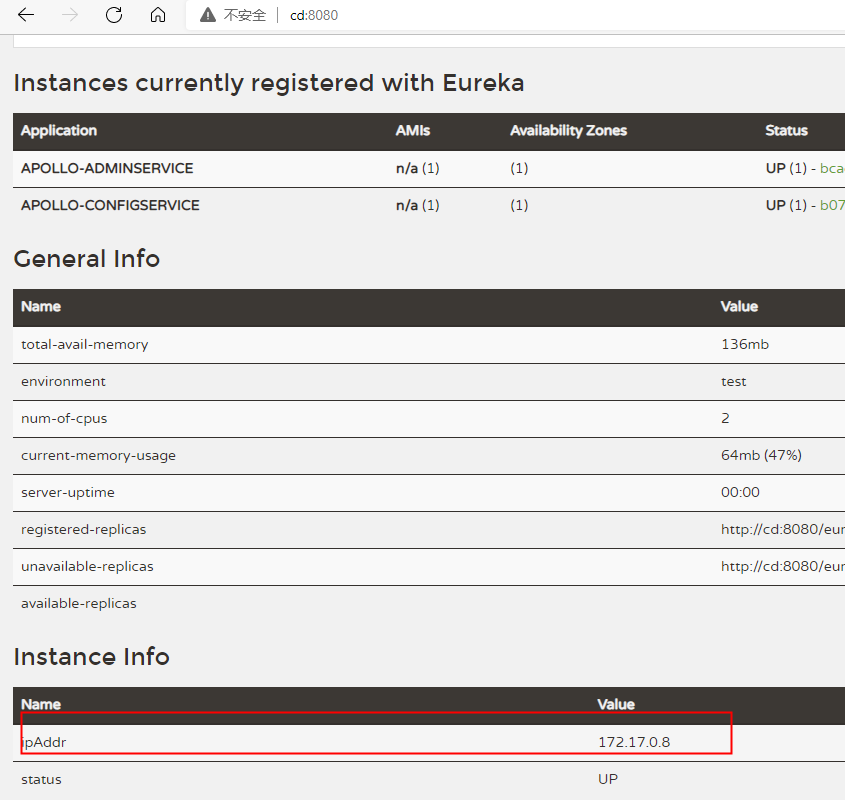
所以我们需要修改eureka注册的外网地址,修改每一个apollo-configservice容器内部的启动脚本startup.sh,通过JVM注入参数: -Deureka.instance.ip-address=这里为宿主机IP地址
[root@cd ~]# docker exec -it b078f3bf0d4c bash
bash-4.4# vi /apollo-configservice/scripts/startup.sh
2
在第18行末端,增加该参数即可.

然后重启每个容器即可.然后我们访问http://cd:8080,就可以看到IP地址已经更改成本机IP
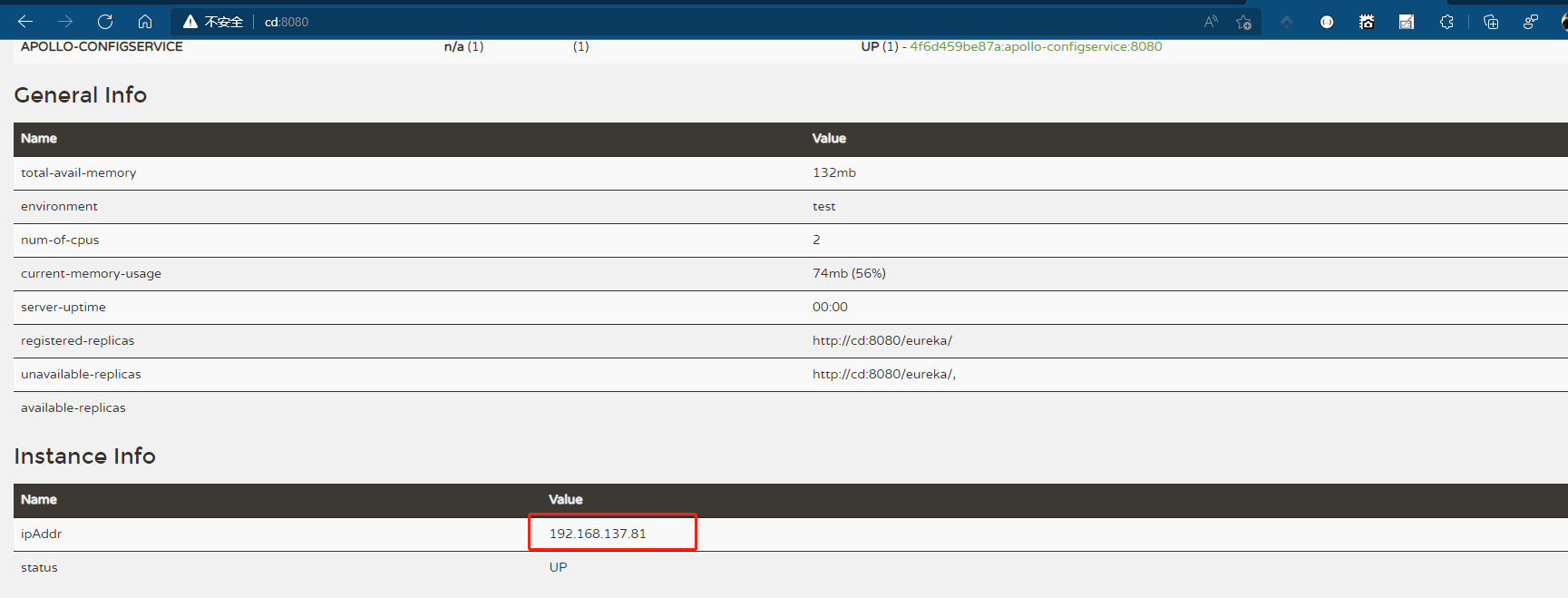
访问Portal地址http://cd:8000,默认用户名密码:apollo,admin
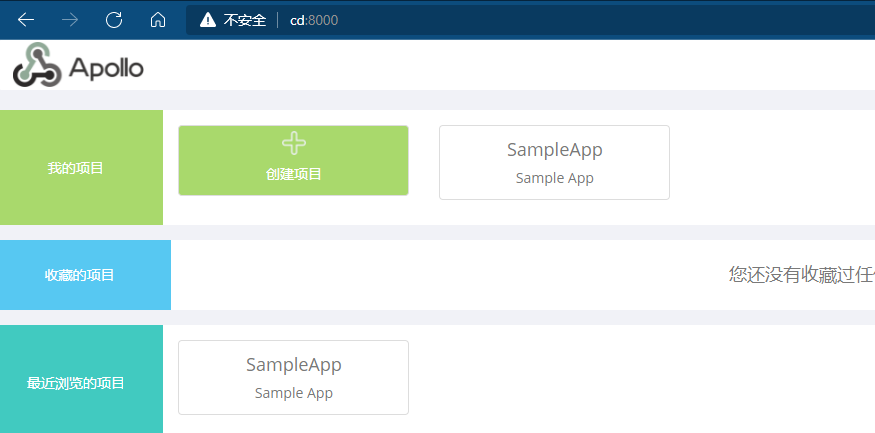
点击SampleApp,可以看到已经加载了两个环境的配置
在系统信息中可以看到Home Page Url已经成为了本机IP地址

至此,Apollo部署完毕.
4. 使用Apollo
默认情况下,Apollo会初始化一个名为SampleApp的配置,并且具有timeout的配置项
接下来我们新建一个SampleApp的项目来读取timeout配置项.
该项目引用以下包
Com.Ctrip.Framework.Apollo.Configuration
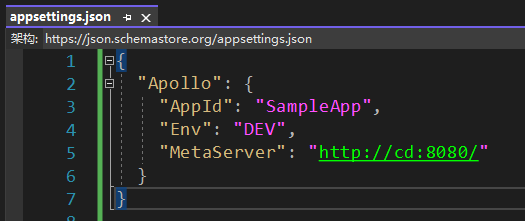
在appsettings.json中,增加Apollo的配置
在Program.cs中引用Apollo
public class Program
{
public static void Main(string[] args)
{
CreateHostBuilder(args).Build().Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureAppConfiguration((hostBuilder, config) =>
{
config.AddApollo(config.Build().GetSection("Apollo")).AddDefault();
}) .ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在WeatherForecastController.cs中注入IConfiguration对象
[ApiController]
[Route("[controller]")]
public class WeatherForecastController : ControllerBase
{
private readonly ILogger<WeatherForecastController> _logger;
IConfiguration Configuration;
public WeatherForecastController(ILogger<WeatherForecastController> logger, IConfiguration configuration)
{
_logger = logger;
this.Configuration = configuration;
}
[HttpGet]
public IActionResult Get()
{
return this.Ok(this.Configuration["timeout"]);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
然后访问该接口,可以看到100已经被读取出来.此时应用调试不要停止
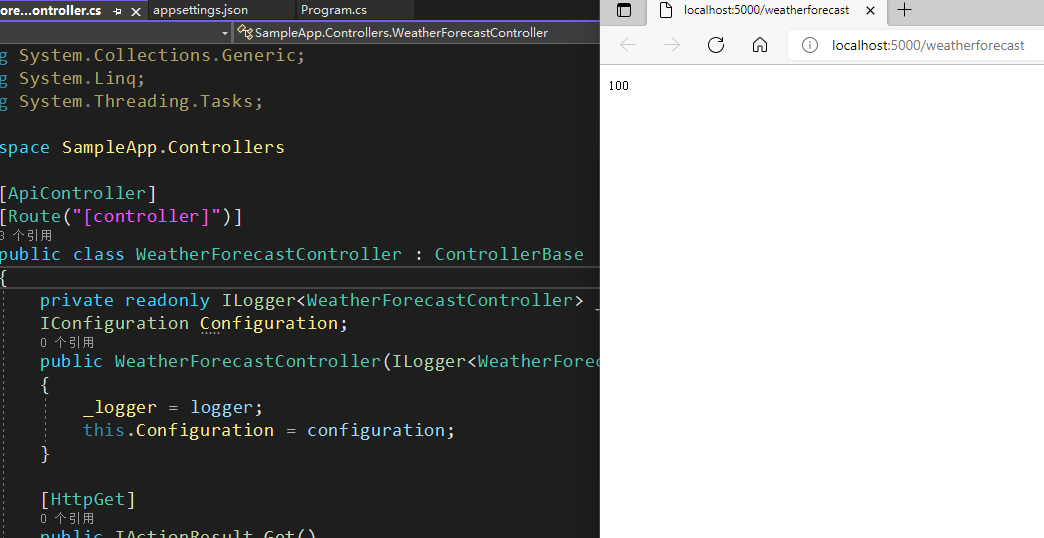
接下来,我们在Apollo中更改timeout的值为1000,然后直接刷新接口
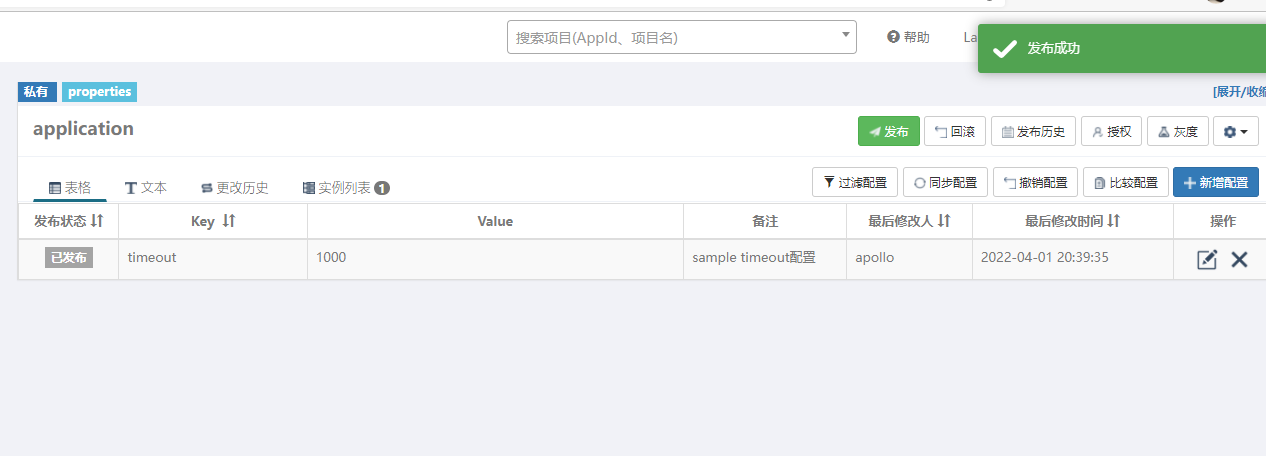
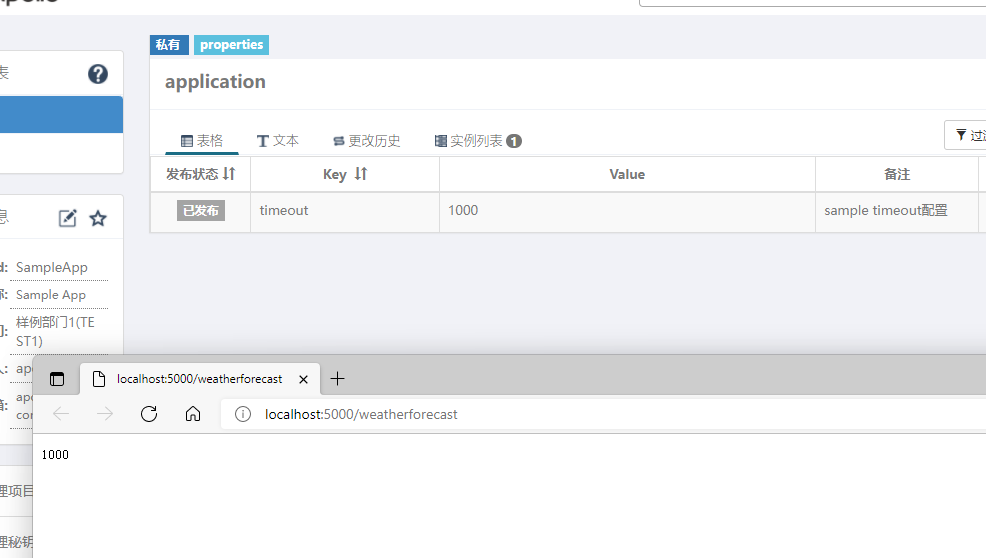
可以看到已经变成1000了.,这就是Apollo实时配置的能力
5. 优化hello.http
在第二章 架构规划中的2.3.4中我们使用的是基于appsettings.json的配置,接下来,我将该配置移到Apollo中
根据我们的规划
DEV为本地开发环境
PRO为集群内部环境
我们现在创建一个项目,名为hello.http
创建后,Apollo会为新项目添加一个默认的私有Namesapce叫做application,类型是properties.
Namesapce有两种范围public和private,
- public 为公开,所有都有可以关联,该类型的数据格式只能是properties,该数据格式就是键值对(key-value)
- private为私有,只能自己的项目访问.该类型具有多种数据格式
,我们创建一个Namesapce名为kong,类型为private,数据格式为json
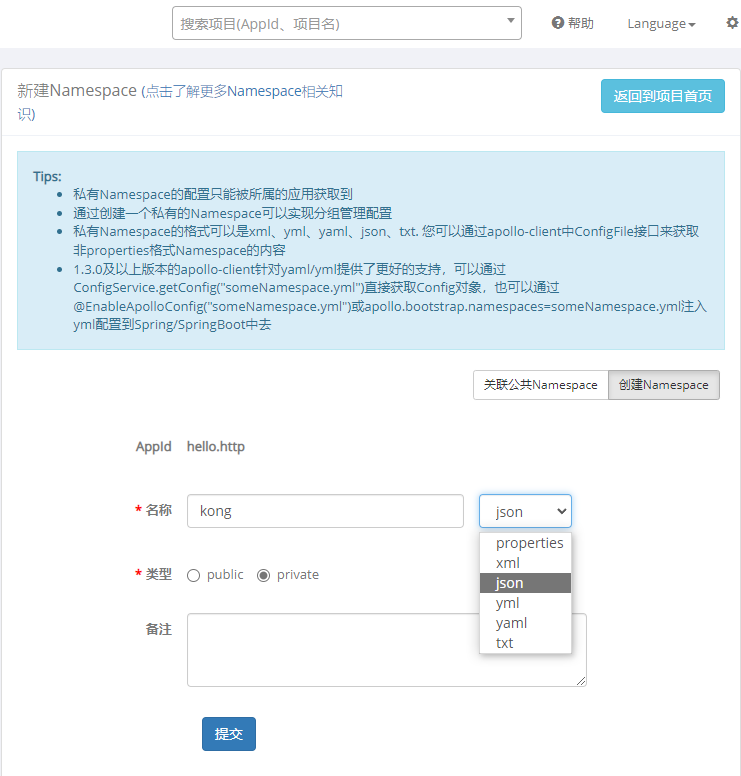
然后我们将hello.http项目中关于kong的配置复制到该配置项里,然后点击发布,然后同步到PRO环境中
注 kong的Namespace可以为空,因为我们本地环境时,不需要向kong注册.
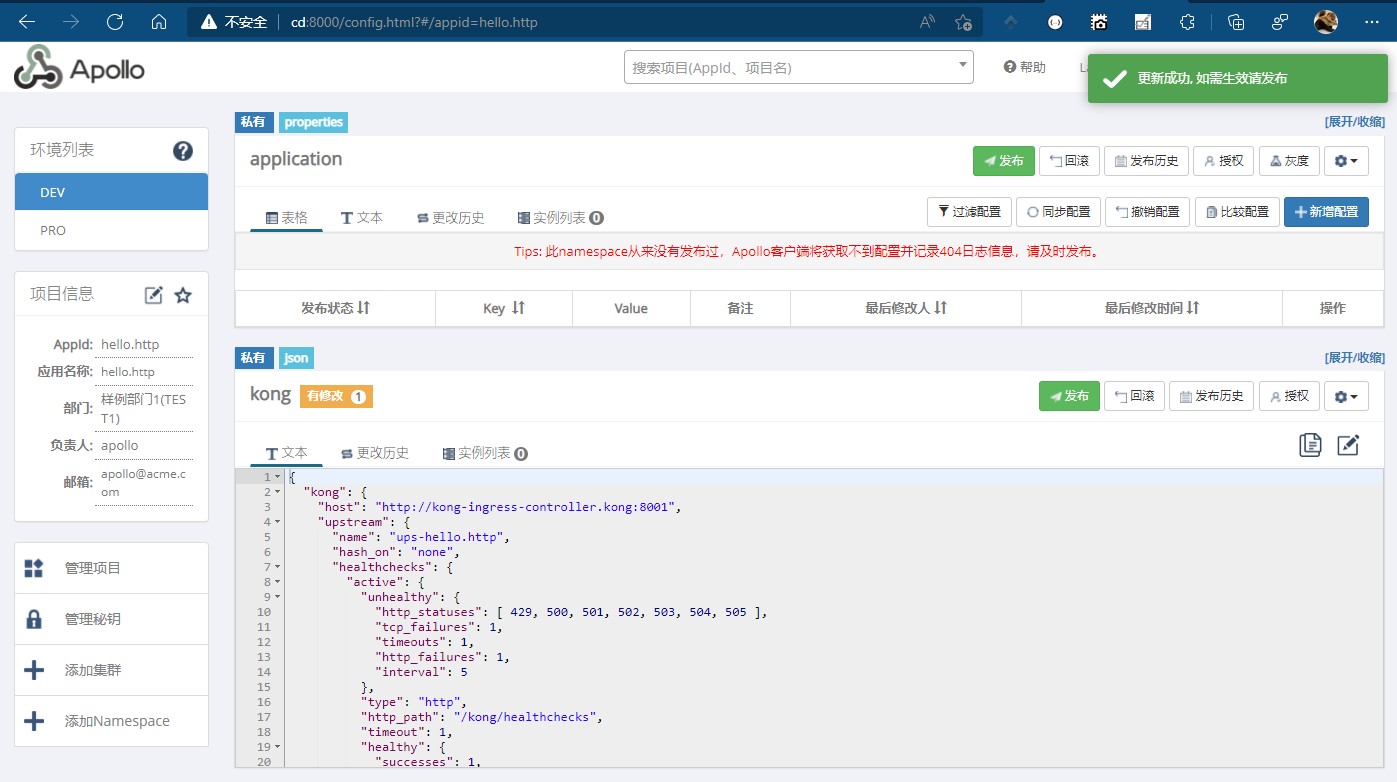
这时候,该配置并没有生效,我们需要发布配置,使配置生效
由于我们定义了两个环境DEV与PRO.所以我们最终为两个配置文件
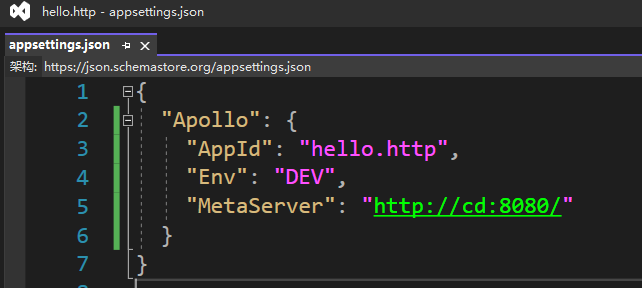
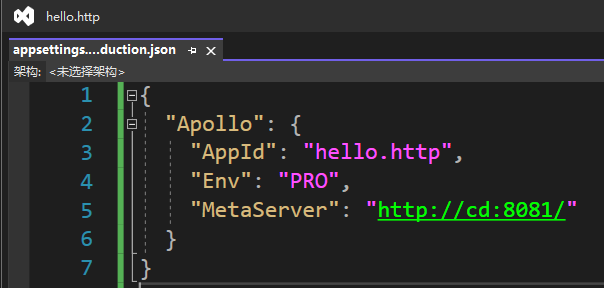
- appsettings.json DEV环境,作为本地开发时加载
- appsettings.Production.json,PRO环境,作为集群内部使用
最终两个配置文件如下:
在hello.http项目中引用包:Com.Ctrip.Framework.Apollo.Configuration
修改Program.cs,增加对于Apollo的引用,然后Apollo添加Kong的Namespace
using Com.Ctrip.Framework.Apollo;
using Com.Ctrip.Framework.Apollo.Enums;
namespace hello.http
{
public class Program
{
public static void Main(string[] args)
{
CreateHostBuilder(args).Build().Run();
}
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureAppConfiguration((hostBuilder, config) =>
{
config.AddApollo(config.Build().GetSection("Apollo")).AddDefault()
.AddNamespace("kong", ConfigFileFormat.Json);
}).ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
然后我们调试一下
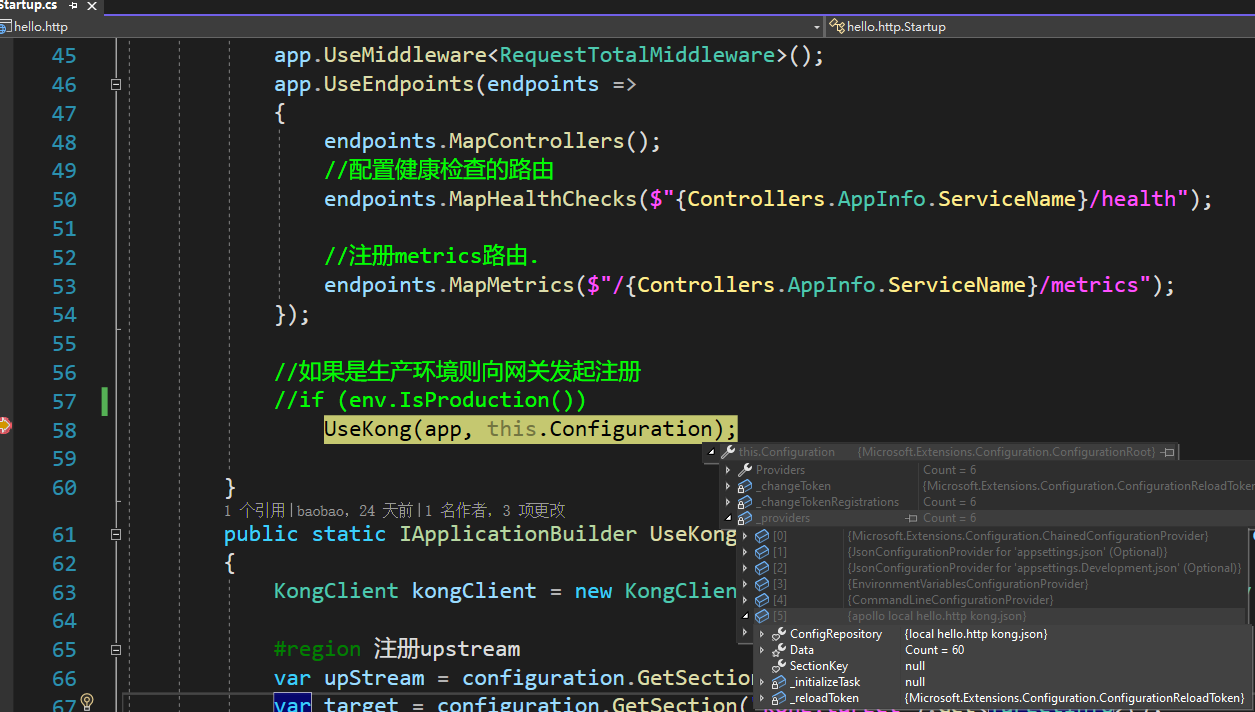
可以看到configuration对象的providers多了apollo,并Data已经加载出了60项配置.
为了演示分布式配置加自动注册,我们在konga中删除关于hello的路由
删除Service
删除Routers
删除UpStream
在Kubernetes集群中,删除之前部署的hello.http
[root@master ~]# kubectl delete deploy hello-http -n dotnet
deployment.apps "hello-http" deleted
2
将代码提交后,我们在Teamcity中,构建该项目
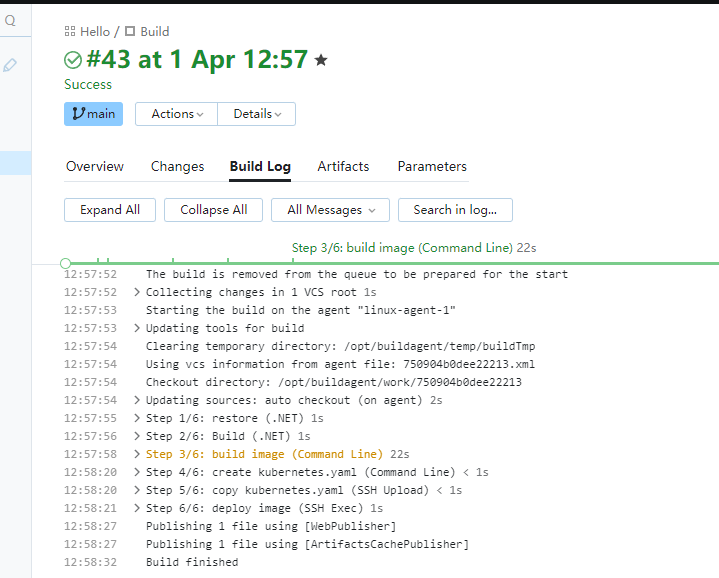
构建成功,并且已经部署成功了
[root@master deploy]# kubectl get all -ndotnet
NAME READY STATUS RESTARTS AGE
pod/hello-http-585c76d476-lmxf5 1/1 Running 0 72s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/svc-hello-http ClusterIP 10.100.178.30 <none> 80/TCP 13d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hello-http 1/1 1 1 9m17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/hello-http-585c76d476 1 1 1 9m17s
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/hpa-hello-http Deployment/hello-http 0%/50% 1 3 1 13d
2
3
4
5
6
7
8
9
10
11
12
13
14
15
我们刷新konga
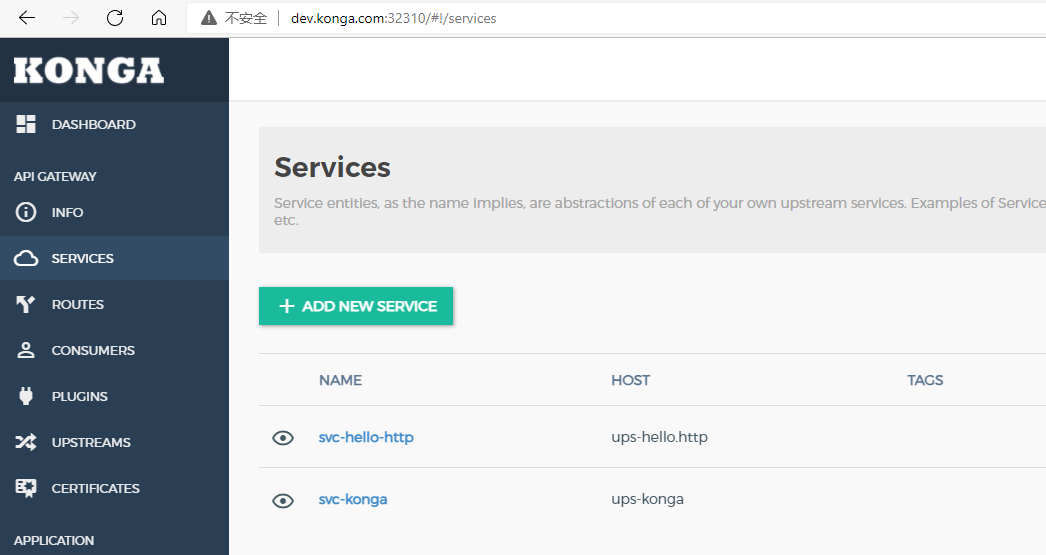
可以看到已经自动注册成功,访问该服务的路由地址:http://api.kong.com:32310/hello/greeting/get
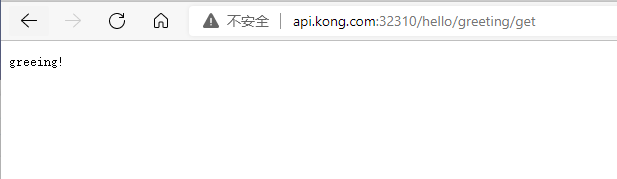
至此整个服务配置完成
5. 服务调用
在服务化体系架构中,服务与服务之间会有交互,交互方式通常有两种
- 同步,基于HTTP或者RPC形式调用
- 异步,基于消息的事件驱动形式
由于异步形式通常需要做很多额外业务操作,所以我们只介绍HTTP协议的RESTful风格的接口,我们通常使用HttpClient进行接口访问.
1. Polly
Polly 是一个 .NET 弹性和瞬态故障处理库,允许开发人员以来实现重试、断路、超时、隔离和回退策略.

Polly具体能力如下:
- 失败重试:调用失败时,能自动重试。
- 服务熔断:部分服务不可用时,快速响应熔断结果;避免持续请求不可用服务。
- 超时处理:为请求设置超时时间,当超过超时时间时,按预定的操作进行处理
- 舱壁隔离:限流,为服务定义最大流量和队列,避免服务因为压力过大而崩溃。
- 缓存策略:以AOP的方式为服务嵌入缓存的机制。
- 失败降级:当服务不可用时,响应一个友好的结果而不是报错。
- 组合策略:将以上能力组合在一起。
Polly基本使用步骤为:1 定义策略,2执行策略,我们来看一个基本使用方法.
- 定义策略,策略中指定负责处理的异常
- 执行策略
我们定义一个基本策略:请求失败时,每1秒重试一次,共计重试2次.然后请求一个不存在的地址
static void Main(string[] args)
{
//定义策略
var policy = Policy.Handle<Exception>().WaitAndRetry(2, _=> TimeSpan.FromSeconds(1));
//执行方法
int i = 0;
var result = policy.ExecuteAndCapture(() =>
{
i++;
Console.WriteLine("try:{0}", i);
var httpclient = new HttpClient();
var result = httpclient.GetStringAsync("http://localhost:222").Result;
});
//输出结果
Console.WriteLine(result.Outcome);
Console.ReadLine();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
然后查看运行结果,可以看到在函数内部被执行了3次,因为初始1次,然后失败重试2次,所以共计3次,

2. Polly+HttpClient
在第一个示例中可以看到,直接使用Polly对代码的入侵比较大,意味着每个HTTP请求都需要使用Polly进行Excute,那么有没有一种比较简单的办法来使用Polly呢?在asp.netcore中,我们进行HTTP请求,一定会使用HttpClientFactory对象.那么我们就可以将该对象与Polly进行结合来使用.
引用包:
Microsoft.Extensions.Http.Polly
该包使用也非常简单,代码简明易读,当然扩展包也支持我们添加自定义策略
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddHttpClient("default").AddTransientHttpErrorPolicy(p =>
{
var policy = p.WaitAndRetryAsync(3, t => TimeSpan.FromSeconds(3));
return policy;
});
}
2
3
4
5
6
7
8
9
该包扩展了IHttpClientBuilder对象,其中AddTransientHttpErrorPolicy方法默认处理HTTP状态码为5XX与408,因为我们的应用程序是部署在Kubernetes集群中的,Kubernetes负责我们应用的可用性与伸缩性,所以通常只处理5XX与408状态就要可以适应大部分场景
使用HttpClient则与以往没有任何区别,
public class WeatherForecastController : ControllerBase
{
IHttpClientFactory factory;
public WeatherForecastController(IHttpClientFactory httpClientFactory)
{
this.factory = httpClientFactory;
}
[HttpGet]
public async Task<IActionResult> Get()
{
var client = this.factory.CreateClient("default");
var result = await client.GetAsync("http://api.kong.com:32310/hello/greeting/get");
return this.Ok(result);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
3. Refit+Polly
Refit是自动类型安全的REST库,借助该库,我们可以快速构建基于本地化服务的HTTP请求
引用包:
Refit
Refit基本使用方法有两种
首先我们定义服务接口
public interface IHelloServie
{
[Get("/hello/greeting/get")]
Task<string> hello();
}
2
3
4
5
使用方式一
var service = RestService.For<IHelloServie>("http://api.kong.com:32310");
var result = await service.hello();
2
使用方式二
项目引用包:Refit.HttpClientFactory
在Startup.cs中注入服务
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddRefitClient<IHelloServie>().ConfigureHttpClient(options =>
{
options.BaseAddress = new Uri("http://api.kong.com:32310");
});
}
2
3
4
5
6
7
8
在Controller中注入该服务即可
[ApiController]
[Route("[controller]")]
public class WeatherForecastController : ControllerBase
{
IHelloServie HelloService;
public WeatherForecastController(IHelloServie helloService)
{
this.HelloService = helloService;
}
[HttpGet]
public async Task<IActionResult> Get()
{
var result = await this.HelloService.hello();
return this.Ok(result);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
接下来.我们将Refit与Polly结合,快速构建具有无入侵试的执行策略.我们修改一下Startup.cs中注入的方法即可
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddRefitClient<IHelloServie>().ConfigureHttpClient(options =>
{
options.BaseAddress = new Uri("http://api.kong.com:32310");
}).AddTransientHttpErrorPolicy(p =>
{
var policy = p.WaitAndRetryAsync(3, _ => TimeSpan.FromSeconds(2));
return policy;
});
}
2
3
4
5
6
7
8
9
10
11
12
这样,我们既能简单方便的进行HTTP请求,还能实现各种自定义服务调用重试超时等策略.
4. 服务的幂等性
我们在编写一个服务时需要考虑到以下几点
- 避免使用http status code为5XX作为响应,可以使用200处理成功,400处理失败,404未找到,通常这三个状态码已经足够,如果有另外需要特定标示状态,可以使用业务协议自定义状态码即可
- 对于http get请求,只应作为查询数据,不应存储数据.对于该请求应该使用缓存策略,如输出缓存,内存缓存,外部缓存,缓存可以有效提高承载量,还可以提高服务的可用性
- 对于http put/post请求,需要支持幂等性,避免因网络闪断导致调用方进行重试时,会造成多次重复数据.比如被调用放不要创建业务主键,而是由调用方传入业务主键.避免使用自增长ID作为业务主键.必要时可引入消息队列.
6. 链路追踪
在服务化架构中,服务与服务之间的关系越来越复杂,一旦某个服务出现问题,那么排查起来也是极为困难,同时也给系统运维带来了极大的挑战.为了应对这种变化,我们可以通过三套系统来解决问题.日志系统,度量系统,链路追踪系统
接下来我们介绍一下链路追踪系统
1. zipkin
zipkin是一个开源的分布式追踪系统,并且提供WEB UI用于查看追踪数据,zipkin已在Twitter内部大规模使用.

zipkin主要有以下几个部分
- 上报端,即我们的应用程序
- 服务端,接受上报端的数据进行存储
- 存储,默认为InMemory,还支持MySql,Cassandra,Elasticsearch
- Web UI 提供数据查询与查看
2. 安装
我们在cd这台服务器安装zipkin,存储使用mysql
一 创建数据库:zipkin
create database zipkin;
二 初始化表结构, 官方初始化文件地址:zipkin/mysql.sql at master · openzipkin/zipkin (github.com)
三 部署镜像
[root@cd ~]# docker run -d -p 9411:9411 --restart=always \
> -e STORAGE_TYPE=mysql \
> -e MYSQL_HOST=cd \
> -e MYSQL_USER=root \
> -e MYSQL_PASS=123456 openzipkin/zipkin
475ce728b5c36fac5c88148975889fb20db7080f9affd09bd8e69e302819aed0
[root@cd ~]#
2
3
4
5
6
7
访问http://cd:9411,至此zipkin就部署完毕
2. 使用
在asp.netcore中想要使用zipkin需要引用以下包
zipkin4net.middleware.aspnetcore
我们在hello.http项目引用该包
接下来在Startup.cs增加一个**UseZipkin()**方法
void UseZipkin(IApplicationBuilder app)
{
var lifetime = app.ApplicationServices.GetService<IHostApplicationLifetime>();
lifetime.ApplicationStarted.Register(() =>
{
//采集频率
TraceManager.SamplingRate = 1.0f;
//实例化一个http的追踪器,zipkin的服务地址与contentType
var httpSender = new HttpZipkinSender("http://cd:9411", "application/json");
TraceManager.RegisterTracer(new ZipkinTracer(httpSender, new JSONSpanSerializer(), new Statistics()));
//添加一个控制台类型的追踪器
TraceManager.RegisterTracer(new ConsoleTracer());
var loggerFactory = app.ApplicationServices.GetService<ILoggerFactory>();
TraceManager.Start(new TracingLogger(loggerFactory, "zipkin"));
});
lifetime.ApplicationStopped.Register(() => TraceManager.Stop());
//设置该服务名称
app.UseTracing(AppInfo.ServiceName);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在Configure方法中使用该方法

注意,该方法需要首先使用,**UseZipkin(app)**方法
方法app.UseTracing(AppInfo.ServiceName)是创建了一个Middleware,拦截了HTTP请求,所以应该在整个管道中作为第一个接受请求,
然后我们运行hello.http程序,在网页中多刷新几次
然后回到我们的zikin的Web UI,然后刷新
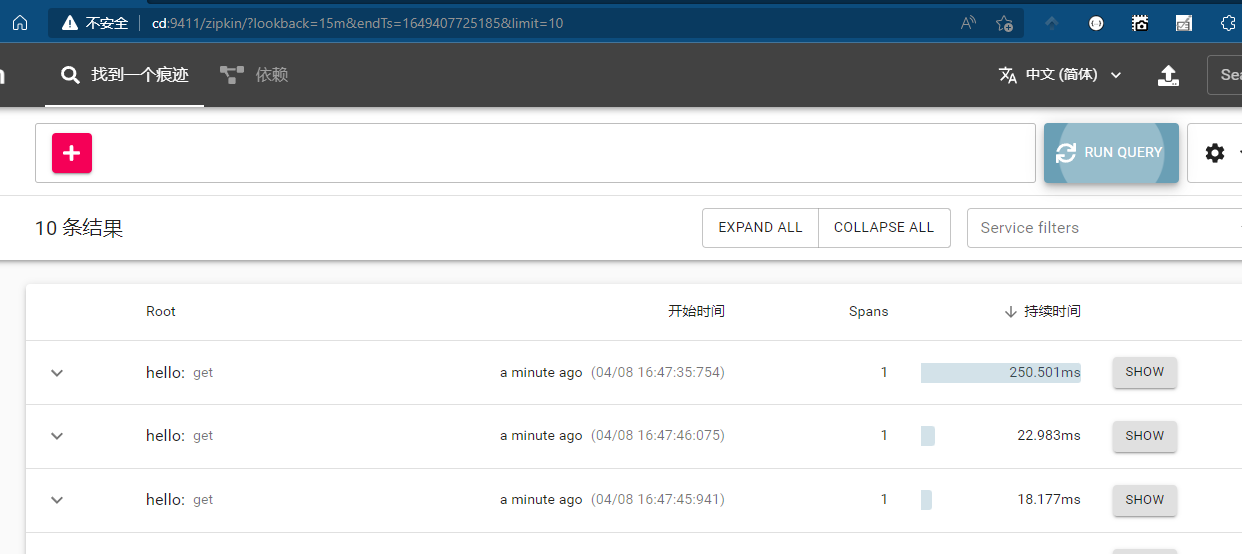
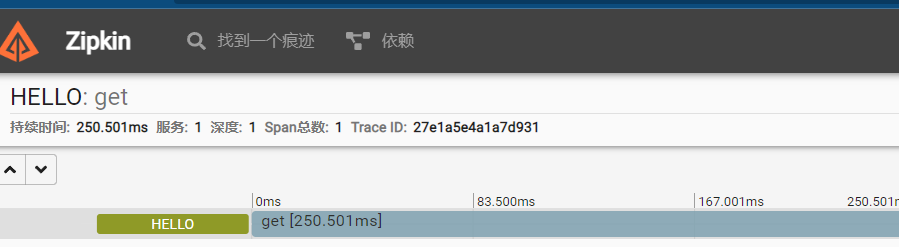
可以看到对于HTTP请求的追踪进行写入zipkin,我们可以点击SHOW查看详细
这里能标识出请求耗费的总时长,服务的深度是多少.
3. 实战全链路
接下来,我设计一个服务请求的流程,如下图
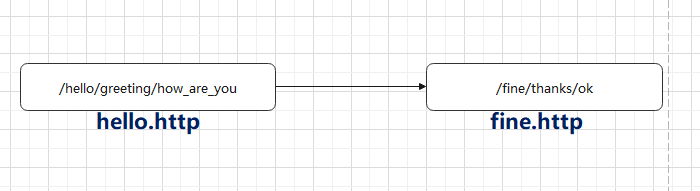
这两个项目引用以下包
Refit.HttpClientFactory
Microsoft.Extensions.Http.Polly
一 fine.http
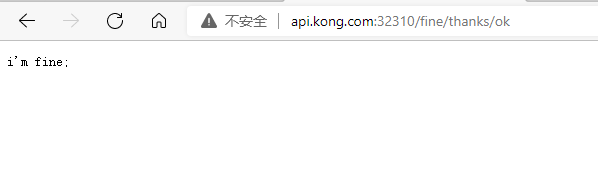
新建项目fine.http,并配置该项目的持续集成,使其能够发布到集群内部,配置过程可参考之前的章节,部署可以通过网关查看是否部署成功
访问网关地址:http://api.kong.com:32310/fine/thanks/ok
二 helllo.http
增加IFineService接口
public interface IFineService
{
[Get("/fine/thanks/ok")]
Task<string> Ok();
}
2
3
4
5
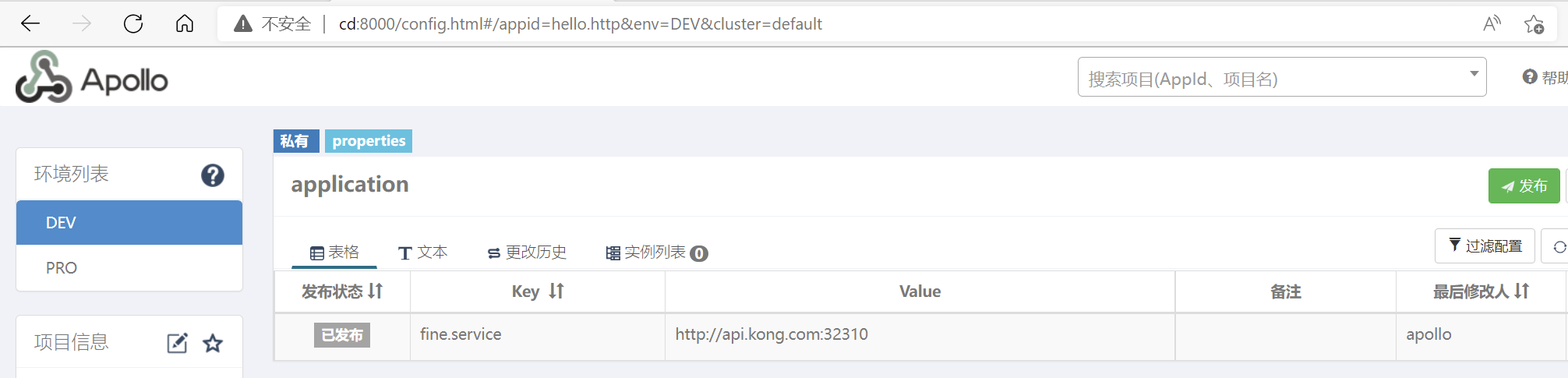
在Apollo中增加fine.http服务的请求地址
DEV环境:因为是我们本地的环境,所以需要通过网关去访问,
PRO环境:集群内部访问环境,所以通过Kubernetes的svc访问

在Startup.cs中增加RefitClient,增加重试机制,增加链路追踪
services.AddRefitClient<IFineService>()
.ConfigureHttpClient(options => options.BaseAddress = new Uri(Configuration["fine.service"]))
.AddTransientHttpErrorPolicy(p => p.WaitAndRetryAsync(3, _ => TimeSpan.FromSeconds(2)))
.AddHttpMessageHandler(_ => TracingHandler.WithoutInnerHandler(AppInfo.ServiceName));
2
3
4
在GreetingController中注入IFineService,并增加方法
IFineService FineService;
public GreetingController(IFineService fineService)
{
this.FineService = fineService;
}
[HttpGet]
public async Task<IActionResult> how_are_you()
{
var result = await this.FineService.Ok();
return this.Ok(result);
}
2
3
4
5
6
7
8
9
10
11
12
此时我们可以本地调试,可以看到此方法已经调通.
然后在查看zipkin
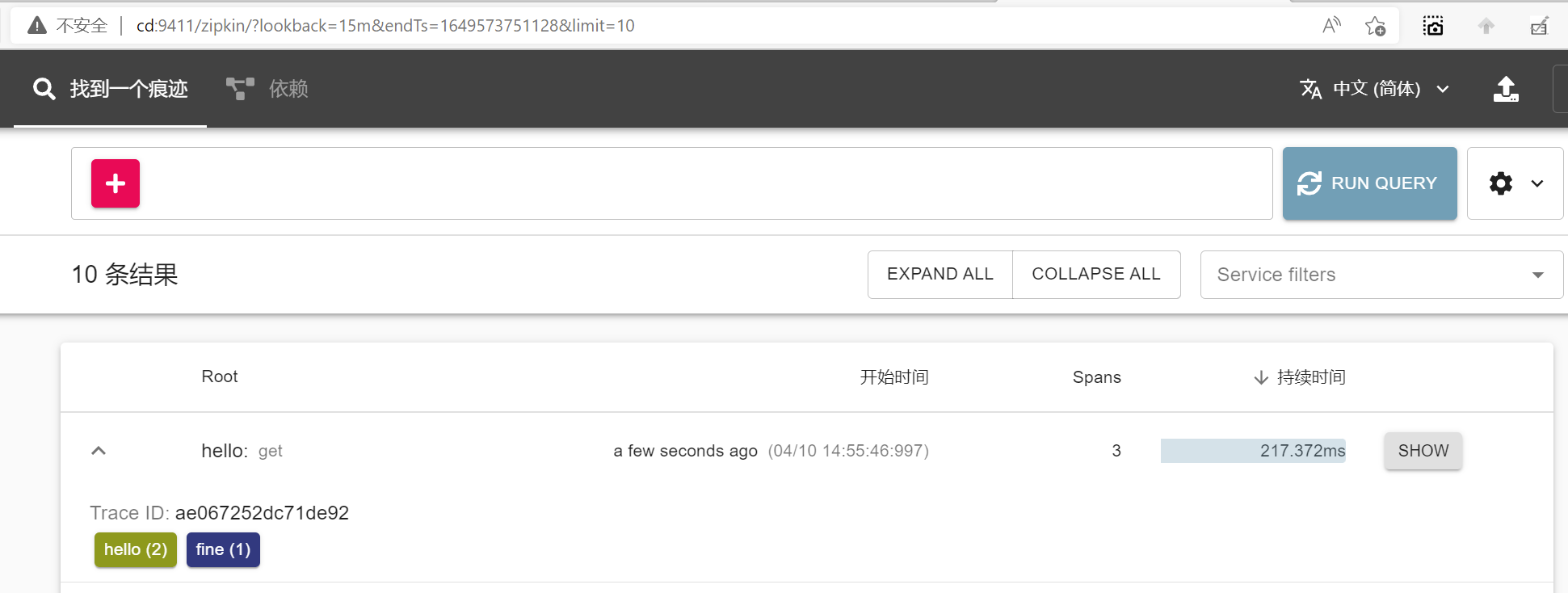
可以看到zipkin已经采集到数据,并且已经记录服务的持续时间,深度等信息,
该链路请求的路径为http://localost:5000,总持续时间18.252ms,其中fine服务持续时间6.878ms
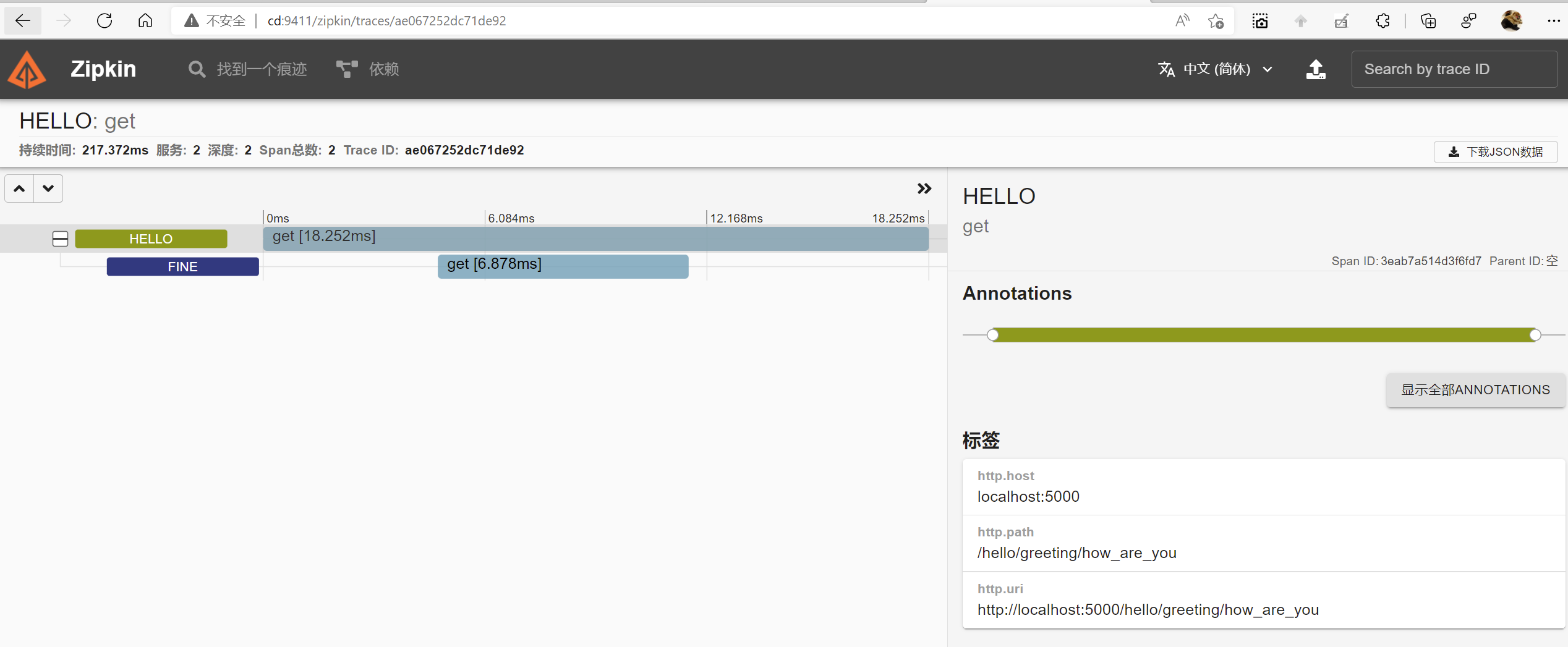
最后我们将项目提交代码库,并发布到集群中,通过网关访问hello.http再看一下
访问网关地址:http://api.kong.com:32310/hello/greeting/how_are_you
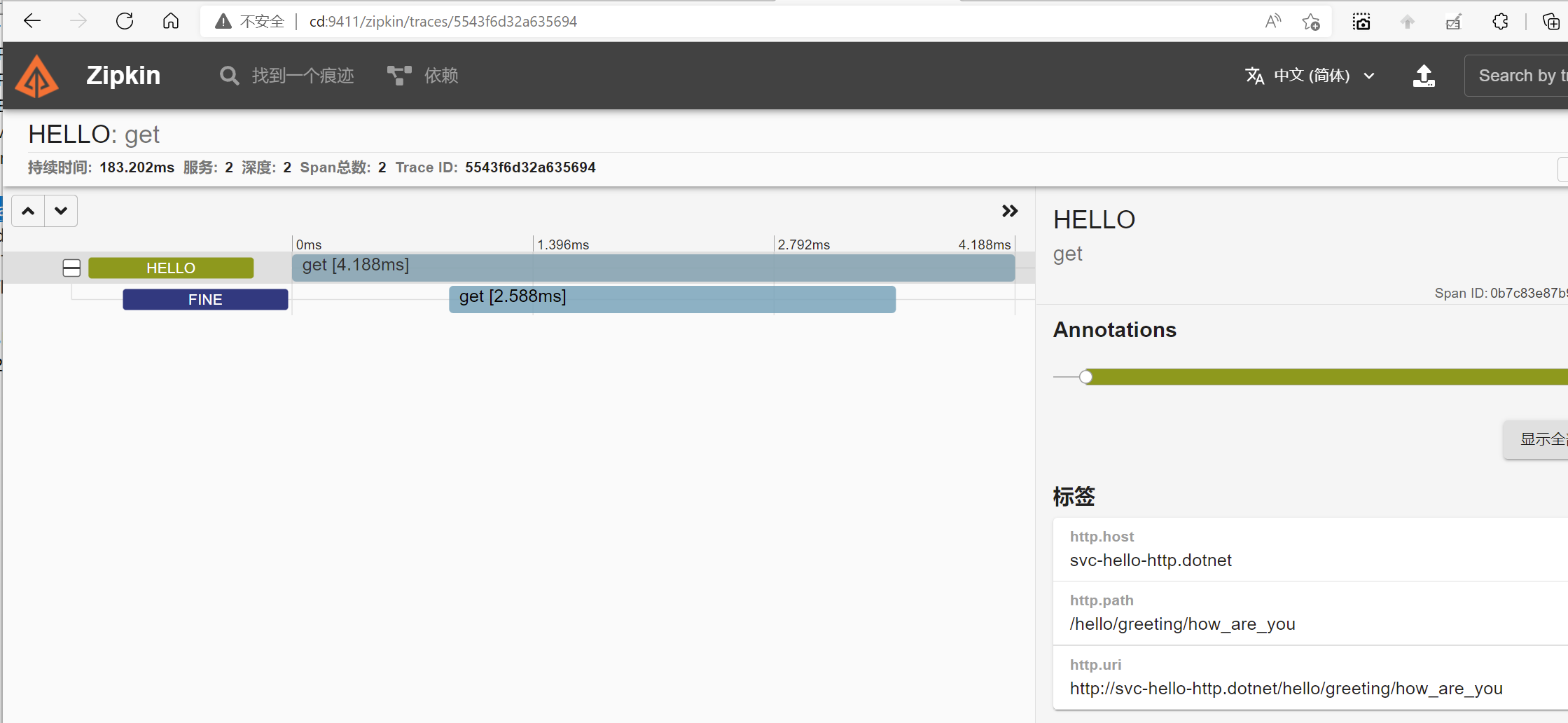
我们再次查看zipkin,可以看到链路的请求入站口已经变成了:http://svc-hello-http.dotnet了
至此,我们服务调用加链路追踪已经完成
7. 限流降级
限流与降级作为解决高并发的一种常用手段,限流与降级是为了保护我们的核心服务,避免高流量导致我们的服务崩溃.限流与降级并不能解决所有业务场景,比如秒杀,抢购等业务场景,并不适合该方案
1. 限流
限流的目的是为了通过对请求进行限速,保护系统,一旦超过了限定的速率,可以拒绝服务,通过拒绝服务保证服务一定程度上的可用.另外,可以根据系统的吞吐量,响应时间来动态调整限流的阈值.
常见的限流算法基本有三种:令牌桶,漏桶,计数器也可以粗粒度的实现限流
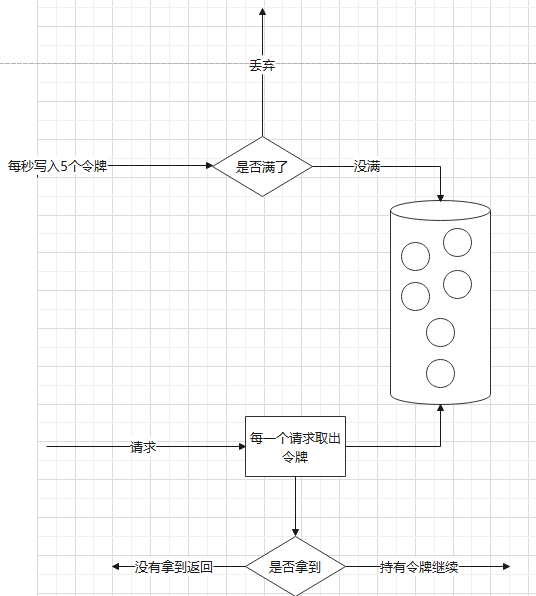
1. 令牌桶
该算法是存放一个固定数量的令牌桶,按照固定的速率往桶里添加令牌,如果桶满了,则丢弃令牌,基本步骤如下
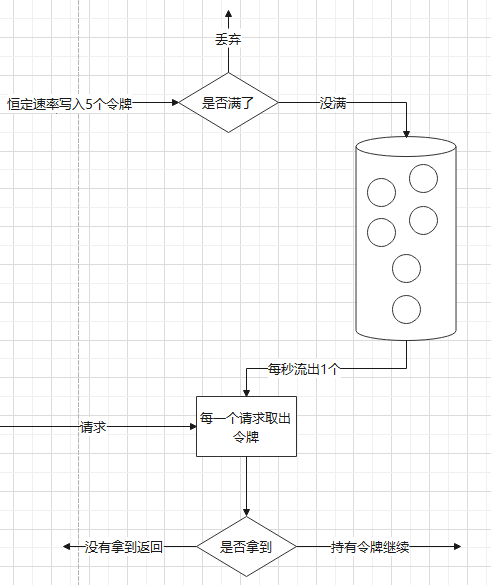
2. 漏桶
漏桶的算法是一个固定容量的桶,注入的速度不限,但是流出的速度为恒定,大体算法如下
这两种算法大体差不多,只是一个控制的是流入速度,一个控制的是流出速度
3. 计数器
某种场景下,我们可以用计数器来进行限流,计数器主要是用来限制总并发数.计数器实现的算法就比较简单,请求开始进行+1,请求结束-1,当到达某个阈值时,进行返回失败.
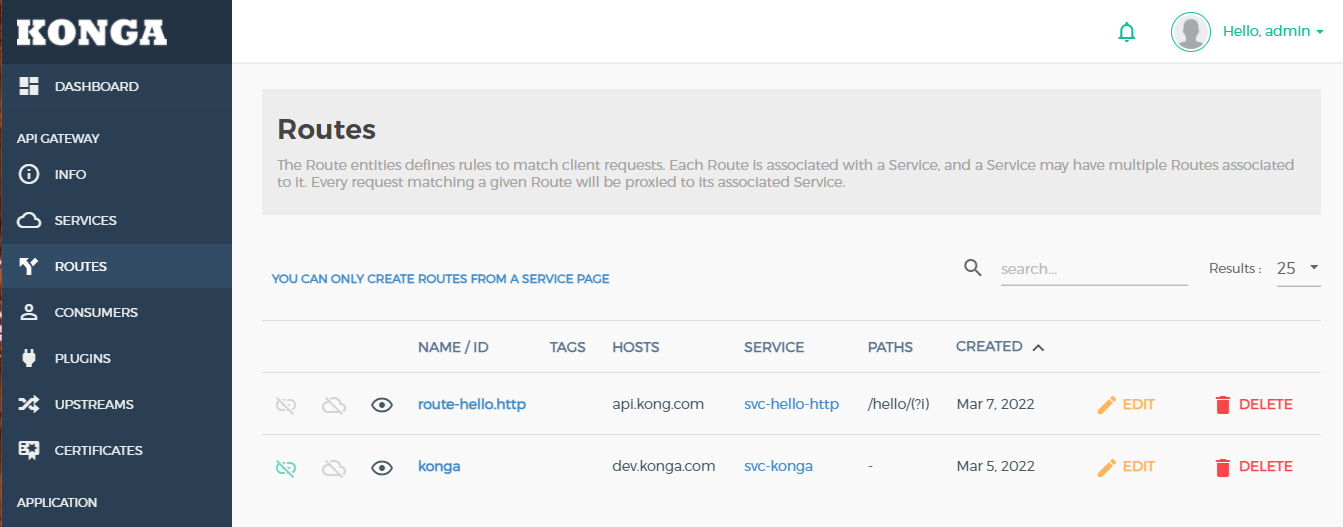
3. 网关层限流
Kong自带丰富的插件,其中就有限流插件,我们可以使用该插件在流量入口层来进行限流.我们演示一下如何在Kong网关层限流.
首先在ROUTE里选择route-hello.http,选择编辑
然后点击ADD PLUGIN
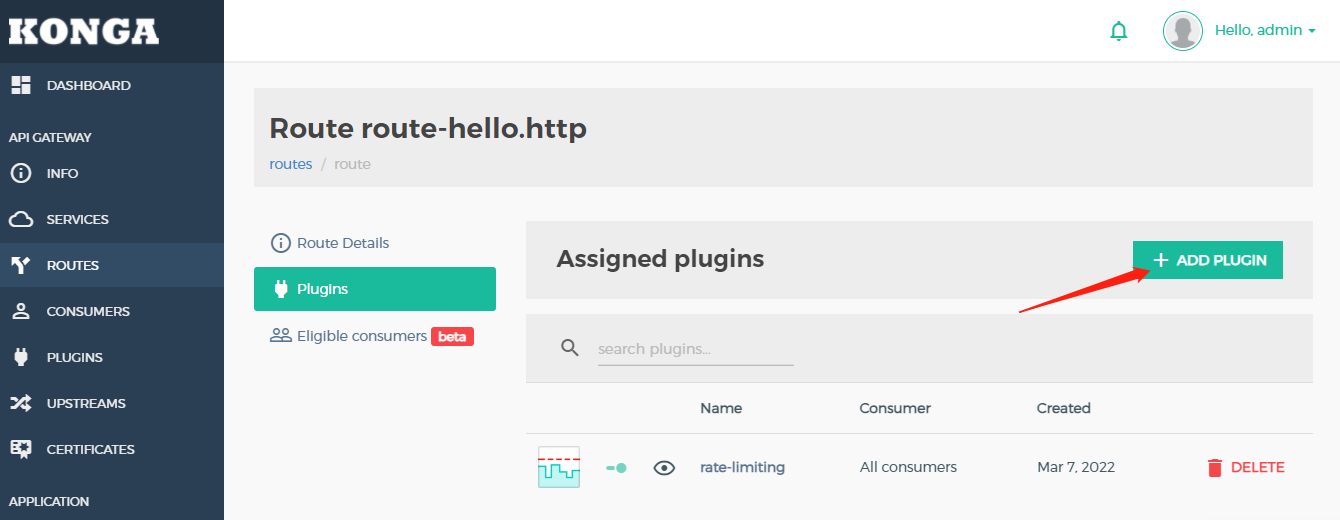
选择Traffic Control,添加Rate Limiting
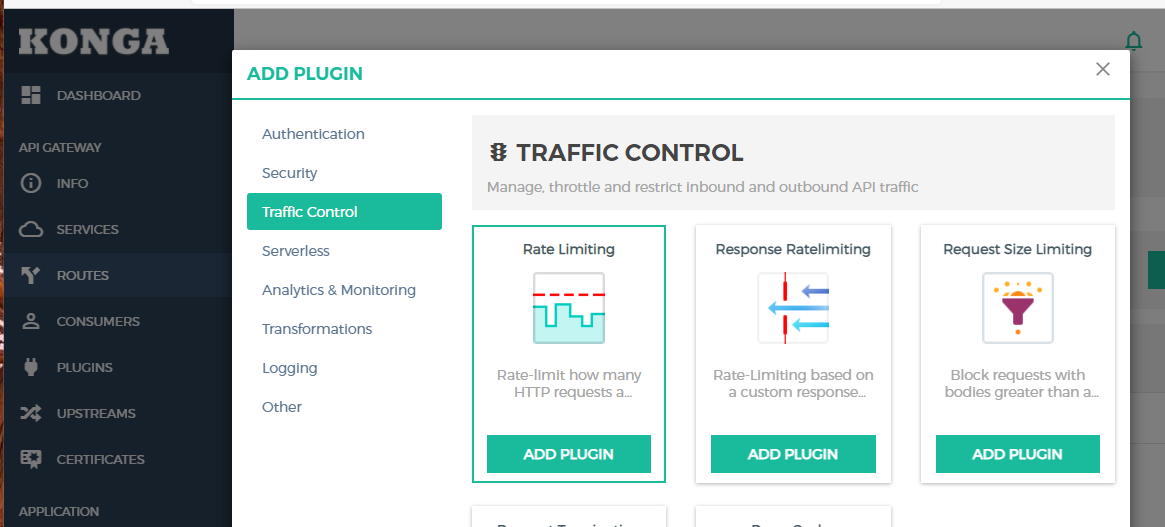
这里都秒,分钟,小时,天等单位,比如我们在minute里填写5,意为每分钟限制访问5次.然后保存
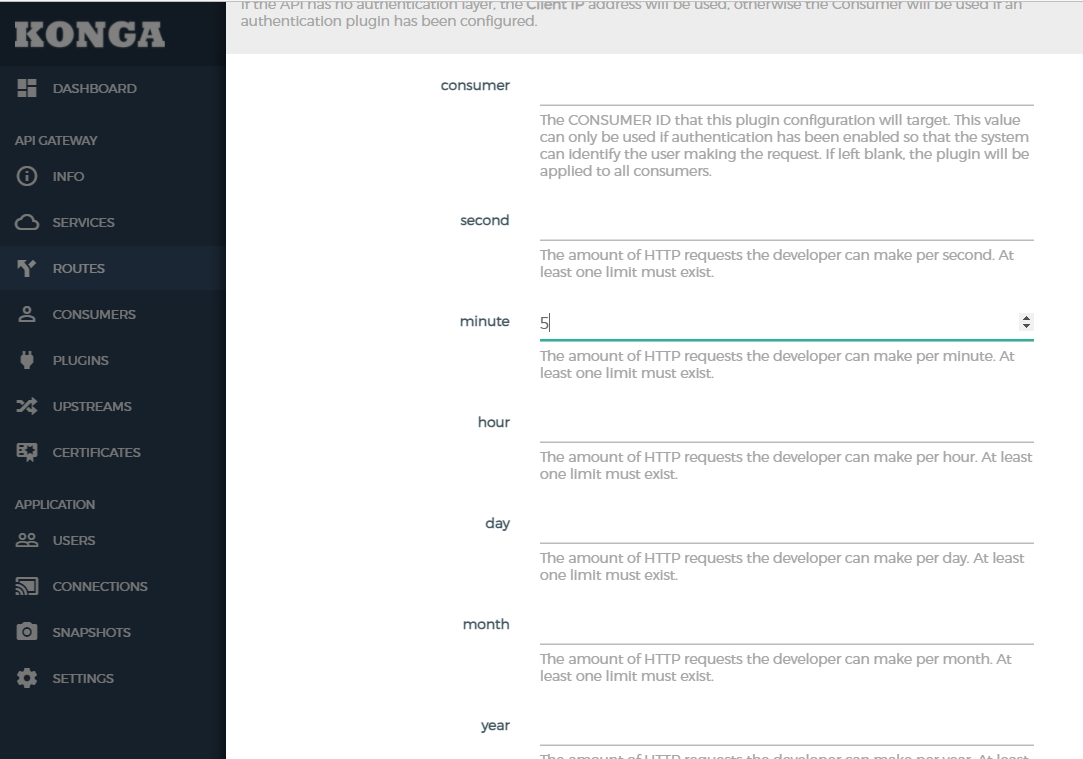
我们在浏览器中连续访问6次,会出现以下提示:
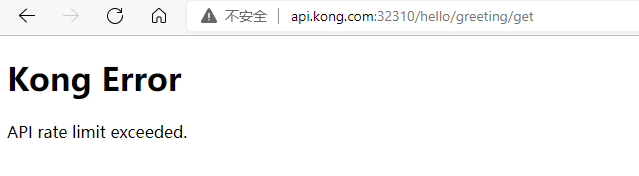
下面是限流插件的参数的具体说明
| 参数 | 说明 |
|---|---|
| consumer | 启用身份认证时,能够识别出消费者 |
| second/minute/hour/day/year | 多少次请求/秒/分钟/小时/天/年 |
| limit by | 统计维度,consumer, credential, ip, service,如果无法确定,将以IP为主 |
| policy | cluster:将计数器保存在数据库里,local:将计数器保存在本地,redsi:将计数器保存在redis里面 |
| fault tolerant | 第三方数据存储遇到问题时,如果为YES,在数据库恢复正常前,限流将会禁用,如果为 NO,将会报500错误 |
| redis host/port/password/timeout/database | 设置redis的相关信息 |
| hide client headers | 是否隐藏头信息 |
4. 应用层限流
应用层上面的限流方案,实际上有些并不符合在云原生架构上进行使用.由于我们的应用都是由Kubernetes保证了pod的可用性与伸缩性,并且屏蔽了物理底层的硬件资源,在pod中我们无法评估内存与CPU等资源,所以我们如果在应用层使用了限流,可能无法应用合适的阈值.
应用层上面AspNetCoreRateLimit是asp.netcore的限流组件,AspNetCoreRateLimit包含了两个Middleware
- IpRateLimitMiddleware,基于请求IP的限流
- ClientRateLimitMiddleware基于客户端Id方式的限流
每种方式都支持多个限流策略
AspNetCoreRateLimit支持内存级存储,同时也支持结合Redis进行使用.
IpRateLimitMiddleware使用方法
ClientRateLimitMiddleware使用方法
2. 降级
8. 服务度量
不管是传统单体架构还是服务化架构,对于应用的监控都是不可缺失的,监控让我们随时掌控系统的详细情况.借助于度量我们可以改进我们的应用系统.在asp.netcore中,一般有两种比较常见的方案,App.Metrics+Infulxdb与Prometheus.Net,这两种方案都可以结合Grafana用于可视化展示
1. prometheus-net
在Kubernetes快速入门章节中我们在集群中部署了Prometheus ,所以直接我们的应用程序可以集成相应的Exporters来实现监控度量,而prometheus-net是**.netcore**的实现客户
Prometheus支持 4 种 Metrics 类型,分别是Counter、Gauge、Histogram、Summary
- Counter: 计数器,是一个数值,该数值递增,应用启动后只增加不减少
- Gauge: 仪表,类似汽车的车速仪表盘,数值可增可减
- Histogram: 柱形图,其实是一组数据,主要用于统计数据分布的情况 —— 统计落在某些值的范围内的计数,同时也提供了所有值的总和和个数
- Summary: 摘要汇总,而也是一组数据,.
1. 默认指标
我们在hello.sh项目中,引用包prometheus-net.AspNetCore
实现起来也特别简单,只需要在Startup.cs中添加代码
endpoints.MapMetrics($"/{Controllers.AppInfo.ServiceName}/metrics");
运行起来后我们访问,http://localhost:5000/hello/metrics
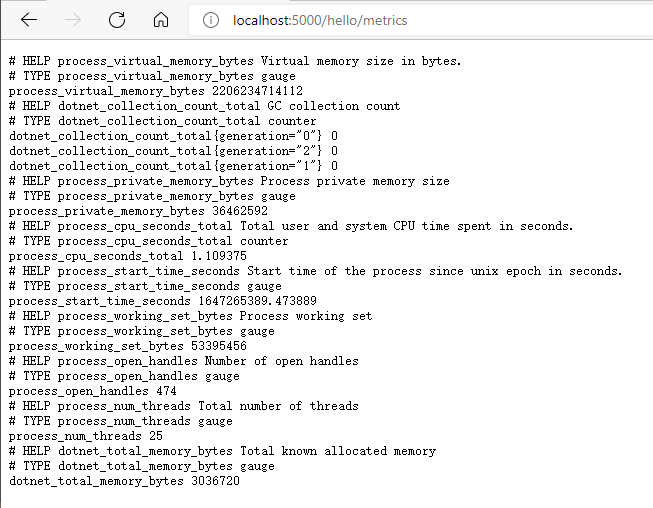
每个指标的意思如下
| metrics mame | Description | Get Method | Metric Type |
|---|---|---|---|
| dotnet_total_memory_bytes | GC 已分配的内存 | GC.GetTotalMemory(false) | Gauge |
| process_private_memory_bytes | 进程占用的私有物理内存 | process.PrivateMemorySize64 | Gauge |
| process_cpu_seconds_total | 进程使用的 CPU 时间 | process.TotalProcessorTime.TotalSeconds | Counter |
| dotnet_collection_count_total | GC回收每一代的次数 | GC.CollectionCount(gen) | Counter |
| process_num_threads | 线程数量 | process.Threads.Count | Gauge |
| process_working_set_bytes | 进程占用的物理内存 | process.WorkingSet64 | Gauge |
| process_open_handles | 进程打开的句柄数 | process.HandleCount | Gauge |
| process_virtual_memory_bytes | 进程占用的虚拟内存 | process.VirtualMemorySize64 | Gauge |
| process_start_time_seconds | 进程的启动时间 | (process.StartTime.ToUniversalTime() - epoch).TotalSeconds | Gauge |
2. 自定义指标
某些情况,默认监控指标无法满足我们的需求,我们可以利用这四个类型实现自定义的监控指标.
比如我们实现记录一个HTTP的总请求数
在解决方案里添加RequestTotalMiddleware.cs
public class RequestTotalMiddleware
{
readonly RequestDelegate _next;
//实例化计数器
static readonly Counter total_count = Metrics.CreateCounter("custome_http_request_total", "custome_http_request_total.");
public RequestTotalMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task InvokeAsync(HttpContext context)
{
//每次请求+1
total_count.Inc();
await _next(context);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在Startup.cs中添加该RequestTotalMiddleware,注意:RequestTotalMiddleware,需要在注册metrics路由之前.
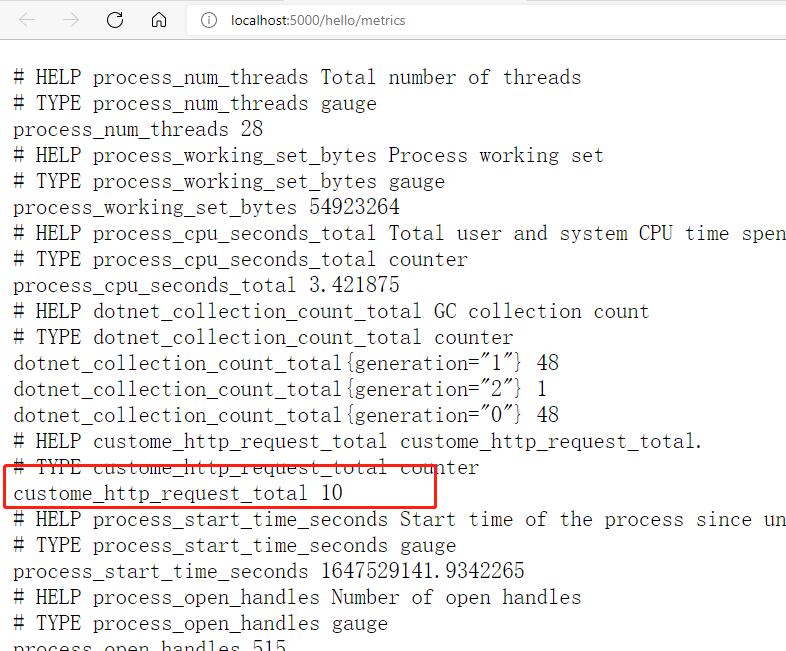
运行起来后我们访问,http://localhost:5000/hello/metrics,可以看到我们自定义的custome_http_request_total指标,已经出现
3. Prometheus
2. Grafana
3. 分布式缓存
合理的使用缓存,可以显著的提供应用的性能和伸缩性.缓存最适用于不经常更改且生成成本比较高的数据.
缓存一般分为进程内缓存与进程外缓存,在分布式架构中,应该禁止使用进程内存缓存,否则会有几率造成数据一致性的问题.使用进程外缓存主要有以下几点好处
1、所有 Web 服务器上的缓存数据都是一致的。(用户不会因处理其请求的 Web 服务器的不同而看到不同的结果。)
2、缓存的数据在 Web 服务器重新启动后和部署后仍然存在。 (删除或添加单独的 Web 服务器不会影响缓存。)
3、对数据库的请求变的更少 。
1. IDistributedCache 接口
IDistributedCache 由微软额外的包进行提供,我们需要在Nuget中引用Microsoft.Extensions.Caching.Redis包,我们看一下该接口的定义
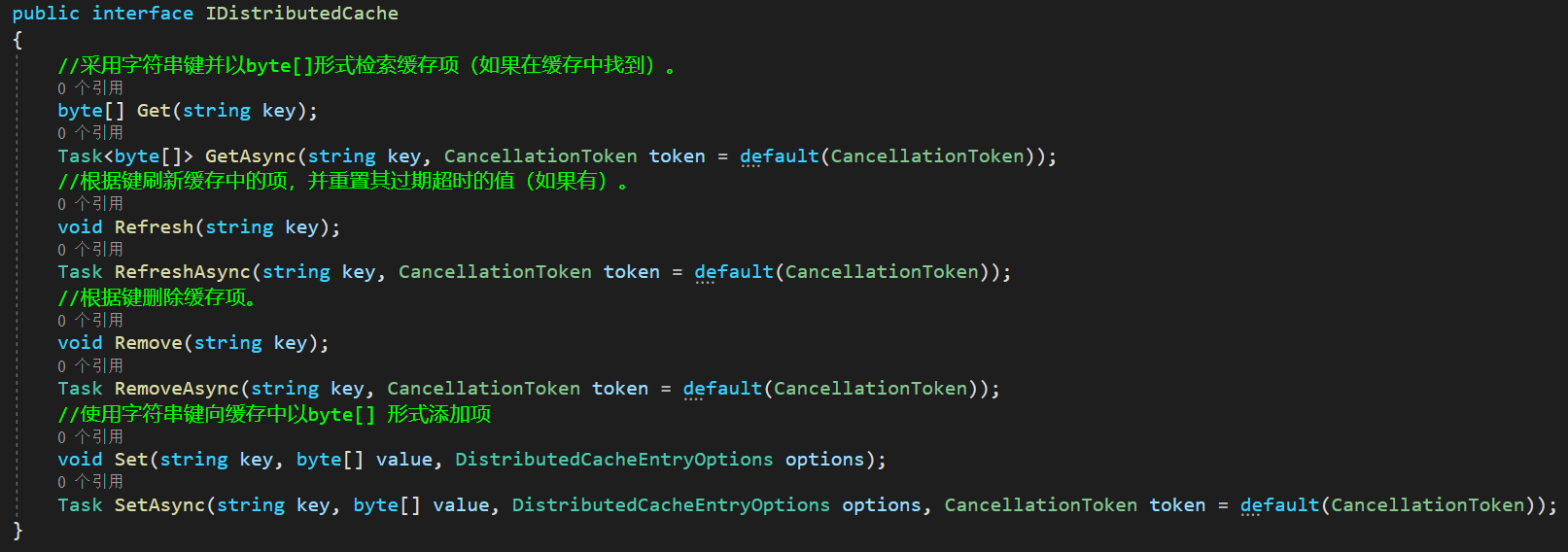
该接口访问Redis依赖于StackExchange.Redis
2. Redis
Redis是现在最受欢迎的NoSQL数据库之一,大多数场景都是被用来当做缓存使用.但是由于Redis的List数据结构的特性,有时也会被用来当做轻量型消息队列,
1. 集群方案
1. 主从
主从结构中包含一个master实例与一个或多个slave实例,slave也可以有slave节点,如下图架构
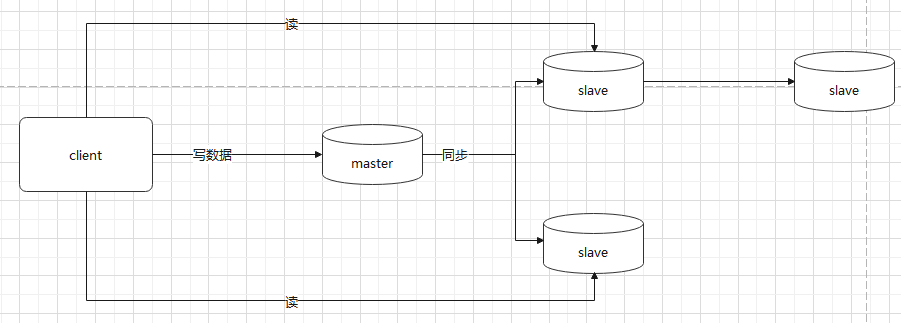
该架构可以说是Redis集群中的最简单的类型,那么这种架构的优缺点如下
优点:
- master自动将数据同步到slave,我们不需要关心数据同步,并且可以分担master的读的压力
- 结构部署比较简单,且客户端使用方式也比较简单.
缺点:
- 不具备高可用能力,如果节点宕机,需要手动恢复或者额外使用自动化脚本进行操作.
- 存储数据受限于master节点的容量上线,
2. Redis Sentinel
基于第一种的主从模式,引入了哨兵机制,哨兵顾名思义,就是为了监控集群的,一旦发现问题能做出相应的处理.比如:
- 检查master,slave是否正常运行
- 当master出现故障的时候,将slave提升为master.
- 多个哨兵可以监控同一个redis,哨兵之间也会互相监控
该方案的优缺点:
优点:
- 哨兵基于主从的,所以主从的优点.哨兵也有
- master节点故障后,可进行故障转移,提高系统的可用性
缺点:
- 无法在线扩容,存储容量受限于master节点
- 需要额外的哨兵进程,实现相对复杂.
哨兵模式解决了故障转移的问题,但是并没有达到真正意义上的高可用模式,下面另外一种集群方案,则完美的解决了这些问题
3. Redis Cluster
2. 集群部署
Redis部署的方式有两种: 1. 容器部署,2. 直接在服务器安装.由于我们服务器资源有限,所以使用容器化部署
接下来我们在cd这台服务器上部署Redis Cluster,
Docker部署Redis
1.下载镜像
[root@cd ~]# docker pull redis
Using default tag: latest
latest: Pulling from library/redis
a2abf6c4d29d: Pull complete
c7a4e4382001: Pull complete
4044b9ba67c9: Pull complete
c8388a79482f: Pull complete
413c8bb60be2: Pull complete
1abfd3011519: Pull complete
Digest: sha256:db485f2e245b5b3329fdc7eff4eb00f913e09d8feb9ca720788059fdc2ed8339
Status: Downloaded newer image for redis:latest
docker.io/library/redis:latest
2
3
4
5
6
7
8
9
10
11
12
2.部署镜像
[root@cd ~]# docker run -itd --restart=always -p 6379:6379 redis
007e8e9a43a0f50c87f94a1e2ec5040e763d3ebabc249f75959172e556d4ae9d
2
4. 分布式锁
1. 原理
锁可以解决资源争抢问题,可以适用于秒杀,消减库存等场景问题,在以往单体应用时代,我们可以使用进程内存锁来限制资源争抢问题,通常最简单的实现方式就是使用lock关键字
public class demo
{
static object o =new object();
public static void lock_resource(){
lock(o){
//do something
}
}
}
2
3
4
5
6
7
8
9
10
那么在多副本(pod)这种自动伸缩的情况下,这种锁显然会出现各种问题,所以在Kubernetes集群中应该绝对禁止使用这种内存级锁,应该使用分布式锁.
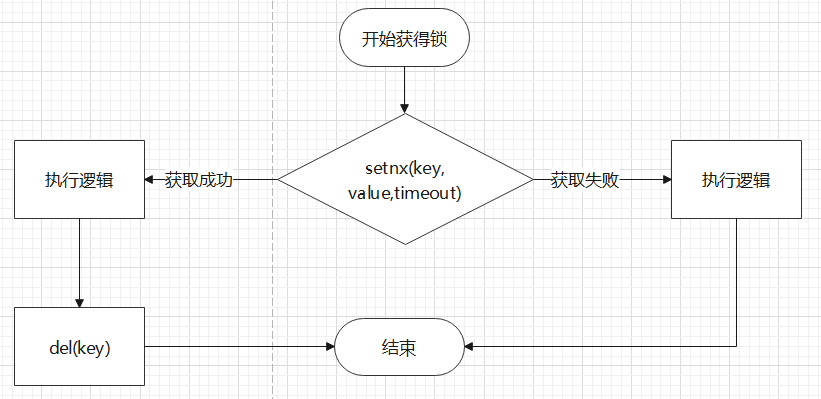
Redis中有个命令SETNX key value,SETNX意为SET if not exists,如果不存在则进行Set.CSRedisCore驱动库已经内置了分布式锁,基于这个库我们可以很简便的实现分布式锁.
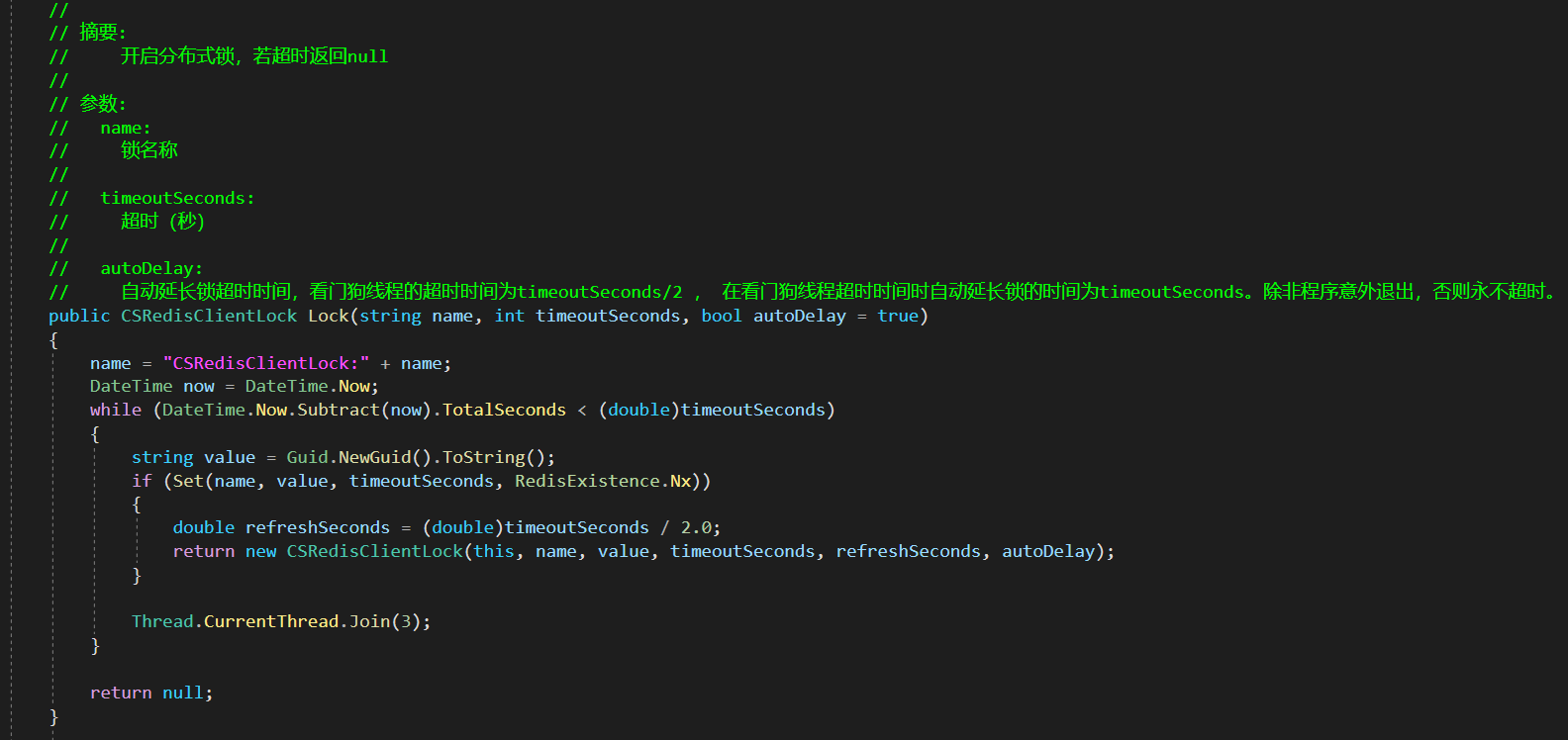
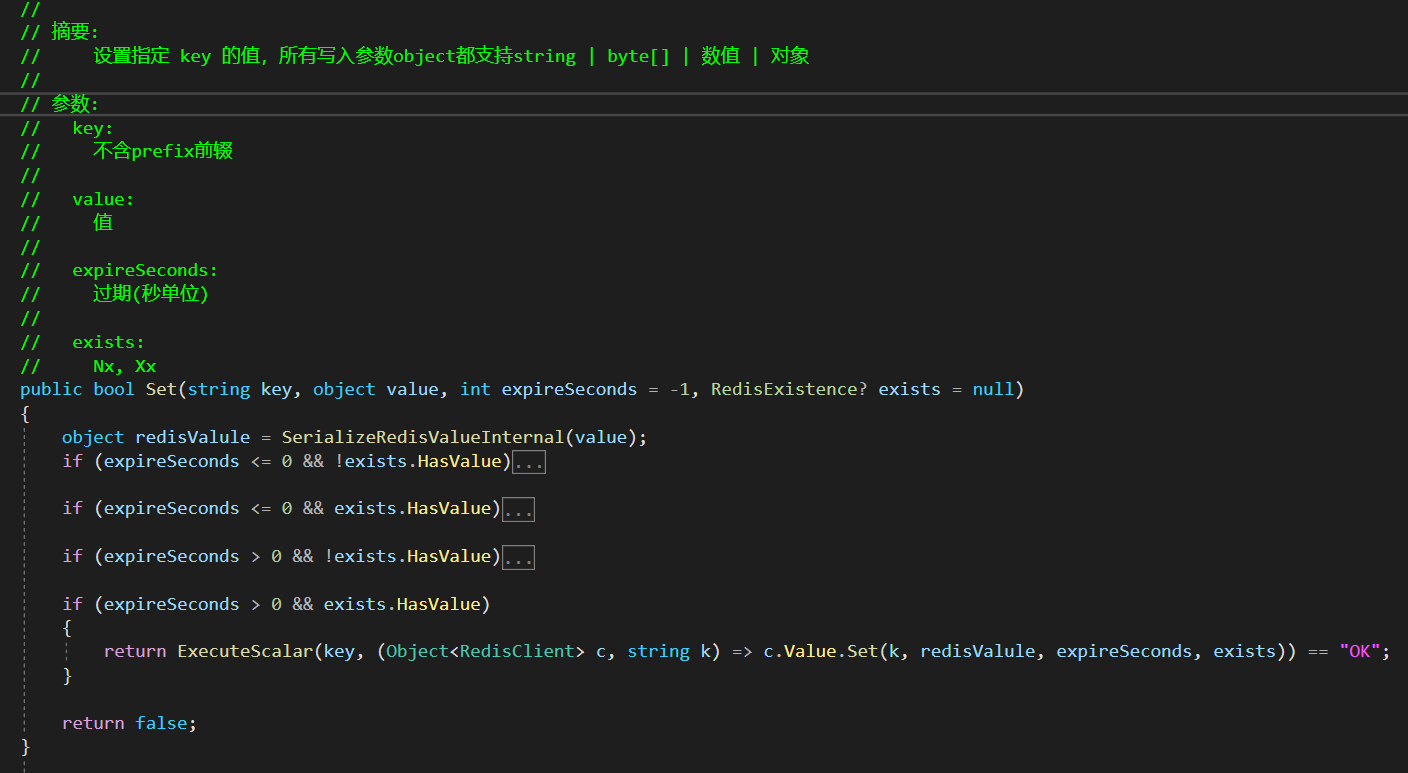
根据CSRedisCore内部实现逻辑:
- 通过setnx获得锁
- 如果key不存在,就存入一个key,并设置expire.
- 如果key存在,则使用**Thread.CurrentThread.Join(3)**来阻塞线程,直到达到超时时间
- key存入成功以后,执行业务,业务执行完以后,利用using与IDisposable释放锁
- key存入失败后,返回存错.
所以整体业务实现逻辑如下
在代码实现上
public class demo
{
static object o = new object();
static string key = "key1";
static int timeout = 5;
public static void lock_resource()
{
using (var o = RedisHelper.Instance.Lock(key, 5, false))
{
if(o == null){
throw new Exception("锁定超时");
}else{
//do something
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2. 实战
根据以上的demo代码,我们来实现分布式锁.
首先创建解决方案ristributed-lock,并引用CSRedisCore包,示例代码如下
internal class Program
{
static void Main(string[] args)
{
RedisHelper.Initialization(new CSRedisClient("cd:6379"));
for (int i = 0; i < 10; i++)
{
var s = i;
Task.Run(() =>
{
sync_lock(s);
});
}
Console.Read();
}
static void sync_lock(int i)
{
//超时设置为5秒
using var o = RedisHelper.Lock("test_lock_name", 5, false);
if (o == null)
{
Console.WriteLine($"{i}超时,没有获得锁");
}
else
{
Console.WriteLine($"{i}获得锁");
//暂停10秒
Task.Delay(10000).Wait();
o.Unlock();
Console.WriteLine($"{i}释放得锁");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
本代码示例发起10个线程去争抢锁test_lock_name,按照我们的预期只有1个线程能抢到锁,其余9个线程应该争抢失败.我们运行看下效果

可以看到7抢到了锁,其他线程都超时,然后7释放了锁.接下来我们更改超时时间参数,
static void sync_lock(int i)
{
//将超时时间设置为15秒
using var o = RedisHelper.Lock("test_lock_name", 15, false);
if (o == null)
{
Console.WriteLine($"{i}超时,没有获得锁");
}
else
{
Console.WriteLine($"{i}获得锁");
Task.Delay(10000).Wait();
o.Unlock();
Console.WriteLine($"{i}释放得锁");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
根据代码,预期为将有两个线程抢到锁,其他线程为超时.运行起来看效果

可以看到,最早7抢到了锁,然后经过10秒,7释放了锁,接着2抢到了锁,这时其他线程已经到看超时时间,所以未抢到,最终2释放了锁.
5. 消息队列
消息队列(Message Queue),是分布式系统中重要的组件,消息队列主要解决了应用耦合,异步处理,流量削峰等问题,当前使用比较多的消息队列有:RabbiqMQ,RocketMQ,ActiveMQ,Kafka等,在Redis 5.0以上的版本中也增加了对消息队列的支持,也就是RedisStream.每个消息队列都有自己的特点,在本书中,我们只选择一个消息队列来演示.
1. RabbitMQ
RabbitMQ是一个开源的AMQP实现,服务端由Erlang语言编写,支持多种客户端.并且还带有Web控制台.
Docker部署RabbitMQ
在Docker官方镜像仓库中,有两个版本的RabbitMQ镜像,一个是带有Web控制台,一个是不带有Web控制台的.在此我们选择带有Web控制台的版本
1. 部署镜像
[root@cd ~]# docker run -d -p 15672:15672 -p 5672:5672 rabbitmq:management
2. Web控制台
- 访问控制台http://cd:15672/,用户名与密码均为guest,能够访问该地址,说明已经部署成功
3. 消息确认
6. 数据库
在互联网技术体系中,通常我们对数据库进行选型的时候,不同的角色所倾向的指标是不一样的.
数据选型基本就是两种方案,商业数据库与开源数据库,代表型:
- 商业数据库:Microsoft MS SQL Server
- 开源数据库:Oracle My SQL、开源PostgreSQL
我们选择什么样的数据库,意味着选择的生态也不同.本文我们主要以MySQL为主
1. 读写分离
在大型系统中,数据库主从是最常用的一种数据架构,我们可以用主从架构来实现应用的读写分离.不同的主从架构也会影响到我们应用层架构.在实践中,会有多种不同形式的主从结构
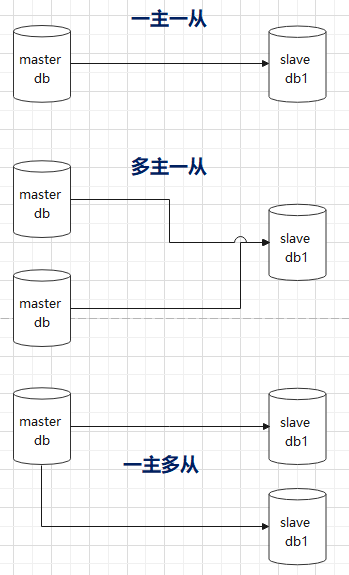
不同主从架构面向不同的应用场景
1. 应用架构一
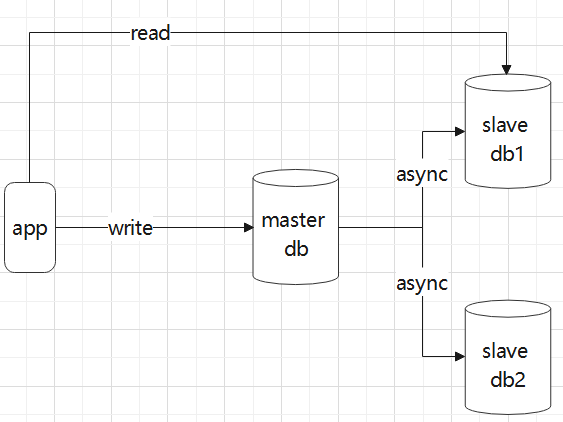
在该架构中,我们的应用层中维护了多个数据库链接,当如果是读操作的时候,则使用读连接,如果是写,则使用写连接.这种架构的优劣势如下:
优点:
- 架构简单,应用层维护连接池
- 性能优,由于是直连数据库,所以从性能来说,是最优的
缺点:
- 无法进行有效负载,由于由应用层连接池,所以每个实例的负载由应用层决定
- 应用层需要自行判断读写操作
2. 应用架构二
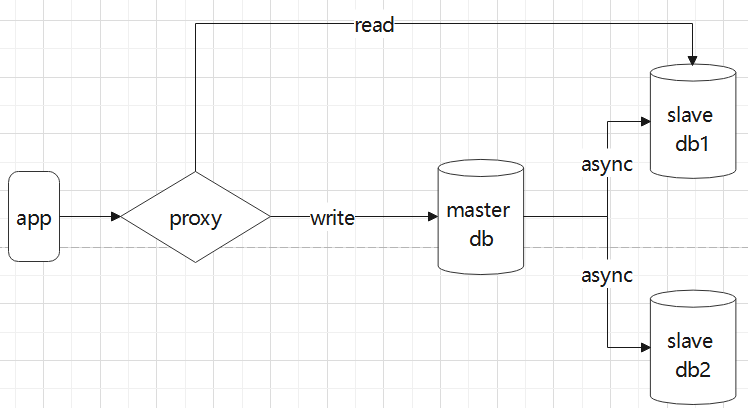
在该架构中,我们在数据库前引入了一个中间件proxy,我们的应用层连接proxy,proxy负责将我们的SQL路由到主节点还是从节点.这种架构的优缺点如下:
优点:
- proxy内部都会使用负载算法,数据库负载比较均衡,
- 应用层只需要维护一个proxy的连接即可
缺点:
- 应用层在使用select..into等这样的语法,取决于proxy是否支持
- 额外引入proxy组件,则组件的单点可靠性额外进行保证
2. 数据同步
数据同步一直是大型系统中必不可少的功能,也是各家数据库自带的基本能力,接下来我们分别介绍基于MySQL自带的数据同步技术以及第三方组件实现的数据同步
1. bin_log
bin_log是一个二进制格式的文件,MySQL会将对数据库的更新的SQL语句记录在该文件里,但是查询语句不会记录。所以不管是MySQL自身的同步,还是第三方的同步组件,都是需要借助该文件来实现同步能力。
首先,我们需要开启bin_log功能,首先查看我们的数据库实例是否开启bin_log功能
show variables like 'log_bin';
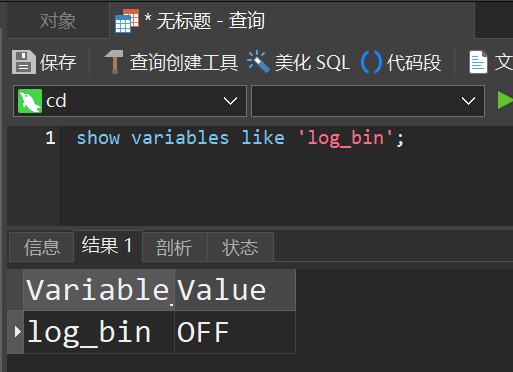
OFF:关闭.ON:启用
我们的My SQL容器挂载的配置目录是
/usr/local/docker/mysql/conf
所以我们在该目录中创建my.cnf文件,
vi /usr/local/docker/mysql/conf/my.cnf
[mysqld]
#binlog格式,需要指定为row
binlog_format = row
#存放地址,注意这个地址是docker容器里面的地址,不是宿主机里面的地址
log-bin=/var/lib/mysql/mysql-bin
server-id=123654
#存放时间
expire_logs_days=30
#最大文件大小
max_binlog_size=50m
#缓存大小
binlog_cache_size=10m
#最大缓存大小
max_binlog_cache_size=512m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
然后重启容器
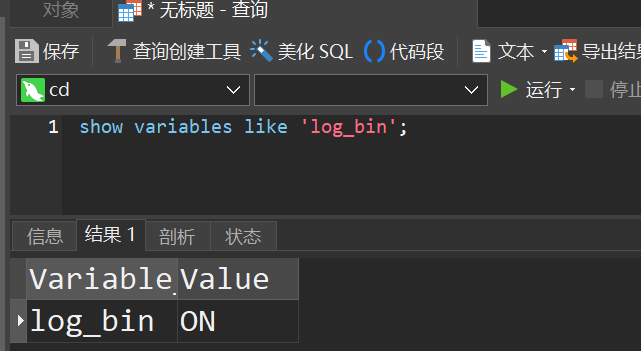
可以看到,已经成为ON,接下来我们利用CloudCanal来实现数据同步
1. CloudCanal
虽然MySQL本身支持主从结构,但是配置麻烦,切不灵活,所以我们介绍一下更灵活的方案来实现,那就是CloudCanal
CloudCanal是一款数据迁移同步工具,帮助企业快速构建高质量数据流通通道,产品包含 SaaS 模式和私有输出专享模式。开发团队核心成员来自大厂,具备数据库内核、大规模分布式系统、云产品构建背景,懂数据库,懂分布式,懂云产品商业和服务模式。
CloudCanal有以下四个版本,具体区别可查看官方网站
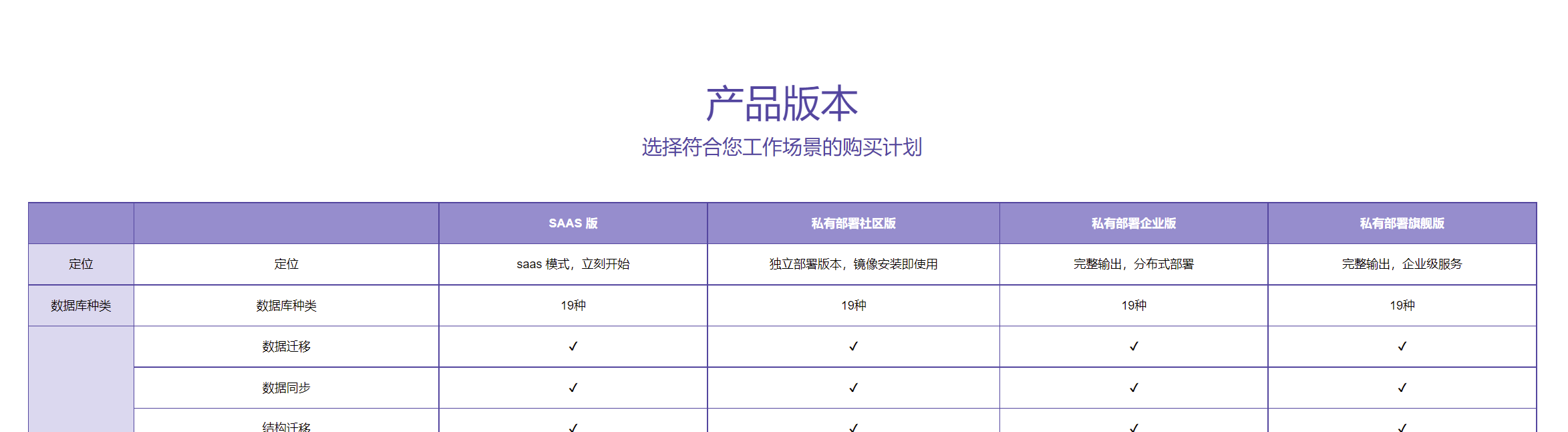
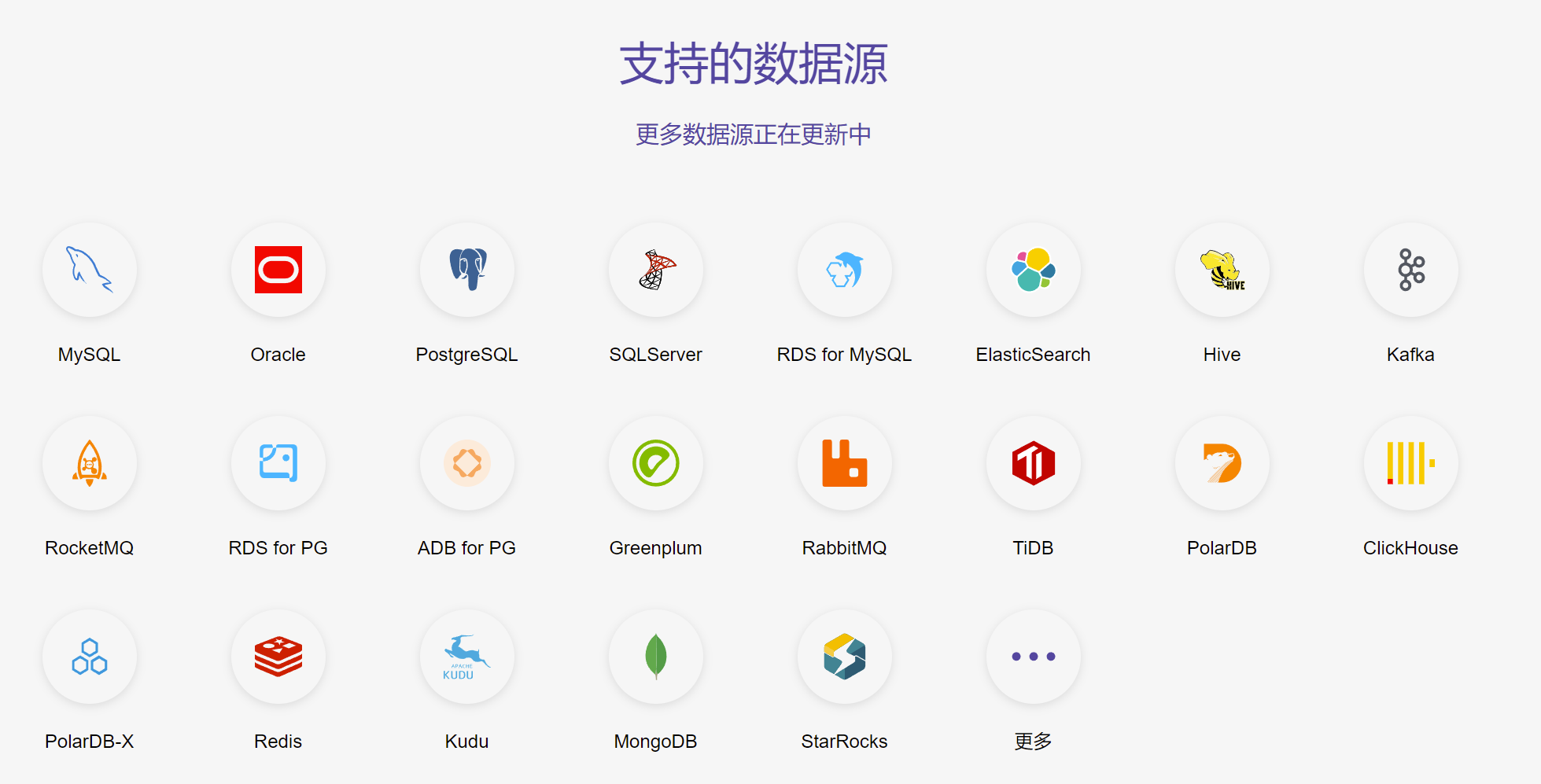
CloudCanal 支持以下数据源,可见比canal多一些
那么CloudCanal与canal有啥区别呢?可以看下图
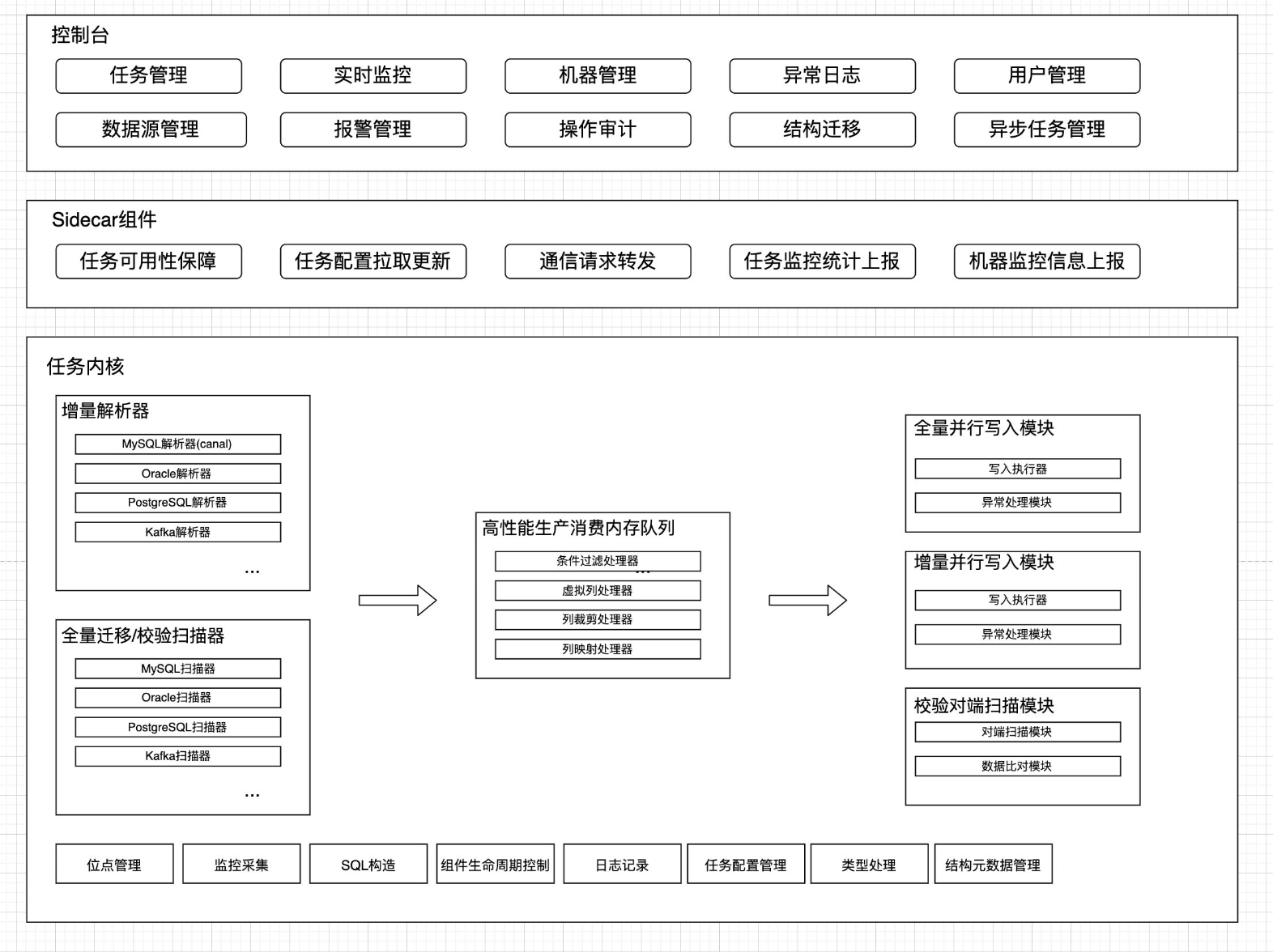
CloudCanal 在 MySQL binlog 解析使用了 Canal 部分代码,其他均为自主研发,并且对 Canal 部分代码进行了大量重构,修复诸多问题并优化性能。Canal 在 CloudCanal 中的位置,可以用以下图片简单表示,可见 Canal 代码在 CloudCanal 产品中只占很小一部分。
CloudCanal目前尚未开源.
1. 安装
我们在cd这台服务器上安装
- 下载安装文件
https://cloudcanal-community.oss-cn-hangzhou.aliyuncs.com/latest/cloudcanal.7z
- 解压,进入目录
,目录包含以下文件
镜像:包含四个 tar 压缩文件
脚本:启动、更新和停止,以及 scripts 运维脚本目录
日志与配置文件:日志为 docker-compose 启动日志,配置文件为 docker-compose 配置文件
2. 启动
在目录中执行启动命令
sh startup.sh
[root@cd cloudcanal]# sh startup.sh
...
...
cloudcanal is starting...
Creating volume "cloudcanal_cloudcanal_console_volume" with default driver
Creating volume "cloudcanal_cloudcanal_sidecar_volume" with default driver
Creating cloudcanal-mysql ... done
Creating cloudcanal-console ... done
Creating cloudcanal-sidecar ... done
Creating cloudcanal-prometheus ... done
Waiting for console to start
...
Waiting for console to start
...
cloudcanal-console start!!!
cloudcanal-sidecar start!!!
cloudcanal start!!!
And console_data and sidecar_data are two symbolic links for console and sidecar volumes.
Now please visit http://{您部署机器的ip}:8111 in explorer.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这时我们访问http://cd:8111
- 如遇需要发送短信的场景,先点击获取验证码,然后输入短信验证码 777777 即可
- 试用用户
- test@clougence.com
- 试用密码
- clougence2021
3. 使用
使用CloudCanal主要有以下几个步骤
- 先创建数据源,源与目标
- 创建同步任务
为了体验CloudCanal的强大,本次示例我们是将MySQL中的数据同步到MS SQL Server
创建数据源
在数据源管理中,我们新增加一个数据源
- 我们将cd服务器上的MySQL实例添加为数据源
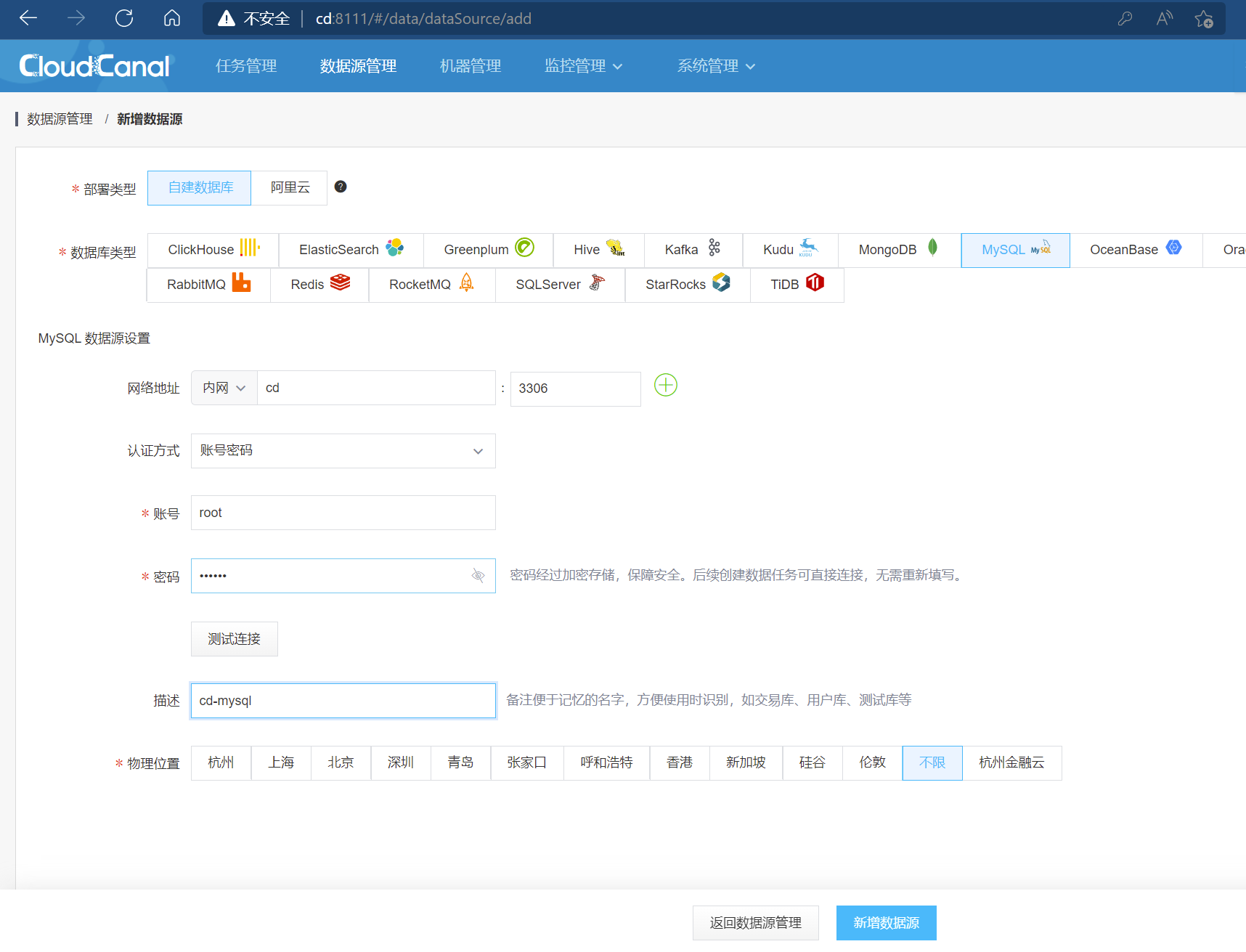
2 .部署MS SQL Server容器
[root@cd cloudcanal]# docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=123456aA@" -p 1433:1433 -d mcr.microsoft.com/mssql/server
72c5ea5fd5bf42a6b44652681b5f5718205fc07e0be7f25518bca5cda0700071
2
创建MS SQL Server的数据源
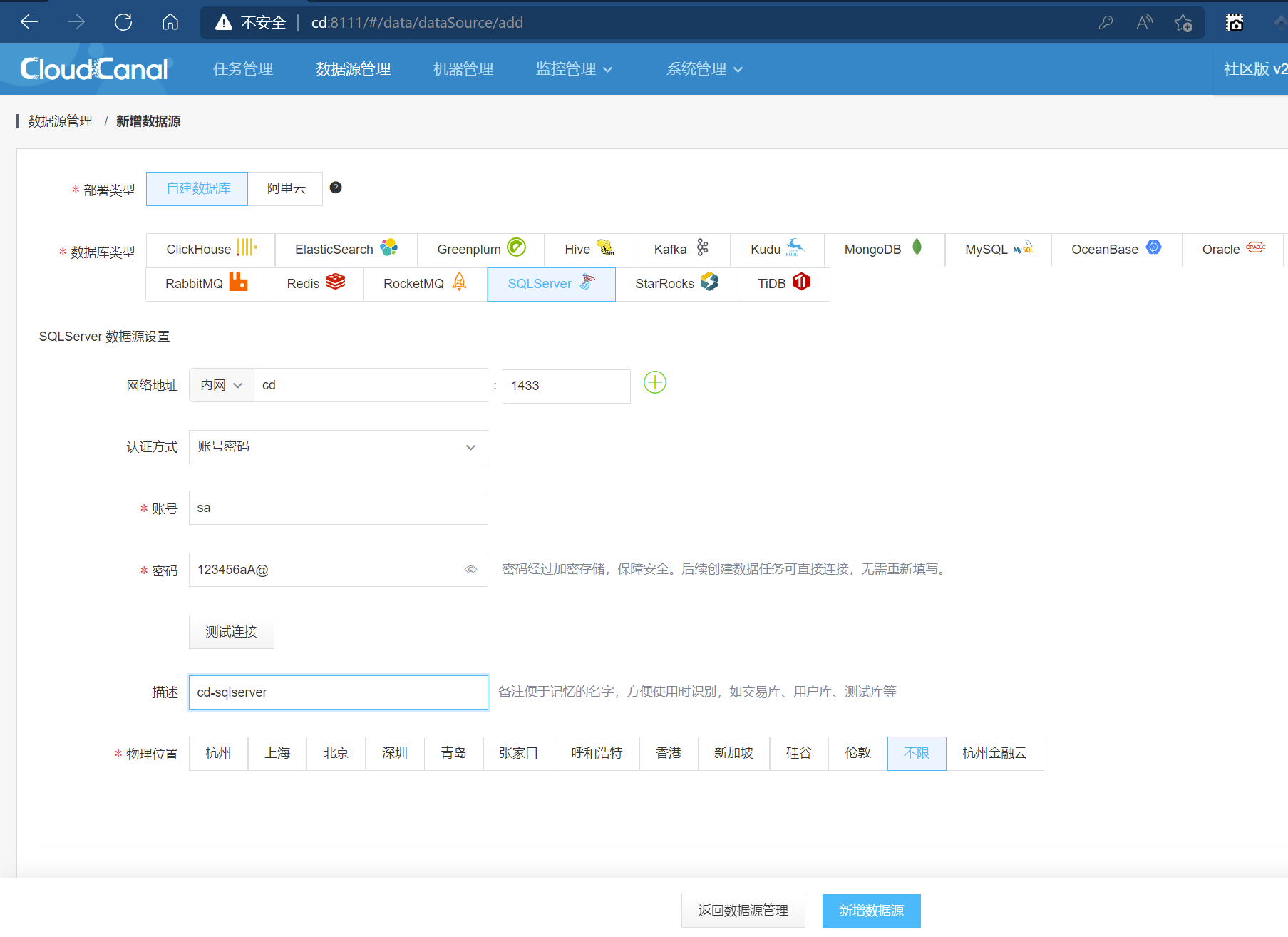
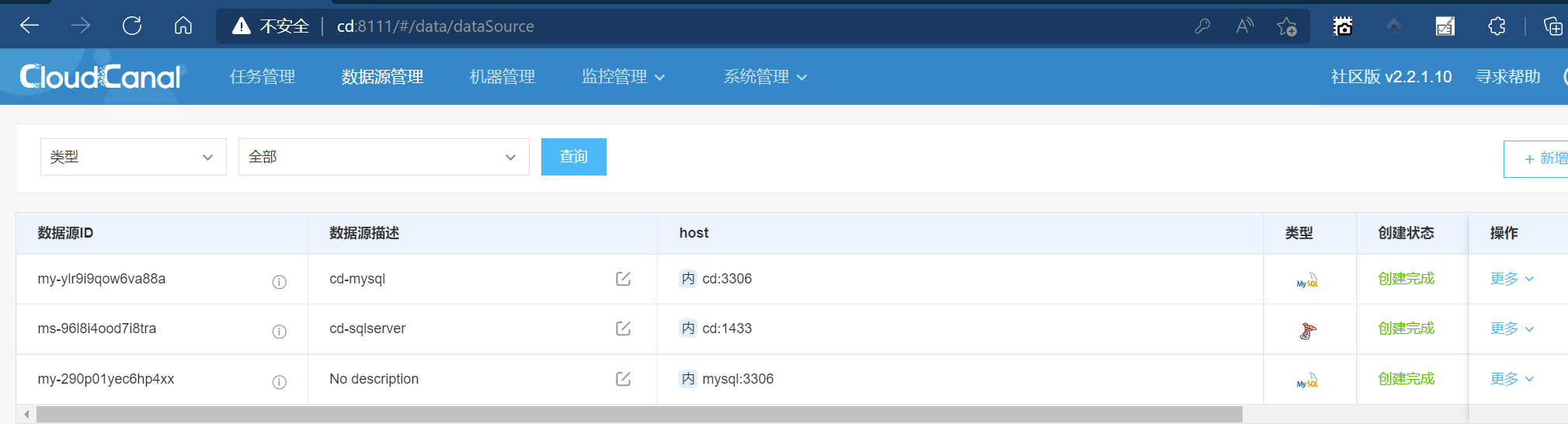
最终如下
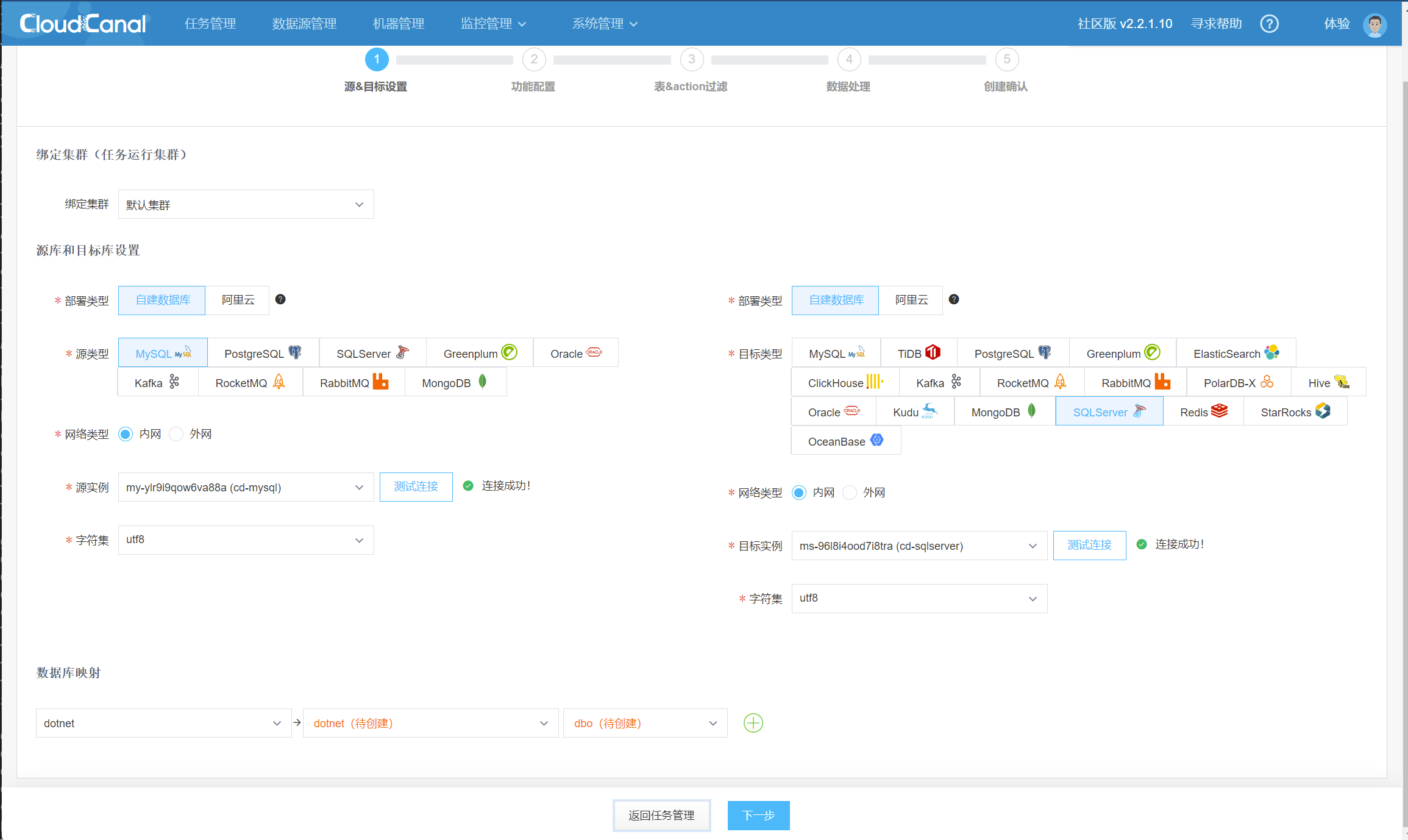
3 创建同步任务
首先在MySQL实例中创建一个数据库名为dotnet.字符集utf8并随便创建一个表
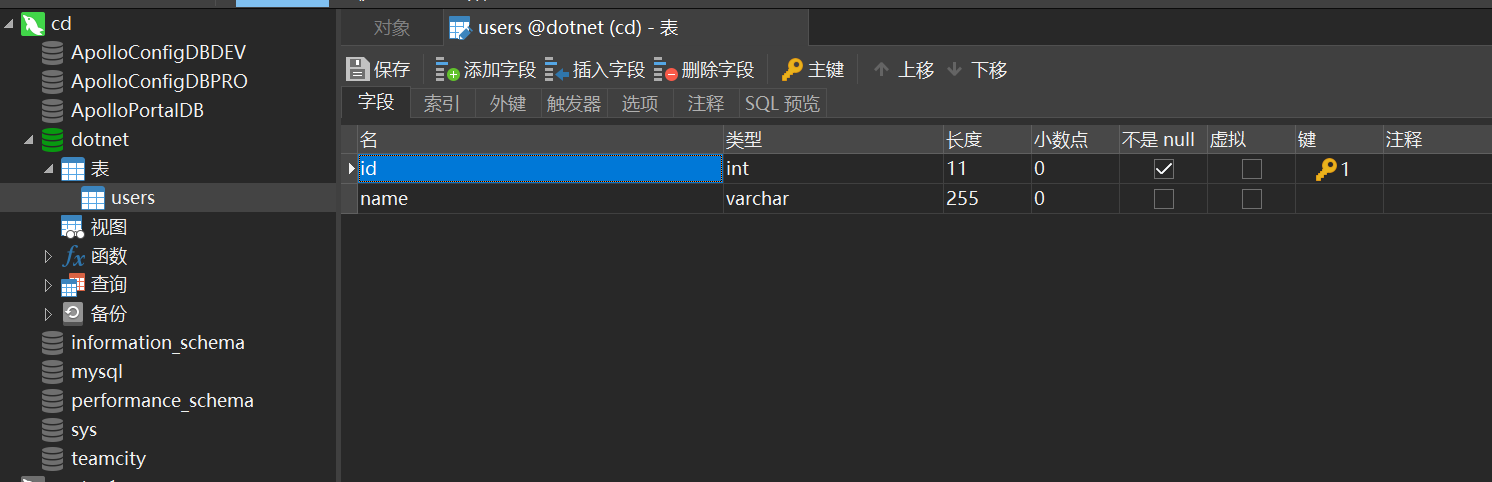
在任务管理中,我添加同步任务
然后下一步
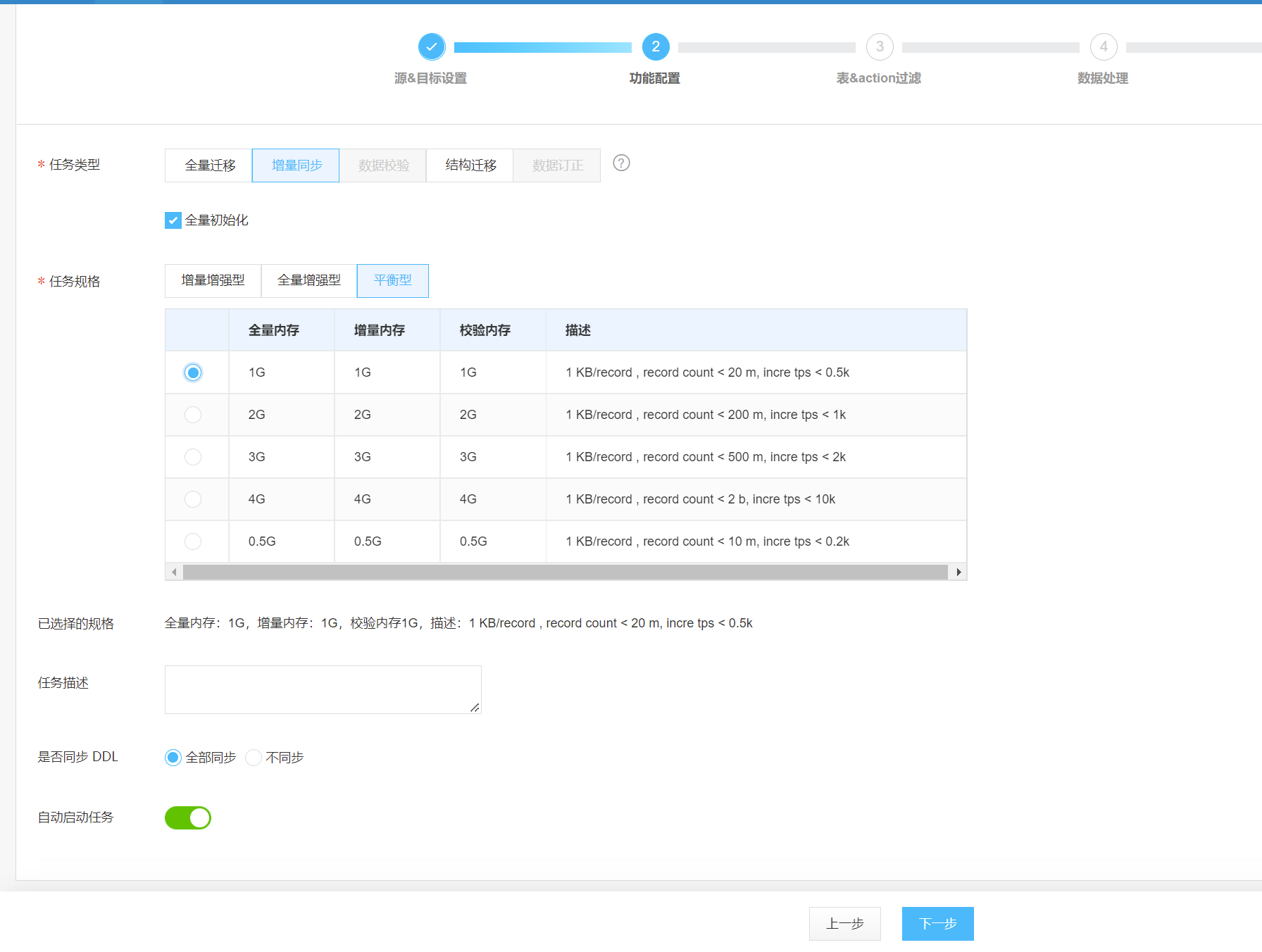
这里根据同步的数据大小,我们选择相应的配置.注意应保持物理机内存
然后一直下一步,最终创建任务即可.因为没有数据同步,所以状态为异常
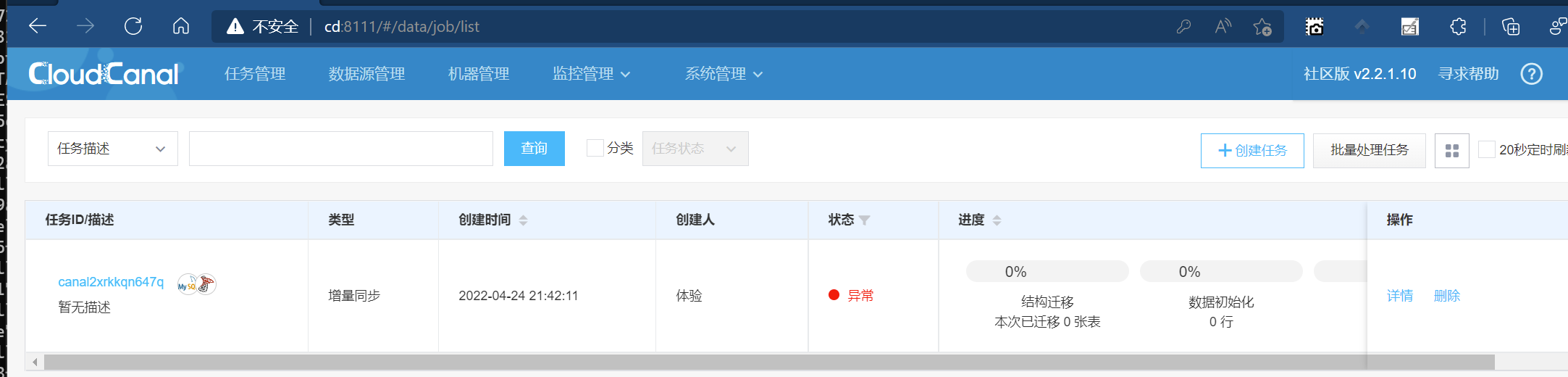
然后我们在MySQL实例中,向users表中增加一条数据
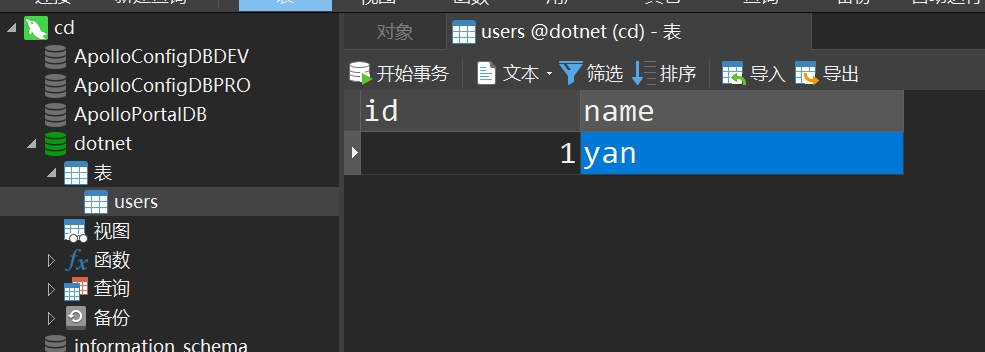
刷新CloudCanal页面,可以看到状态已经成为正常
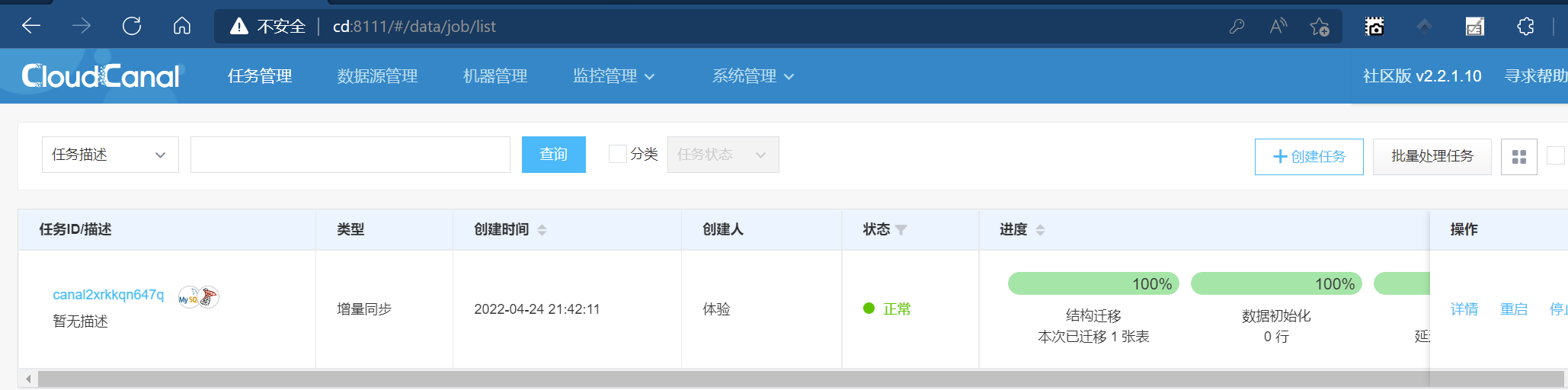
在回到MS SQL Server实例来查看,是否同步过来
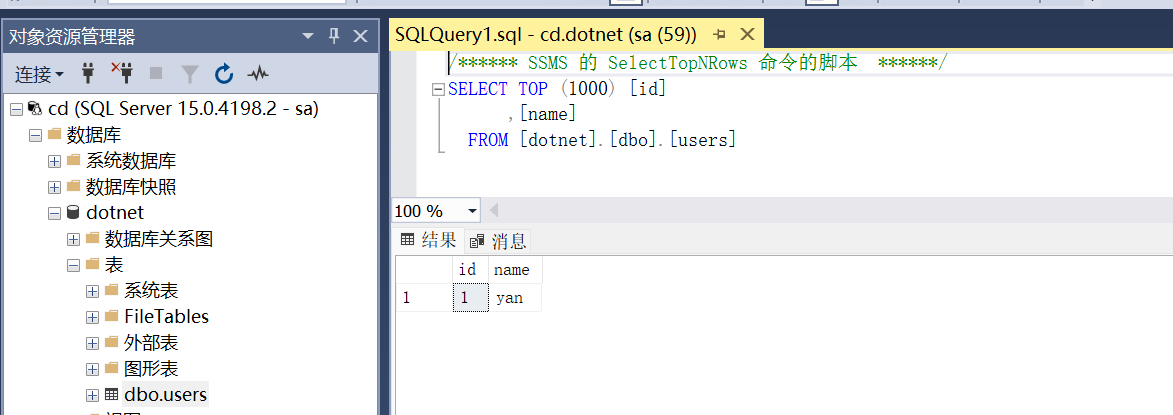
可以看到表结构与数据都已经同步过来了,这就是CloudCanal的强大之处
3. 应用层读写分离
在前面我们探讨了两种读写分离的应用层架构,接下来我们来看如果基于架构二应用层中我们如何实现
1. Mycat
Mycat是一款数据库中间件,由Java编写的MySQL数据库网络协议的开源中间件
4. OLAP
在真实场景中,我们会有大部分基于数据分析的需求,通常我们会写各种复杂的SQL.并且受限于MySQL B+树的索引结构,通常单表能够支持到2千万左右数据.所以对于大型实时在线分析的业务,可能受限于性能需求
针对这样的在线实时分析的场景我们需要引入额外的数据库来实现.
1. Clickhouse
ClickHouse是由俄罗斯yandex公司开发,一个用于联机分析(OLAP)的列式数据库管理系统(DBMS).其设计是专用于OLAP业务,但无法支持OLTP业务

Clickhouse主要有以下特点
- 可支持PB级超大容量的数据库管理系统
- 基于SQL语句, 使用成本低
- 超亿级数据量分析的秒级响应,计算性能横向扩展
- 海量数据即查即用.提供数据的预聚合能力,进一步提升数据查询的效率
- 列式存储, 数据压缩,降低磁盘IO和网络IO,提升计算性能,节约70%物理存储
- 支持副本, 实现跨机房的数据容灾
Clickhouse主要有以下短板
- 不支持事务
- 近实时性
- 不适用于单点查询(如类似where id =1)
- 保证最终一致性,而非强一致性,这与OLAP业务有关系
1. 安装
部署clickhouse容器,注意该命令没有挂在存储卷
docker run -d --name ch-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 yandex/clickhouse-server
查看容器,然后我们进入到容器
[root@cd cloudcanal]# docker run -d --name ch-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 yandex/clickhouse-server
a95103fa6d21025391b26476dae73d2e354acf14f79a17d99c7ddcf4c893788d
2
clickhouse容器是一个依赖包不完整的 ubuntu 虚拟机,所以我们需要进入到容器内部,安装 vim,
[root@cd]# docker exec -it a95103fa6d21 bash
在容器内部执行以下两个命令
apt-get update
apt-get install vim -y
2
编辑文件: /etc/clickhouse-server/users.xml
root@a95103fa6d21:/# vim /etc/clickhouse-server/users.xml
在68行,我们更改自己需要的密码.此处使用的是明文密码
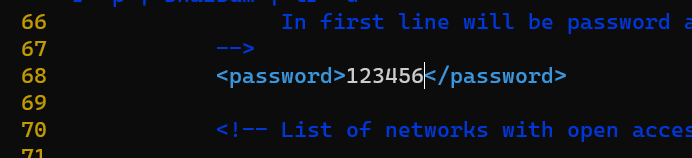
不用重启容器,支持已经安装完毕,接下来我们使用Clickhouse
2. 连接工具
连接工具可以使用官方在线管理工具:ClickHouse Query,也可以使用本地管理工具.
我们下载一个多数据库管理工具DBeaver,下载地址:https://dbeaver.io/.然后在Dbeaver创建一个Clickhouse连接,默认用户名为default,密码就是刚刚我们创建的123456
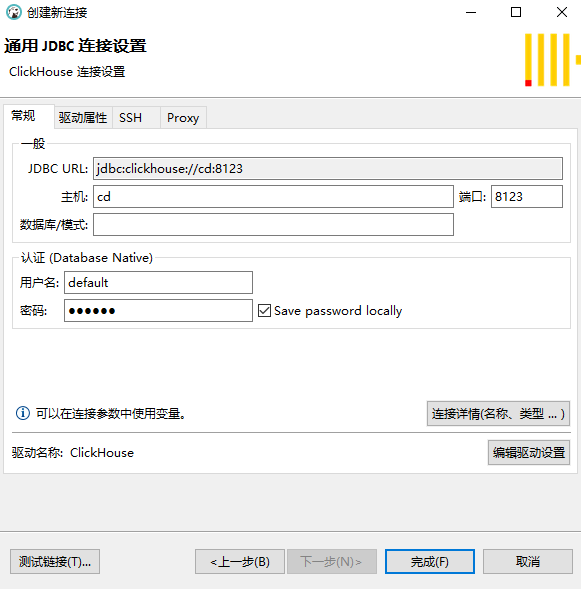
连接成功以后
3. 高级特性
库引擎
大家都知道My SQL支持多种数据存储引擎,不同的存储引擎面向不同的使用场景,同样的,在Clickhouse中也会存在不同的存储引擎.
Clickhouse的数据引擎大致分为两种类型:
- Atomic,Clickhouse默认引擎
- 其他类型,Clickhouse可以集成其他数据库实例,如常用的MySQL/PostgreSQL,然后将查询请求转发到该实例上.
Atomic
我们创建一个测试数据库:mytest
CREATE database mytest
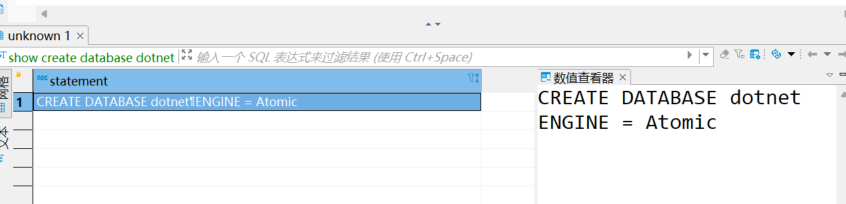
然后查询该测试数据库
show create database mytest

可以看到 ENGINE = Atomic
其他类型
Clickhouse还可以集成其他数据库引擎,比如常用的MySQL/PostgreSQL等
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
CREATE DATABASE test_database
ENGINE = PostgreSQL('host:port', 'database', 'user', 'password'[, `use_table_cache`]);
2
3
4
5
Clickhouse仅支持insert与select语句,将请求转发到相应的后端数据库实例上.所以使用场景还是相当有限
表引擎
物化视图
在关系型数据库中存在视图概念,视图屏蔽了复杂的SQL查询,
4. 数据同步
接下来我就利用CloudCanal将MySQL实例中的数据库dotnet同步到Clickhouse.
首选在CloudCanal中添加一个Clickhouse的数据源

然后我们创建一个同步任务将MySQL同步到Clickhouse
一直下一步,然后保存
然后,我们在MySQL中的数据库dotnet中的users表添加一条数据
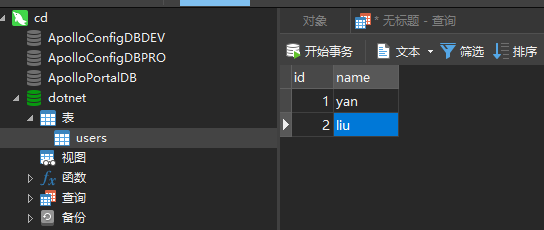
然后查看Clickhouse,可以看到数据库结构和数据都已经同步过来了
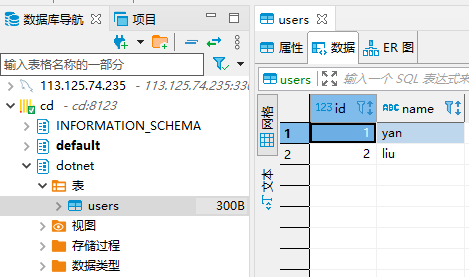
并且数据库引擎为Atomic
5. dotnet使用Clickhouse
Clickhouse支持两种连接协议
原生协议,端口是9000,
对应nuget包:ClickHouse.Ado
HTTP协议,端口是8123
对应nuget包:ClickHouse.Client与EntityFrameworkCore.ClickHouse
EntityFrameworkCore.ClickHouse内部依赖于ClickHouse.Client,截至本文EntityFrameworkCore.ClickHouse还没有支持Migration功能
新建一个项目Clickhoust.Test,类型为控制台即可,我们将演示两种方式的使用
- 基于原生SQL
- 基于ORM的EntityFrameworkCore.ClickHouse
引入以下两个包

定义实体
[Table("users")]
public class User
{
[Key]
public int id { get; set; }
[StringLength(50)]
public string name { get; set; }
}
2
3
4
5
6
7
8
9
定义ClickHouseDbContext
public class ClickHouseDbContext : DbContext
{
public ClickHouseDbContext()
{
}
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseClickHouse("Host=cd;Port=8123;Database=dotnet;user=default;password=123456");
base.OnConfiguring(optionsBuilder);
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
}
public DbSet<User> users { get; set; }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
在Program中的代码
using (var db = new ClickHouseDbContext())
{
foreach (var item in db.users.ToArray())
Console.WriteLine(item.name);
}
Console.WriteLine("------------");
using (var conection = new ClickHouseConnection("Host=cd;Port=9000;User=default;Password=123456;Database=dotnet;"))
{
conection.Open();
var cmd = conection.CreateCommand("select * from users");
var reader = cmd.ExecuteReader();
reader.ReadAll(row => Console.WriteLine(row["name"]));
conection.Close();
}
Console.ReadLine();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
运行看一下效果

5. 搜索
6. HTAP
7. .NET大数据
大数据领域一直都是JAVA的天下,其他语言很难有竞争对手,
1. Apache Spark
2. .NET for Apache Spark
8. 分布式事务
在以往中小型项目中大多情况一个数据库即可满足需求.那么在大型单体应用中,往往也会存在多个数据库,也会存在对数据一致性的要求,在服务化机构下更是如此
1. 事务
事务由一条或者多条SQL语句组成,在这个单元中,每个SQL语句相互依赖,而整个单元作为不可分割的整体,如果一条SQL语句执行失败,整个单元进行全部回滚,所有受到影响的数据都会回到事务开始前的状态.如果单元中所有SQL语句均执行成功,则事务被顺利执行
1. ACID
事务具有以下特性:
- 原子性(Atomicity): 事务不可分割,要么都执行,要么都不执行
- 一致性(Consistency): 事务的执行会使数据从一个一致状态切换到另一个一致状态
- 隔离性(Isolation): 事务的执行不会收到其他事物的影响
- 持久性(Durability): 事务一旦提交,则会永远改变数据库的数据
2. 隔离级别
事务在并发执行时通常根据隔离级别不同会有以下问题
- 脏读: A事务对数据进行了增删改,但未提交,有可能回滚,B事务却读取了未提交的数据
- 不可重复读: A事务在执行过程中需要多次读取同一数据,B事务对数据作了更新并提交,导致A事务多次读取同一数据时,结果不一致
- 幻读: A事务在执行时,先查出一批记录,结果B事务向这批记录中插入一条数据,A事务在查询时,将该条数据也读了出来
| MS SQL Server | My SQL | 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|---|
| ✓ | ✓ | 读未提交(READ UNCOMMITTED) | ✓ | ✓ | ✓ |
| ✓ | ✓ | 读已提交(READ UNCOMMITTED) | ✓ | ✓ | |
| ✓ | ✓ | 可重复读(REPEATABLE READ) | ✓ | ||
| ✓ | ✓ | 串行化(SERIALIZABLE) | |||
| ✓ | 快照(SNAPSHOT) | ||||
| ✓ | 读已提交快照(READ COMMITTED SNAPSHOT) | ✓ | ✓ |
MS SQL Server额外支持另种以下级别
SNAPSHOT: 在读取数据时,它是确保获得事务启动时最近提交的可用行版。
READ COMMITTED SNPSHOT: 在读取语句启动时(不是事务启动时),可用的最后提交的行版本.
2. CAP定理
CAP定理,又称布鲁尔定理,对于设计分布式系统(不仅仅是分布式事务)来说,CAP是入门理论知识,该理论告诉我们,一个分布式系统不可能同时满足一致性(Consistency),可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能同时满足其中的2个.
- C: 对于数据分布在不同节点上数据来说,如果某个节点更新了数据,那么其他节点也能读取到这个最新的数据,那么成为强一致性,如果某个节点没有读取到,则出现不数据一致
- A: 保证每个请求不管成功或者失败都有响应.
- P: 当出现网络问题后,系统能够继续工作.如集群中有多套机器,其中某台机器宕机,但是这个集群仍然可以正常工作
3. BASE理论
BASE由三个短语的缩写:
- BA: Basically Available基本可用.系统出现故障时,允许损失部分的可用功能,保障核心功能的使用
- S: Soft State软状态,这个指的是允许系统存在一个中间状态,这个状态不影响系统的可用性,指的CPA中的不一致
- E: Eventually Consistent最终一致,最终数据是一致的就可以了,而不是时刻保持强一致性
BASE理论与ACID是相反的,不同于ACID的强一致性, 而是通过牺牲掉强一致性来获得可用性,并允许数据在一段时间内是不一致的,通过处理手段,能达到最终一致的状态
4. 实现方案
分布式事务实现方案有两种类型
- 基于数据库的解决方案
- 基于应用程序的解决方案
1. 强一致性
常用的关系型数据库MS SQL Server和My SQL都支持分布式事务,该方案可借助数据库能力实现数据强一致性,所以该方案性能不高,也只适用于并发量不高的情况下.
dotnet开发人员都知道TransactionScope这个类,这是我们实现分布式事务的基础,借助该类,我们可实现跨实例的分布式事务.使用起来也非常简单,代码使用如下:
static void test_MySql()
{
try
{
using (var transactionScope = new TransactionScope())
{
using var conn = new MySqlConnection("");
conn.Open();
conn.Execute("sql command");
using var conn2 = new MySqlConnection("");
conn2.Open();
conn2.Execute("sql command");
transactionScope.Complete();
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
TransactionScope需要显示调用**transactionScope.Complete()**方法,否则事务不会提交.
目前My SQL在.netcore里有两个驱动
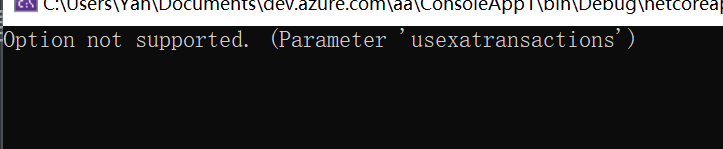
- MySql.Data: 官方驱动,不支持TransactionScope分布式事务
- MySqlConnector: 第三方驱动,该驱动支持TransactionScope分布式事务.
MySql.Data使用TransactionScope时会出现以下错误
2. 最终一致性
由于数据库分布式方案实现的是强一致性,具有显著的缺点,无法应用在高并发场景中,所以我们需要在应用层来实现最终一致性
1. 本地消息表
本地消息表方案是基于消息补偿的方案,主要是基于支持事务的消息列队和本地消息表来实现.主要流程如下
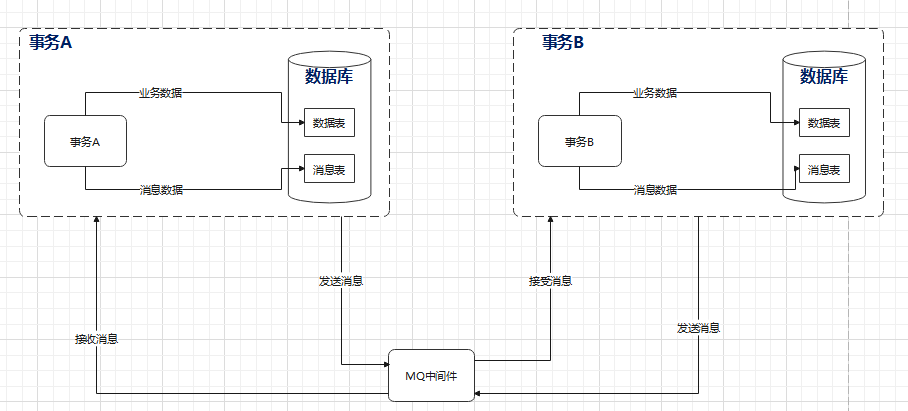
可以看到,消息的处理与业务处理是在同一个事务中,以保证消息数据与业务数据的一致性,当然其中必要的容错,比如发送消息失败,或者消费消息失败等,可能需要加入消息的重试机制.
本方案的优点方案轻量级,容易理解与实现,可借助框架实现屏蔽底层的具体MQ中间件.
DotNetCore.CAP是一个开源分布式事务框架的组件,遵循.NET Standard 标准库的C#库,可以用来处理分布式事务以及提供EventBus的功能,该组件可支持多种消息队列中间件,屏蔽了底层消息队列中间件的复杂性,借助该组件,我们可以实现本地消息表的分布式事务解决方案
DotNetCore.CAP使用起来也非常简单,我们来看一下官方demo,
public class PublishController : Controller
{
private readonly ICapPublisher _capBus;
public PublishController(ICapPublisher capPublisher){
_capBus = capPublisher;
}
[Route("~/adonet/transaction")]
public IActionResult AdonetWithTransaction(){
using (var connection = new MySqlConnection(ConnectionString))
{
using (var transaction = connection.BeginTransaction(_capBus, autoCommit: true))
{
//your business logic code
_capBus.Publish("xxx.services.show.time", DateTime.Now);
}
}
return Ok();
}
[Route("~/ef/transaction")]
public IActionResult EntityFrameworkWithTransaction([FromServices]AppDbContext dbContext){
using (var trans = dbContext.Database.BeginTransaction(_capBus, autoCommit: true))
{
//your business logic code
_capBus.Publish("xxx.services.show.time", DateTime.Now);
}
return Ok();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
可以看到消息与本地事务是集成到一起的,从DotNetCore.CAP源码中,可以看到,DotNetCore.CAP会自行判断,当前是否有关联本地事务
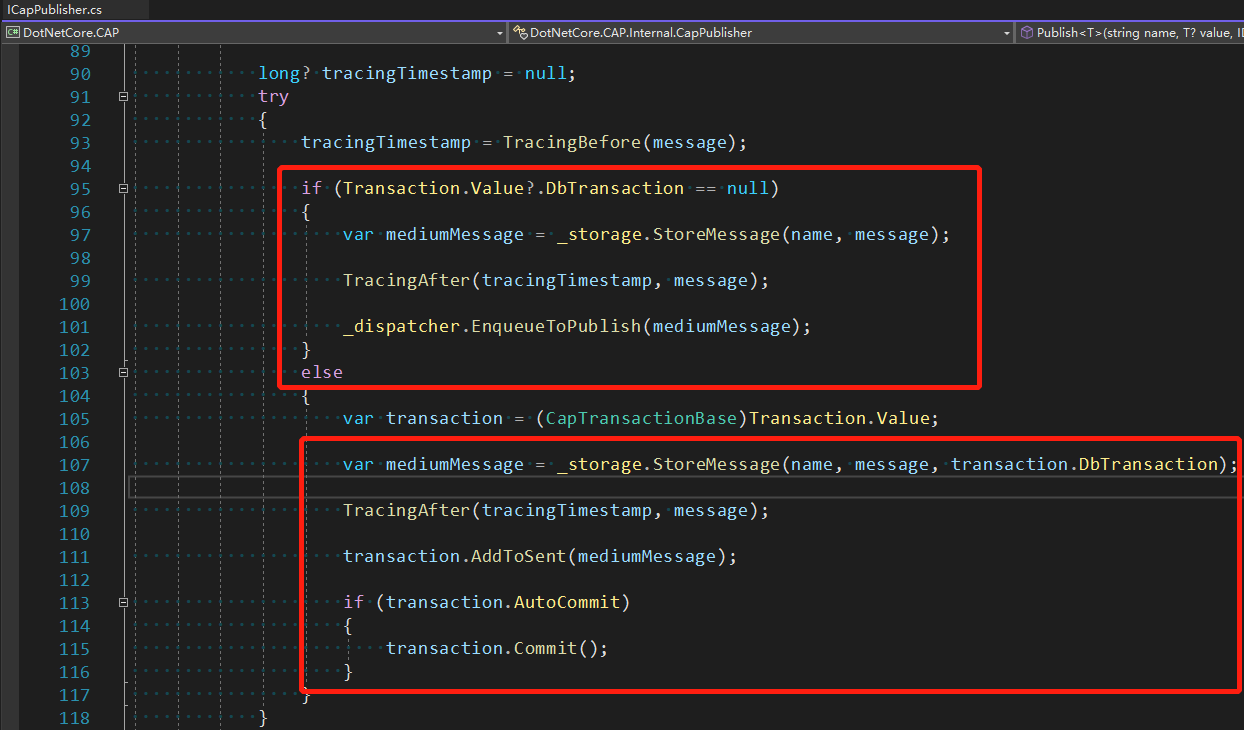
此为DotNetCore.CAP还会自动实现消息的重试,消费频率等,具体可以查看官方文档,https://cap.dotnetcore.xyz/user-guide/zh/cap/configuration/
2. TCC
TCC是 Try、Confirm、Cancel 三个词语的缩写
- Try 准备阶段,尝试执行业务
- Confirm 完成业务
- Cancel 回滚准备阶段的业务
3. Saga
9. 分布式定时任务
在.NET Core2.0及后续的版本中,提供了IHostedService与BackgroundService,BackgroundService继承自IHostedService.通过该类,我们可以实现某些需要循环执行的任务操作.比如我们每秒输出一次时间.
public class TimeHostService : BackgroundService
{
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
while (!stoppingToken.IsCancellationRequested)
{
Console.WriteLine(DateTime.Now);
await Task.Delay(1000);
}
}
}
2
3
4
5
6
7
8
9
10
11
然后在Startup.cs中注册该服务
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddHostedService<TimeHostService>();
}
2
3
4
5
以往单体应用时代,这种用法本身没有什么问题,但是如果我们的应用程序做了负载均衡,部署了多个实例,那么则会出现什么现象? 对,每个实例都会运行这个定时任务,如果这个任务执行者关键动作,则会引发比较严重的问题.那么我们将该应用程序部署到Kubernetes中,将会出现一模一样的问题
1. Hangfire
Hangfire是一个在 .NET 和 .NET Core 应用程序中执行后台处理的组件。无需 Windows 服务或单独的进程。由持久性存储提供支持。开放且免费用于商业用途。并且内部提供一个WebUI,可以看到任务执行情况
Hangfire内部通过锁的机制来控制任务并发执行,在多个实例副本的情况下,同一个任务在同一时刻,只会由一个副本执行
Hangfire免费版支持四种后台任务
- 队列任务,Hangfire将任务放进队列,依次执行,该类型的任务只会执行1次.
var jobId = BackgroundJob.Enqueue(
() => Console.WriteLine("Fire-and-forget!"));
2
- 延迟任务,在指定时间以后执行任务,该任务只会执行1次
var jobId = BackgroundJob.Schedule(
() => Console.WriteLine("Delayed!"),
TimeSpan.FromDays(7));
2
3
- 循环任务,
RecurringJob.AddOrUpdate(
"myrecurringjob",
() => Console.WriteLine("Recurring!"),
Cron.Daily);
2
3
4
- 延续任务,在指定任务完成后,执行另一个任务
BackgroundJob.ContinueJobWith(
jobId,
() => Console.WriteLine("Continuation!"));
2
3
1. Web
在控制台下使用Hangfire是很简单,如以下代码,Hangfire会自行创建相关表
项目引用以下两个包:
- Hangfire
- Hangfire.MySqlStorage
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
services.AddHangfire(x => x.UseStorage(new MySqlStorage("Data Source=cd;port=3306;Database=dotnet;User ID=root;Password=123456;", new MySqlStorageOptions())));
services.AddHangfireServer();
}
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
RecurringJob.AddOrUpdate("myrecurringjob", () => Console.WriteLine($"Recurring!:{DateTime.Now}"), Cron.Minutely);
app.UseHangfireDashboard();
}
2
3
4
5
6
7
8
9
10
11
2. 控制台
在控制台下使用Hangfire是很简单,如以下代码,Hangfire会自行创建相关表
项目引用以下两个包:
- Hangfire
- Hangfire.MySqlStorage
using Hangfire;
using Hangfire.MySql;
GlobalConfiguration.Configuration.UseStorage(new MySqlStorage("Data Source=cd;port=3306;Database=dotnet;User ID=root;Password=123456;", new MySqlStorageOptions()));
using (var server = new BackgroundJobServer())
{
Console.WriteLine("Hangfire Server started. Press any key to exit...");
RecurringJob.AddOrUpdate("myrecurringjob", () => Console.WriteLine($"Recurring!:{DateTime.Now}"), Cron.Minutely);
Console.ReadKey();
}
2
3
4
5
6
7
8
9
10
2. Apache Dolphin Scheduler
3. Kubernetes CronJob
在Kubernetes快速入门的章节,我们介绍到,CronJob控制器,该控制器也可以实现定时任务
10. 日志系统
在以往的系统架构中,日志系统有很多种选型,比如常用的写入数据库,或者NLog写入本地文件.在Kubernetes中通常我们使用的方案是EFK
- Elasticsearch 是一个搜索引擎,主要负责存储日志并提供查询接口
- Fluentd 负责从集群中采集日志,使用DaemonSet控制器将pod部署到每一个node节点上,然后收集节点的系统日志,然后发送给Elasticsearch.
- Kibana 提供了一个Web界面,我们可以来浏览和搜索Elasticsearch中的日志.
整体部署结构如下